合 大数据之Spark面试题
- 一、Spark 基础
- 1. 激动人心的 Spark 发展史
- 2. Spark 为什么会流行
- 3. Spark VS Hadoop
- 3. Spark 特点
- 4. Spark 运行模式
- 二、Spark Core
- 1. RDD 详解
- 1) 为什么要有 RDD?
- 2) RDD 是什么?
- 3) RDD 主要属性
- 2. RDD-API
- 1) RDD 的创建方式
- 2) RDD 的算子分类
- 3) Transformation 转换算子
- 4) Action 动作算子
- 4) RDD 算子练习
- 3. RDD 的持久化/缓存
- 持久化/缓存 API 详解
- 4. RDD 容错机制 Checkpoint
- 5. RDD 依赖关系
- 1) 宽窄依赖
- 2) 为什么要设计宽窄依赖
- 6. DAG 的生成和划分 Stage
- 1) DAG 介绍
- 2) DAG 划分 Stage
- 7. RDD 累加器和广播变量
- 1) 累加器
- 2) 广播变量
- 三、Spark SQL
- 1. 数据分析方式
- 1) 命令式
- 2) SQL
- 3) 总结
- 2. SparkSQL 前世今生
- 1) 发展历史
- 3. Hive 和 SparkSQL
- 4. 数据分类和 SparkSQL 适用场景
- 1) 结构化数据
- 2) 半结构化数据
- 3) 总结
- 5. Spark SQL 数据抽象
- 1) DataFrame
- 2) DataSet
- 3) RDD、DataFrame、DataSet 的区别
- 4) 总结
- 6. Spark SQL 应用
- 1) 创建 DataFrame/DataSet
- 2) 两种查询风格:DSL 和 SQL
- 3) Spark SQL 完成 WordCount
- 4) Spark SQL 多数据源交互
- 四、Spark Streaming
- 1. 整体流程
- 2. 数据抽象
- 3. DStream 相关操作
- 1) Transformations
- 2) Output/Action
- 4. Spark Streaming 完成实时需求
- 1) WordCount
- 2) updateStateByKey
- 3) reduceByKeyAndWindow
- 五、Structured Streaming
- 1. API
- 2. 核心思想
- 3. 应用场景
- 4. Structured Streaming 实战
- 1) 读取 Socket 数据
- 2) 读取目录下文本数据
- 3) 计算操作
- 4) 输出
- 六、Spark 的两种核心 Shuffle
- Spark Shuffle
- 一、Hash Shuffle 解析
- 1. HashShuffleManager
- 2. 优化的 HashShuffleManager
- 基于 Hash 的 Shuffle 机制的优缺点
- 二、SortShuffle 解析
- 1. 普通运行机制
- 2. bypass 运行机制
- 3. Tungsten Sort Shuffle 运行机制
- 基于 Sort 的 Shuffle 机制的优缺点
- 七、Spark 底层执行原理
- Spark 运行流程
- 1. 从代码角度看 DAG 图的构建
- 2. 将 DAG 划分为 Stage 核心算法
- 3. 将 DAG 划分为 Stage 剖析
- 4. 提交 Stages
- 5. 监控 Job、Task、Executor
- 6. 获取任务执行结果
- 7. 任务调度总体诠释
- Spark 运行架构特点
- 1. Executor 进程专属
- 2. 支持多种资源管理器
- 3. Job 提交就近原则
- 4. 移动程序而非移动数据的原则执行
- 八、Spark 数据倾斜
- 1. 预聚合原始数据
- 2. 预处理导致倾斜的key
- 3. 提高reduce并行度
- 4. 使用map join
- 九、Spark性能优化
- Spark调优之RDD算子调优
- 1. RDD复用
- 2. 尽早filter
- 3. 读取大量小文件-用wholeTextFiles
- 4. mapPartition和foreachPartition
- 5. filter+coalesce/repartition(减少分区)
- 6. 并行度设置
- 7. repartition/coalesce调节并行度
- 8. reduceByKey本地预聚合
- 9. 使用持久化+checkpoint
- 10. 使用广播变量
- 11. 使用Kryo序列化
- Spark调优之Shuffle调优
- 1. map和reduce端缓冲区大小
- 2. reduce端重试次数和等待时间间隔
- 3. bypass机制开启阈值
- 十、故障排除
- 1. 避免OOM-out of memory
- 2. 避免GC导致的shuffle文件拉取失败
- 3. YARN-CLIENT模式导致的网卡流量激增问题
- 4. YARN-CLUSTER模式的JVM栈内存溢出无法执行问题
- 5. 避免SparkSQL JVM栈内存溢出
- 十一、Spark大厂面试真题
- 1. 通常来说,Spark与MapReduce相比,Spark运行效率更高。请说明效率更高来源于Spark内置的哪些机制?
- 2. hadoop和spark使用场景?
- 3. spark如何保证宕机迅速恢复?
- 4. hadoop和spark的相同点和不同点?
- 5. RDD持久化原理?
- 6. checkpoint检查点机制?
- 7. checkpoint和持久化机制的区别?
- 8. RDD机制理解吗?
- 9. Spark streaming以及基本工作原理?
- 10. DStream以及基本工作原理?
- 11. spark有哪些组件?
- 12. spark工作机制?
- 13. 说下宽依赖和窄依赖
- 14. Spark主备切换机制原理知道吗?
- 15. spark解决了hadoop的哪些问题?
- 16. 数据倾斜的产生和解决办法?
- 17. 你用sparksql处理的时候, 处理过程中用的dataframe还是直接写的sql?为什么?
- 18. RDD中reduceBykey与groupByKey哪个性能好,为什么
- 19. Spark master HA主从切换过程不会影响到集群已有作业的运行,为什么
- 20. spark master使用zookeeper进行ha,有哪些源数据保存到Zookeeper里面
- 参考
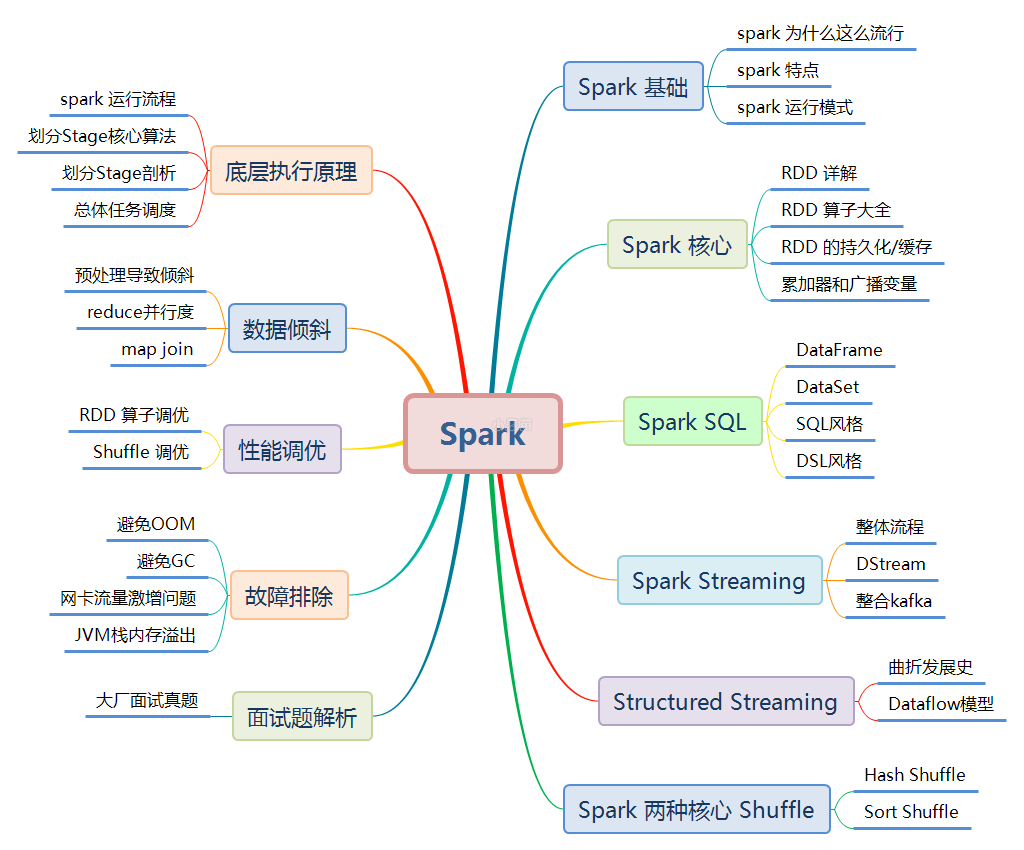
Spark**涉及的知识点如下图所示,本文将逐一讲解:**
本文档参考了关于 Spark 的众多资料整理而成,为了整洁的排版及舒适的阅读,对于模糊不清晰的图片及黑白图片进行重新绘制成了高清彩图。
一、Spark 基础
1. 激动人心的 Spark 发展史
大数据、人工智能( Artificial Intelligence )像当年的石油、电力一样, 正以前所未有的广度和深度影响所有的行业, 现在及未来公司的核心壁垒是数据, 核心竞争力来自基于大数据的人工智能的竞争。
Spark 是当今大数据领域最活跃、最热门、最高效的大数据通用计算平台之一。
2009 年诞生于美国加州大学伯克利分校 AMP 实验室;
2010 年通过 BSD 许可协议开源发布;
2013 年捐赠给 Apache 软件基金会并切换开源协议到切换许可协议至 Apache2.0;
2014 年 2 月,Spark 成为 Apache 的顶级项目;
2014 年 11 月, Spark 的母公司 Databricks 团队使用 Spark 刷新数据排序世界记录。
Spark 成功构建起了一体化、多元化的大数据处理体系。在任何规模的数据计算中, Spark 在性能和扩展性上都更具优势。
- Hadoop 之父 Doug Cutting 指出:Use of MapReduce engine for Big Data projects will decline, replaced by Apache Spark (大数据项目的 MapReduce 引擎的使用将下降,由 Apache Spark 取代)。
- Hadoop 商业发行版本的市场领导者 Cloudera 、HortonWorks 、MapR 纷纷转投 Spark,并把 Spark 作为大数据解决方案的首选和核心计算引擎。
2014 年的 Benchmark 测试中, Spark 秒杀 Hadoop ,在使用十分之一计算资源的情况下,相同数据的排序上, Spark 比 MapReduce 快 3 倍!在没有官方 PB 排序对比的情况下,首次将 Spark 推到了 IPB 数据(十万亿条记录) 的排序,在使用 190 个节点的情况下,工作负载在 4 小时内完成, 同样远超雅虎之前使用 3800 台主机耗时 16 个小时的记录。
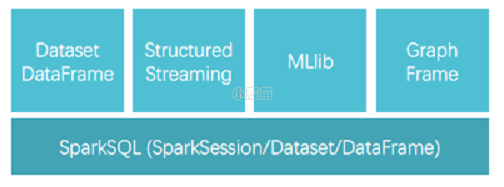
在 FullStack 理想的指引下,Spark 中的 Spark SQL 、SparkStreaming 、MLLib 、GraphX 、R 五大子框架和库之间可以无缝地共享数据和操作, 这不仅打造了 Spark 在当今大数据计算领域其他计算框架都无可匹敌的优势, 而且使得 Spark 正在加速成为大数据处理中心首选通用计算平台。
2. Spark 为什么会流行
- 原因 1:优秀的数据模型和丰富计算抽象
Spark 产生之前,已经有 MapReduce 这类非常成熟的计算系统存在了,并提供了高层次的 API(map/reduce),把计算运行在集群中并提供容错能力,从而实现分布式计算。
虽然 MapReduce 提供了对数据访问和计算的抽象,但是对于数据的复用就是简单的将中间数据写到一个稳定的文件系统中(例如 HDFS),所以会产生数据的复制备份,磁盘的 I/O 以及数据的序列化,所以在遇到需要在多个计算之间复用中间结果的操作时效率就会非常的低。而这类操作是非常常见的,例如迭代式计算,交互式数据挖掘,图计算等。
认识到这个问题后,学术界的 AMPLab 提出了一个新的模型,叫做 RDD。RDD 是一个可以容错且并行的数据结构(其实可以理解成分布式的集合,操作起来和操作本地集合一样简单),它可以让用户显式的将中间结果数据集保存在内存中,并且通过控制数据集的分区来达到数据存放处理最优化.同时 RDD 也提供了丰富的 API (map、reduce、filter、foreach、redeceByKey...)来操作数据集。后来 RDD 被 AMPLab 在一个叫做 Spark 的框架中提供并开源。
简而言之,Spark 借鉴了 MapReduce 思想发展而来,保留了其分布式并行计算的优点并改进了其明显的缺陷。让中间数据存储在内存中提高了运行速度、并提供丰富的操作数据的 API 提高了开发速度。
- 原因 2:完善的生态圈-fullstack
 目前,Spark 已经发展成为一个包含多个子项目的集合,其中包含 SparkSQL、Spark Streaming、GraphX、MLlib 等子项目。
目前,Spark 已经发展成为一个包含多个子项目的集合,其中包含 SparkSQL、Spark Streaming、GraphX、MLlib 等子项目。
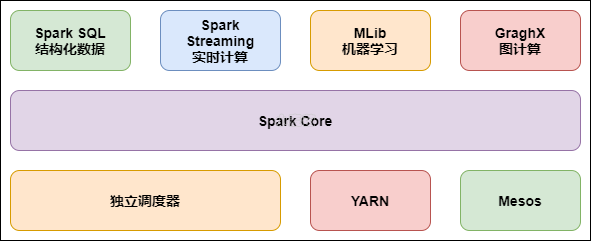
Spark Core:实现了 Spark 的基本功能,包含 RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块。
Spark SQL:Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 操作数据。
Spark Streaming:Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API。
Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。
GraphX(图计算):Spark 中用于图计算的 API,性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。
Structured Streaming:处理结构化流,统一了离线和实时的 API。
3. Spark VS Hadoop
| Hadoop | Spark | |
|---|---|---|
| 类型 | 分布式基础平台, 包含计算, 存储, 调度 | 分布式计算工具 |
| 场景 | 大规模数据集上的批处理 | 迭代计算, 交互式计算, 流计算 |
| 价格 | 对机器要求低, 便宜 | 对内存有要求, 相对较贵 |
| 编程范式 | Map+Reduce, API 较为底层, 算法适应性差 | RDD 组成 DAG 有向无环图, API 较为顶层, 方便使用 |
| 数据存储结构 | MapReduce 中间计算结果存在 HDFS 磁盘上, 延迟大 | RDD 中间运算结果存在内存中 , 延迟小 |
| 运行方式 | Task 以进程方式维护, 任务启动慢 | Task 以线程方式维护, 任务启动快 |
💖 注意:
尽管 Spark 相对于 Hadoop 而言具有较大优势,但 Spark 并不能完全替代 Hadoop,Spark 主要用于替代 Hadoop 中的 MapReduce 计算模型。存储依然可以使用 HDFS,但是中间结果可以存放在内存中;调度可以使用 Spark 内置的,也可以使用更成熟的调度系统 YARN 等。
实际上,Spark 已经很好地融入了 Hadoop 生态圈,并成为其中的重要一员,它可以借助于 YARN 实现资源调度管理,借助于 HDFS 实现分布式存储。
此外,Hadoop 可以使用廉价的、异构的机器来做分布式存储与计算,但是,Spark 对硬件的要求稍高一些,对内存与 CPU 有一定的要求。
3. Spark 特点
- 快
与 Hadoop 的 MapReduce 相比,Spark 基于内存的运算要快 100 倍以上,基于硬盘的运算也要快 10 倍以上。Spark 实现了高效的 DAG 执行引擎,可以通过基于内存来高效处理数据流。
- 易用
Spark 支持 Java、Python、R 和 Scala 的 API,还支持超过 80 种高级算法,使用户可以快速构建不同的应用。而且 Spark 支持交互式的 Python 和 Scala 的 shell,可以非常方便地在这些 shell 中使用 Spark 集群来验证解决问题的方法。
- 通用
Spark 提供了统一的解决方案。Spark 可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark 统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
- 兼容性
Spark 可以非常方便地与其他的开源产品进行融合。比如,Spark 可以使用 Hadoop 的 YARN 和 Apache Mesos 作为它的资源管理和调度器,并且可以处理所有 Hadoop 支持的数据,包括 HDFS、HBase 和 Cassandra 等。这对于已经部署 Hadoop 集群的用户特别重要,因为不需要做任何数据迁移就可以使用 Spark 的强大处理能力。Spark 也可以不依赖于第三方的资源管理和调度器,它实现了 Standalone 作为其内置的资源管理和调度框架,这样进一步降低了 Spark 的使用门槛,使得所有人都可以非常容易地部署和使用 Spark。此外,Spark 还提供了在 EC2 上部署 Standalone 的 Spark 集群的工具。
4. Spark 运行模式
local 本地模式(单机)--学习测试使用
分为 local 单线程和 local-cluster 多线程。
standalone 独立集群模式--学习测试使用
典型的 Mater/slave 模式。
standalone-HA 高可用模式--生产环境使用
基于 standalone 模式,使用 zk 搭建高可用,避免 Master 是有单点故障的。
on yarn 集群模式--生产环境使用
运行在 yarn 集群之上,由 yarn 负责资源管理,Spark 负责任务调度和计算。
好处:计算资源按需伸缩,集群利用率高,共享底层存储,避免数据跨集群迁移。
on mesos 集群模式--国内使用较少
运行在 mesos 资源管理器框架之上,由 mesos 负责资源管理,Spark 负责任务调度和计算。
on cloud 集群模式--中小公司未来会更多的使用云服务
比如 AWS 的 EC2,使用这个模式能很方便的访问 Amazon 的 S3。
二、Spark Core
1. RDD 详解
1) 为什么要有 RDD?
在许多迭代式算法(比如机器学习、图算法等)和交互式数据挖掘中,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,之前的 MapReduce 框架采用非循环式的数据流模型,把中间结果写入到 HDFS 中,带来了大量的数据复制、磁盘 IO 和序列化开销。且这些框架只能支持一些特定的计算模式(map/reduce),并没有提供一种通用的数据抽象。
AMP 实验室发表的一篇关于 RDD 的论文:《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》就是为了解决这些问题的。
RDD 提供了一个抽象的数据模型,让我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换操作(函数),不同 RDD 之间的转换操作之间还可以形成依赖关系,进而实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘 IO 和序列化开销,并且还提供了更多的 API(map/reduec/filter/groupBy...)。
2) RDD 是什么?
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。单词拆解:
- Resilient :它是弹性的,RDD 里面的中的数据可以保存在内存中或者磁盘里面;
- Distributed :它里面的元素是分布式存储的,可以用于分布式计算;
- Dataset: 它是一个集合,可以存放很多元素。
3) RDD 主要属性
进入 RDD 的源码中看下:
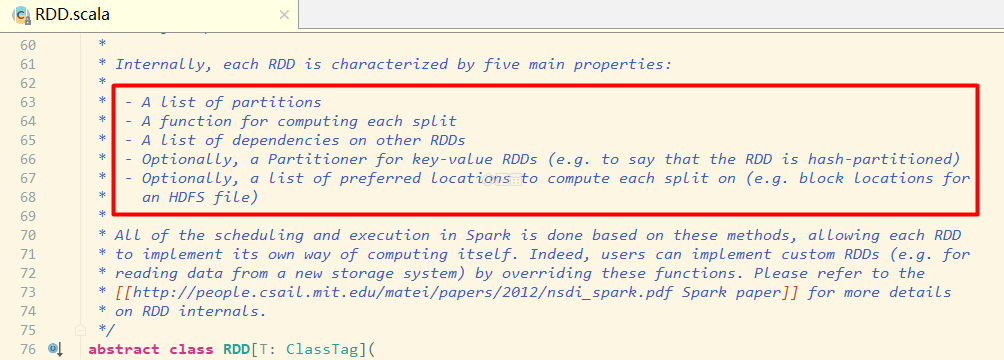 RDD源码
RDD源码
在源码中可以看到有对 RDD 介绍的注释,我们来翻译下:
- A list of partitions :一组分片(Partition)/一个分区(Partition)列表,即数据集的基本组成单位。对于 RDD 来说,每个分片都会被一个计算任务处理,分片数决定并行度。用户可以在创建 RDD 时指定 RDD 的分片个数,如果没有指定,那么就会采用默认值。
- A function for computing each split :一个函数会被作用在每一个分区。Spark 中 RDD 的计算是以分片为单位的,compute 函数会被作用到每个分区上。
- A list of dependencies on other RDDs :一个 RDD 会依赖于其他多个 RDD。RDD 的每次转换都会生成一个新的 RDD,所以 RDD 之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark 可以通过这个依赖关系重新计算丢失的分区数据,而不是对 RDD 的所有分区进行重新计算。(Spark 的容错机制)
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned):可选项,对于 KV 类型的 RDD 会有一个 Partitioner,即 RDD 的分区函数,默认为 HashPartitioner。
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file):可选项,一个列表,存储存取每个 Partition 的优先位置(preferred location)。对于一个 HDFS 文件来说,这个列表保存的就是每个 Partition 所在的块的位置。按照"移动数据不如移动计算"的理念,Spark 在进行任务调度的时候,会尽可能选择那些存有数据的 worker 节点来进行任务计算。
总结
RDD 是一个数据集的表示,不仅表示了数据集,还表示了这个数据集从哪来,如何计算,主要属性包括:
- 分区列表
- 计算函数
- 依赖关系
- 分区函数(默认是 hash)
- 最佳位置
分区列表、分区函数、最佳位置,这三个属性其实说的就是数据集在哪,在哪计算更合适,如何分区;
计算函数、依赖关系,这两个属性其实说的是数据集怎么来的。
2. RDD-API
1) RDD 的创建方式
- 由外部存储系统的数据集创建,包括本地的文件系统,还有所有 Hadoop 支持的数据集,比如 HDFS、Cassandra、HBase 等:
val rdd1 = sc.textFile("hdfs://node1:8020/wordcount/input/words.txt") - 通过已有的 RDD 经过算子转换生成新的 RDD:
val rdd2=rdd1.flatMap(_.split(" ")) - 由一个已经存在的 Scala 集合创建:
val rdd3 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
或者val rdd4 = sc.makeRDD(List(1,2,3,4,5,6,7,8))
makeRDD 方法底层调用了 parallelize 方法:
 RDD源码
RDD源码
2) RDD 的算子分类
RDD 的算子分为两类:
- Transformation转换操作:返回一个新的 RDD
- Action动作操作:返回值不是 RDD(无返回值或返回其他的)
❣️ 注意:
1、RDD 不实际存储真正要计算的数据,而是记录了数据的位置在哪里,数据的转换关系(调用了什么方法,传入什么函数)。
2、RDD 中的所有转换都是惰性求值/延迟执行的,也就是说并不会直接计算。只有当发生一个要求返回结果给 Driver 的 Action 动作时,这些转换才会真正运行。
3、之所以使用惰性求值/延迟执行,是因为这样可以在 Action 时对 RDD 操作形成 DAG 有向无环图进行 Stage 的划分和并行优化,这种设计让 Spark 更加有效率地运行。
3) Transformation 转换算子
| 转换算子 | 含义 |
|---|---|
| map(func) | 返回一个新的 RDD,该 RDD 由每一个输入元素经过 func 函数转换后组成 |
| filter(func) | 返回一个新的 RDD,该 RDD 由经过 func 函数计算后返回值为 true 的输入元素组成 |
| flatMap(func) | 类似于 map,但是每一个输入元素可以被映射为 0 或多个输出元素(所以 func 应该返回一个序列,而不是单一元素) |
| mapPartitions(func) | 类似于 map,但独立地在 RDD 的每一个分片上运行,因此在类型为 T 的 RDD 上运行时,func 的函数类型必须是 Iterator[T] => Iterator[U] |
| mapPartitionsWithIndex(func) | 类似于 mapPartitions,但 func 带有一个整数参数表示分片的索引值,因此在类型为 T 的 RDD 上运行时,func 的函数类型必须是(Int, Interator[T]) => Iterator[U] |
| sample(withReplacement, fraction, seed) | 根据 fraction 指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed 用于指定随机数生成器种子 |
| union(otherDataset) | 对源 RDD 和参数 RDD 求并集后返回一个新的 RDD |
| intersection(otherDataset) | 对源 RDD 和参数 RDD 求交集后返回一个新的 RDD |
| distinct([numTasks])) | 对源 RDD 进行去重后返回一个新的 RDD |
| groupByKey([numTasks]) | 在一个(K,V)的 RDD 上调用,返回一个(K, Iterator[V])的 RDD |
| reduceByKey(func, [numTasks]) | 在一个(K,V)的 RDD 上调用,返回一个(K,V)的 RDD,使用指定的 reduce 函数,将相同 key 的值聚合到一起,与 groupByKey 类似,reduce 任务的个数可以通过第二个可选的参数来设置 |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | 对 PairRDD 中相同的 Key 值进行聚合操作,在聚合过程中同样使用了一个中立的初始值。和 aggregate 函数类似,aggregateByKey 返回值的类型不需要和 RDD 中 value 的类型一致 |
| sortByKey([ascending], [numTasks]) | 在一个(K,V)的 RDD 上调用,K 必须实现 Ordered 接口,返回一个按照 key 进行排序的(K,V)的 RDD |
| sortBy(func,[ascending], [numTasks]) | 与 sortByKey 类似,但是更灵活 |
| join(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的 RDD 上调用,返回一个相同 key 对应的所有元素对在一起的(K,(V,W))的 RDD |
| cogroup(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的 RDD 上调用,返回一个(K,(Iterable,Iterable))类型的 RDD |
| cartesian(otherDataset) | 笛卡尔积 |
| pipe(command, [envVars]) | 对 rdd 进行管道操作 |
| coalesce(numPartitions) | 减少 RDD 的分区数到指定值。在过滤大量数据之后,可以执行此操作 |
| repartition(numPartitions) | 重新给 RDD 分区 |
4) Action 动作算子
| 动作算子 | 含义 |
|---|---|
| reduce(func) | 通过 func 函数聚集 RDD 中的所有元素,这个功能必须是可交换且可并联的 |
| collect() | 在驱动程序中,以数组的形式返回数据集的所有元素 |
| count() | 返回 RDD 的元素个数 |
| first() | 返回 RDD 的第一个元素(类似于 take(1)) |
| take(n) | 返回一个由数据集的前 n 个元素组成的数组 |
| takeSample(withReplacement,num, [seed]) | 返回一个数组,该数组由从数据集中随机采样的 num 个元素组成,可以选择是否用随机数替换不足的部分,seed 用于指定随机数生成器种子 |
| takeOrdered(n, [ordering]) | 返回自然顺序或者自定义顺序的前 n 个元素 |
| saveAsTextFile(path) | 将数据集的元素以 textfile 的形式保存到 HDFS 文件系统或者其他支持的文件系统,对于每个元素,Spark 将会调用 toString 方法,将它装换为文件中的文本 |
| saveAsSequenceFile(path) | 将数据集中的元素以 Hadoop sequencefile 的格式保存到指定的目录下,可以使 HDFS 或者其他 Hadoop 支持的文件系统 |
| saveAsObjectFile(path) | 将数据集的元素,以 Java 序列化的方式保存到指定的目录下 |
| countByKey() | 针对(K,V)类型的 RDD,返回一个(K,Int)的 map,表示每一个 key 对应的元素个数 |
| foreach(func) | 在数据集的每一个元素上,运行函数 func 进行更新 |
| foreachPartition(func) | 在数据集的每一个分区上,运行函数 func |
统计操作:
| 算子 | 含义 |
|---|---|
| count | 个数 |
| mean | 均值 |
| sum | 求和 |
| max | 最大值 |
| min | 最小值 |
| variance | 方差 |
| sampleVariance | 从采样中计算方差 |
| stdev | 标准差:衡量数据的离散程度 |
| sampleStdev | 采样的标准差 |
| stats | 查看统计结果 |
4) RDD 算子练习
- 需求:
给定一个键值对 RDD:
1 | val rdd = sc.parallelize(Array(("spark",2),("hadoop",6),("hadoop",4),("spark",6))) |
key 表示图书名称,value 表示某天图书销量
请计算每个键对应的平均值,也就是计算每种图书的每天平均销量。
最终结果:("spark",4),("hadoop",5)。
- 答案 1:
1 2 3 4 5 6 | val rdd = sc.parallelize(Array(("spark",2),("hadoop",6),("hadoop",4),("spark",6))) val rdd2 = rdd.groupByKey() rdd2.collect //Array[(String, Iterable[Int])] = Array((spark,CompactBuffer(2, 6)), (hadoop,CompactBuffer(6, 4))) rdd2.mapValues(v=>v.sum/v.size).collect Array[(String, Int)] = Array((spark,4), (hadoop,5)) |
- 答案 2:
1 2 3 4 5 6 7 8 | val rdd = sc.parallelize(Array(("spark",2),("hadoop",6),("hadoop",4),("spark",6))) val rdd2 = rdd.groupByKey() rdd2.collect //Array[(String, Iterable[Int])] = Array((spark,CompactBuffer(2, 6)), (hadoop,CompactBuffer(6, 4))) val rdd3 = rdd2.map(t=>(t._1,t._2.sum /t._2.size)) rdd3.collect //Array[(String, Int)] = Array((spark,4), (hadoop,5)) |
3. RDD 的持久化/缓存
在实际开发中某些 RDD 的计算或转换可能会比较耗费时间,如果这些 RDD 后续还会频繁的被使用到,那么可以将这些 RDD 进行持久化/缓存,这样下次再使用到的时候就不用再重新计算了,提高了程序运行的效率。
1 2 3 4 5 | val rdd1 = sc.textFile("hdfs://node01:8020/words.txt") val rdd2 = rdd1.flatMap(x=>x.split(" ")).map((_,1)).reduceByKey(_+_) rdd2.cache //缓存/持久化 rdd2.sortBy(_._2,false).collect//触发action,会去读取HDFS的文件,rdd2会真正执行持久化 rdd2.sortBy(_._2,false).collect//触发action,会去读缓存中的数据,执行速度会比之前快,因为rdd2已经持久化到内存中了 |
持久化/缓存 API 详解
- ersist 方法和 cache 方法
RDD 通过 persist 或 cache 方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 时,该 RDD 将会被缓存在计算节点的内存中,并供后面重用。
通过查看 RDD 的源码发现 cache 最终也是调用了 persist 无参方法(默认存储只存在内存中):
 RDD源码
RDD源码
- 存储级别
默认的存储级别都是仅在内存存储一份,Spark 的存储级别还有好多种,存储级别在 object StorageLevel 中定义的。
| 持久化级别 | 说明 |
|---|---|
| MORY_ONLY(默认) | 将 RDD 以非序列化的 Java 对象存储在 JVM 中。如果没有足够的内存存储 RDD,则某些分区将不会被缓存,每次需要时都会重新计算。这是默认级别 |
| MORY_AND_DISK(开发中可以使用这个) | 将 RDD 以非序列化的 Java 对象存储在 JVM 中。如果数据在内存中放不下,则溢写到磁盘上.需要时则会从磁盘上读取 |
| MEMORY_ONLY_SER (Java and Scala) | 将 RDD 以序列化的 Java 对象(每个分区一个字节数组)的方式存储.这通常比非序列化对象(deserialized objects)更具空间效率,特别是在使用快速序列化的情况下,但是这种方式读取数据会消耗更多的 CPU |
| MEMORY_AND_DISK_SER (Java and Scala) | 与 MEMORY_ONLY_SER 类似,但如果数据在内存中放不下,则溢写到磁盘上,而不是每次需要重新计算它们 |
| DISK_ONLY | 将 RDD 分区存储在磁盘上 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2 等 | 与上面的储存级别相同,只不过将持久化数据存为两份,备份每个分区存储在两个集群节点上 |
| OFF_HEAP(实验中) | 与 MEMORY_ONLY_SER 类似,但将数据存储在堆外内存中。(即不是直接存储在 JVM 内存中) |
总结:
- RDD 持久化/缓存的目的是为了提高后续操作的速度
- 缓存的级别有很多,默认只存在内存中,开发中使用 memory_and_disk
- 只有执行 action 操作的时候才会真正将 RDD 数据进行持久化/缓存
- 实际开发中如果某一个 RDD 后续会被频繁的使用,可以将该 RDD 进行持久化/缓存
4. RDD 容错机制 Checkpoint
- 持久化的局限:
持久化/缓存可以把数据放在内存中,虽然是快速的,但是也是最不可靠的;也可以把数据放在磁盘上,也不是完全可靠的!例如磁盘会损坏等。
- 问题解决:
Checkpoint 的产生就是为了更加可靠的数据持久化,在 Checkpoint 的时候一般把数据放在在 HDFS 上,这就天然的借助了 HDFS 天生的高容错、高可靠来实现数据最大程度上的安全,实现了 RDD 的容错和高可用。
用法:
1 2 3 | SparkContext.setCheckpointDir("目录") //HDFS的目录 RDD.checkpoint |
- 总结:
- 开发中如何保证数据的安全性性及读取效率:可以对频繁使用且重要的数据,先做缓存/持久化,再做 checkpint 操作。
- 持久化和 Checkpoint 的区别:
- 位置:Persist 和 Cache 只能保存在本地的磁盘和内存中(或者堆外内存--实验中) Checkpoint 可以保存数据到 HDFS 这类可靠的存储上。
- 生命周期:Cache 和 Persist 的 RDD 会在程序结束后会被清除或者手动调用 unpersist 方法 Checkpoint 的 RDD 在程序结束后依然存在,不会被删除。
5. RDD 依赖关系
1) 宽窄依赖
- 两种依赖关系类型:RDD 和它依赖的父 RDD 的关系有两种不同的类型,即宽依赖(wide dependency/shuffle dependency)窄依赖(narrow dependency)

- 图解:
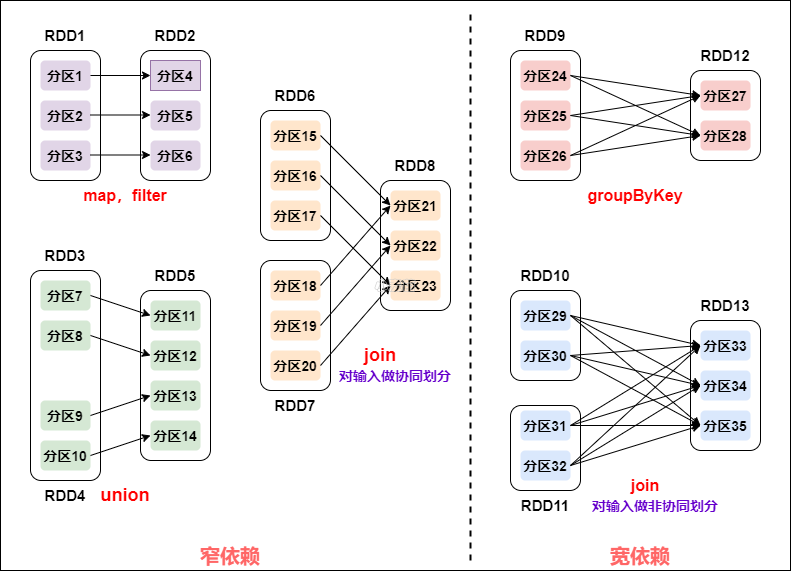 宽窄依赖
宽窄依赖
- 如何区分宽窄依赖:
窄依赖:父 RDD 的一个分区只会被子 RDD 的一个分区依赖;
宽依赖:父 RDD 的一个分区会被子 RDD 的多个分区依赖(涉及到 shuffle)。
2) 为什么要设计宽窄依赖
- 对于窄依赖:
窄依赖的多个分区可以并行计算;
窄依赖的一个分区的数据如果丢失只需要重新计算对应的分区的数据就可以了。
- 对于宽依赖:
划分 Stage(阶段)的依据:对于宽依赖,必须等到上一阶段计算完成才能计算下一阶段。
6. DAG 的生成和划分 Stage
1) DAG 介绍
- DAG 是什么:
DAG(Directed Acyclic Graph 有向无环图)指的是数据转换执行的过程,有方向,无闭环(其实就是 RDD 执行的流程);
原始的 RDD 通过一系列的转换操作就形成了 DAG 有向无环图,任务执行时,可以按照 DAG 的描述,执行真正的计算(数据被操作的一个过程)。
- DAG 的边界
开始:通过 SparkContext 创建的 RDD;
结束:触发 Action,一旦触发 Action 就形成了一个完整的 DAG。
2) DAG 划分 Stage
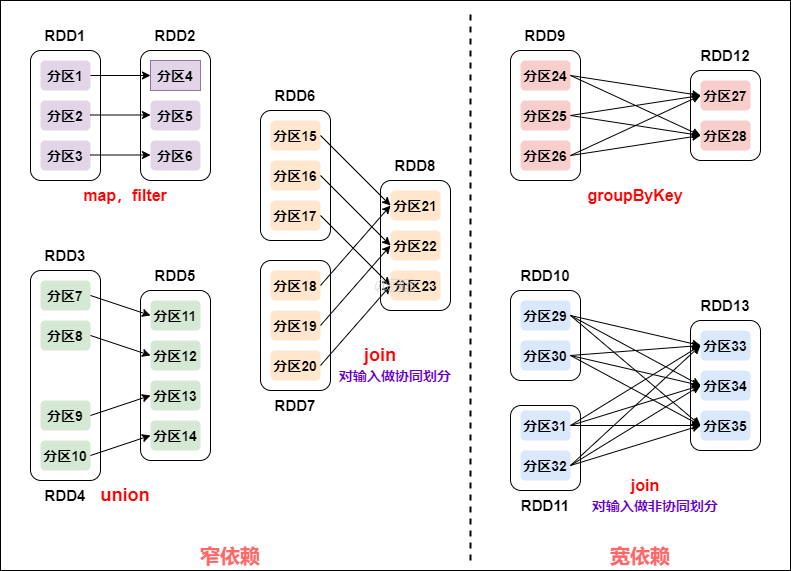 DAG划分Stage
DAG划分Stage
一个 Spark 程序可以有多个 DAG(有几个 Action,就有几个 DAG,上图最后只有一个 Action(图中未表现),那么就是一个 DAG)。
一个 DAG 可以有多个 Stage(根据宽依赖/shuffle 进行划分)。
同一个 Stage 可以有多个 Task 并行执行(task 数=分区数,如上图,Stage1 中有三个分区 P1、P2、P3,对应的也有三个 Task)。
可以看到这个 DAG 中只 reduceByKey 操作是一个宽依赖,Spark 内核会以此为边界将其前后划分成不同的 Stage。
同时我们可以注意到,在图中 Stage1 中,从 textFile 到 flatMap 到 map 都是窄依赖,这几步操作可以形成一个流水线操作,通过 flatMap 操作生成的 partition 可以不用等待整个 RDD 计算结束,而是继续进行 map 操作,这样大大提高了计算的效率。
- 为什么要划分 Stage? --并行计算
一个复杂的业务逻辑如果有 shuffle,那么就意味着前面阶段产生结果后,才能执行下一个阶段,即下一个阶段的计算要依赖上一个阶段的数据。那么我们按照 shuffle 进行划分(也就是按照宽依赖就行划分),就可以将一个 DAG 划分成多个 Stage/阶段,在同一个 Stage 中,会有多个算子操作,可以形成一个 pipeline 流水线,流水线内的多个平行的分区可以并行执行。
- 如何划分 DAG 的 stage?
对于窄依赖,partition 的转换处理在 stage 中完成计算,不划分(将窄依赖尽量放在在同一个 stage 中,可以实现流水线计算)。
对于宽依赖,由于有 shuffle 的存在,只能在父 RDD 处理完成后,才能开始接下来的计算,也就是说需要要划分 stage。
总结:
Spark 会根据 shuffle/宽依赖使用回溯算法来对 DAG 进行 Stage 划分,从后往前,遇到宽依赖就断开,遇到窄依赖就把当前的 RDD 加入到当前的 stage/阶段中
具体的划分算法请参见 AMP 实验室发表的论文:《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》http://xueshu.baidu.com/usercenter/paper/show?paperid=b33564e60f0a7e7a1889a9da10963461&site=xueshu_se
7. RDD 累加器和广播变量
在默认情况下,当 Spark 在集群的多个不同节点的多个任务上并行运行一个函数时,它会把函数中涉及到的每个变量,在每个任务上都生成一个副本。但是,有时候需要在多个任务之间共享变量,或者在任务(Task)和任务控制节点(Driver Program)之间共享变量。
为了满足这种需求,Spark 提供了两种类型的变量:
- 累加器 accumulators:累加器支持在所有不同节点之间进行累加计算(比如计数或者求和)。
- 广播变量 broadcast variables:广播变量用来把变量在所有节点的内存之间进行共享,在每个机器上缓存一个只读的变量,而不是为机器上的每个任务都生成一个副本。
1) 累加器
1. 不使用累加器
1 2 3 4 | var counter = 0 val data = Seq(1, 2, 3) data.foreach(x => counter += x) println("Counter value: "+ counter) |
运行结果:
1 | Counter value: 6 |
如果我们将 data 转换成 RDD,再来重新计算:
1 2 3 4 5 | var counter = 0 val data = Seq(1, 2, 3) var rdd = sc.parallelize(data) rdd.foreach(x => counter += x) println("Counter value: "+ counter) |
运行结果:
1 | Counter value: 0 |
2. 使用累加器
通常在向 Spark 传递函数时,比如使用 map() 函数或者用 filter() 传条件时,可以使用驱动器程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响驱动器中的对应变量。这时使用累加器就可以实现我们想要的效果:
val xx: Accumulator[Int] = sc.accumulator(0)
3. 代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | import org.apache.spark.rdd.RDD import org.apache.spark.{Accumulator, SparkConf, SparkContext} object AccumulatorTest { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]") val sc: SparkContext = new SparkContext(conf) sc.setLogLevel("WARN") //使用scala集合完成累加 var counter1: Int = 0; var data = Seq(1,2,3) data.foreach(x => counter1 += x ) println(counter1)//6 println("+++++++++++++++++++++++++") //使用RDD进行累加 var counter2: Int = 0; val dataRDD: RDD[Int] = sc.parallelize(data) //分布式集合的[1,2,3] dataRDD.foreach(x => counter2 += x) println(counter2)//0 //注意:上面的RDD操作运行结果是0 //因为foreach中的函数是传递给Worker中的Executor执行,用到了counter2变量 //而counter2变量在Driver端定义的,在传递给Executor的时候,各个Executor都有了一份counter2 //最后各个Executor将各自个x加到自己的counter2上面了,和Driver端的counter2没有关系 //那这个问题得解决啊!不能因为使用了Spark连累加都做不了了啊! //如果解决?---使用累加器 val counter3: Accumulator[Int] = sc.accumulator(0) dataRDD.foreach(x => counter3 += x) println(counter3)//6 } } |
2) 广播变量
1. 不使用广播变量
2. 使用广播变量
3. 代码示例:
关键词:sc.broadcast()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | import org.apache.spark.broadcast.Broadcast import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object BroadcastVariablesTest { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]") val sc: SparkContext = new SparkContext(conf) sc.setLogLevel("WARN") //不使用广播变量 val kvFruit: RDD[(Int, String)] = sc.parallelize(List((1,"apple"),(2,"orange"),(3,"banana"),(4,"grape"))) val fruitMap: collection.Map[Int, String] =kvFruit.collectAsMap //scala.collection.Map[Int,String] = Map(2 -> orange, 4 -> grape, 1 -> apple, 3 -> banana) val fruitIds: RDD[Int] = sc.parallelize(List(2,4,1,3)) //根据水果编号取水果名称 val fruitNames: RDD[String] = fruitIds.map(x=>fruitMap(x)) fruitNames.foreach(println) //注意:以上代码看似一点问题没有,但是考虑到数据量如果较大,且Task数较多, //那么会导致,被各个Task共用到的fruitMap会被多次传输 //应该要减少fruitMap的传输,一台机器上一个,被该台机器中的Task共用即可 //如何做到?---使用广播变量 //注意:广播变量的值不能被修改,如需修改可以将数据存到外部数据源,如MySQL、Redis println("=====================") val BroadcastFruitMap: Broadcast[collection.Map[Int, String]] = sc.broadcast(fruitMap) val fruitNames2: RDD[String] = fruitIds.map(x=>BroadcastFruitMap.value(x)) fruitNames2.foreach(println) } } |
三、Spark SQL
1. 数据分析方式
1) 命令式
在前面的 RDD 部分, 非常明显可以感觉的到是命令式的, 主要特征是通过一个算子, 可以得到一个结果, 通过结果再进行后续计算。
1 2 3 4 5 | sc.textFile("...") .flatMap(_.split(" ")) .map((_, 1)) .reduceByKey(_ + _) .collect() |
- 命令式的优点
- 操作粒度更细,能够控制数据的每一个处理环节;
- 操作更明确,步骤更清晰,容易维护;
- 支持半/非结构化数据的操作。
- 命令式的缺点
- 需要一定的代码功底;
- 写起来比较麻烦。
2) SQL
对于一些数据科学家/数据库管理员/DBA, 要求他们为了做一个非常简单的查询, 写一大堆代码, 明显是一件非常残忍的事情, 所以 SQL on Hadoop 是一个非常重要的方向。
1 2 3 4 5 6 | SELECT name, age, school FROM students WHERE age > 10 |
- SQL 的优点
表达非常清晰, 比如说这段 SQL 明显就是为了查询三个字段,条件是查询年龄大于 10 岁的。
- SQL 的缺点
- 试想一下 3 层嵌套的 SQL 维护起来应该挺力不从心的吧;
- 试想一下如果使用 SQL 来实现机器学习算法也挺为难的吧。
3) 总结
SQL 擅长数据分析和通过简单的语法表示查询,命令式操作适合过程式处理和算法性的处理。
在 Spark 出现之前,对于结构化数据的查询和处理, 一个工具一向只能支持 SQL 或者命令式,使用者被迫要使用多个工具来适应两种场景,并且多个工具配合起来比较费劲。
而 Spark 出现了以后,统一了两种数据处理范式是一种革新性的进步。
2. SparkSQL 前世今生
SQL 是数据分析领域一个非常重要的范式,所以 Spark 一直想要支持这种范式,而伴随着一些决策失误,这个过程其实还是非常曲折的。
1) 发展历史
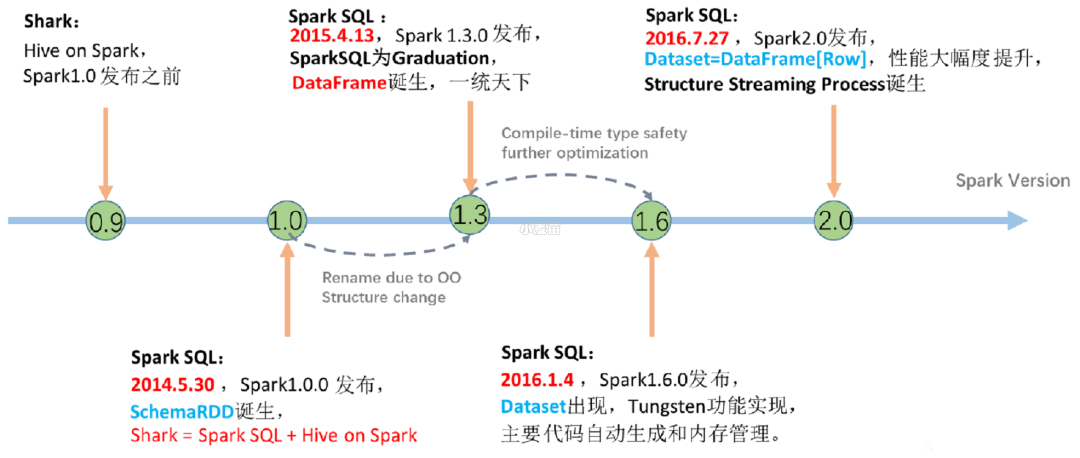
- Hive
解决的问题:
Hive 实现了 SQL on Hadoop,使用 MapReduce 执行任务 简化了 MapReduce 任务。
新的问题:
Hive 的查询延迟比较高,原因是使用 MapReduce 做计算。
- Shark
解决的问题:
Shark 改写 Hive 的物理执行计划, 使用 Spark 代替 MapReduce 物理引擎 使用列式内存存储。以上两点使得 Shark 的查询效率很高。
新的问题:
Shark 执行计划的生成严重依赖 Hive,想要增加新的优化非常困难;
Hive 是进程级别的并行,Spark 是线程级别的并行,所以 Hive 中很多线程不安全的代码不适用于 Spark;
由于以上问题,Shark 维护了 Hive 的一个分支,并且无法合并进主线,难以为继;
在 2014 年 7 月 1 日的 Spark Summit 上,Databricks 宣布终止对 Shark 的开发,将重点放到 Spark SQL 上。
- SparkSQL-DataFrame
解决的问题:
Spark SQL 执行计划和优化交给优化器 Catalyst;
内建了一套简单的 SQL 解析器,可以不使用 HQL;
还引入和 DataFrame 这样的 DSL API,完全可以不依赖任何 Hive 的组件
新的问题:
对于初期版本的 SparkSQL,依然有挺多问题,例如只能支持 SQL 的使用,不能很好的兼容命令式,入口不够统一等。
- SparkSQL-Dataset
SparkSQL 在 1.6 时代,增加了一个新的 API,叫做 Dataset,Dataset 统一和结合了 SQL 的访问和命令式 API 的使用,这是一个划时代的进步。
在 Dataset 中可以轻易的做到使用 SQL 查询并且筛选数据,然后使用命令式 API 进行探索式分析。
3. Hive 和 SparkSQL
Hive 是将 SQL 转为 MapReduce。
SparkSQL 可以理解成是将 SQL 解析成:“RDD + 优化” 再执行。
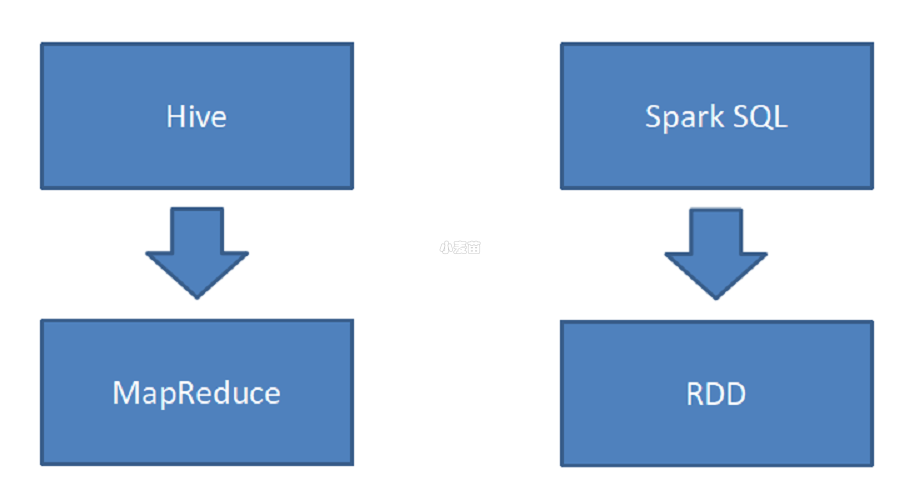
4. 数据分类和 SparkSQL 适用场景
1) 结构化数据
一般指数据有固定的 Schema(约束),例如在用户表中,name 字段是 String 型,那么每一条数据的 name 字段值都可以当作 String 来使用:
| id | name | url | alexa | country |
|---|---|---|---|---|
| 1 | https://www.google.cm/ | 1 | USA | |
| 2 | 淘宝 | https://www.taobao.com/ | 13 | CN |
| 3 | 菜鸟教程 | https://www.runoob.com/ | 4689 | CN |
| 4 | 微博 | http://weibo.com/ | 20 | CN |
| 5 | https://www.facebook.com/ | 3 | USA |
2) 半结构化数据
般指的是数据没有固定的 Schema,但是数据本身是有结构的。
- 没有固定 Schema
指的是半结构化数据是没有固定的 Schema 的,可以理解为没有显式指定 Schema。
比如说一个用户信息的 JSON 文件,
第 1 条数据的 phone_num 有可能是数字,
第 2 条数据的 phone_num 虽说应该也是数字,但是如果指定为 String,也是可以的,
因为没有指定 Schema,没有显式的强制的约束。
- 有结构
虽说半结构化数据是没有显式指定 Schema 的,也没有约束,但是半结构化数据本身是有有隐式的结构的,也就是数据自身可以描述自身。
例如 JSON 文件,其中的某一条数据是有字段这个概念的,每个字段也有类型的概念,所以说 JSON 是可以描述自身的,也就是数据本身携带有元信息。
3) 总结
- 数据分类总结:
| 定义 | 特点 | 举例 | |
|---|---|---|---|
| 结构化数据 | 有固定的 Schema | 有预定义的 Schema | 关系型数据库的表 |
| 半结构化数据 | 没有固定的 Schema,但是有结构 | 没有固定的 Schema,有结构信息,数据一般是自描述的 | 指一些有结构的文件格式,例如 JSON |
| 非结构化数据 | 没有固定 Schema,也没有结构 | 没有固定 Schema,也没有结构 | 指图片/音频之类的格式 |
- Spark 处理什么样的数据?
RDD 主要用于处理非结构化数据 、半结构化数据、结构化;
SparkSQL 主要用于处理结构化数据(较为规范的半结构化数据也可以处理)。
- 总结:
SparkSQL 是一个既支持 SQL 又支持命令式数据处理的工具;
SparkSQL 的主要适用场景是处理结构化数据(较为规范的半结构化数据也可以处理)。
5. Spark SQL 数据抽象
1) DataFrame
- 什么是 DataFrame
DataFrame 的前身是 SchemaRDD,从 Spark 1.3.0 开始 SchemaRDD 更名为 DataFrame。并不再直接继承自 RDD,而是自己实现了 RDD 的绝大多数功能。
DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库的二维表格,带有 Schema 元信息(可以理解为数据库的列名和类型)。
- 总结:
DataFrame 就是一个分布式的表;
DataFrame = RDD - 泛型 + SQL 的操作 + 优化。
2) DataSet
- DataSet:
DataSet 是在 Spark1.6 中添加的新的接口。
与 RDD 相比,保存了更多的描述信息,概念上等同于关系型数据库中的二维表。
与 DataFrame 相比,保存了类型信息,是强类型的,提供了编译时类型检查。
调用 Dataset 的方法先会生成逻辑计划,然后被 spark 的优化器进行优化,最终生成物理计划,然后提交到集群中运行!
DataSet 包含了 DataFrame 的功能。
Spark2.0 中两者统一,DataFrame 表示为 DataSet[Row],即 DataSet 的子集。
DataFrame 其实就是 Dateset[Row]:

3) RDD、DataFrame、DataSet 的区别
- 结构图解:
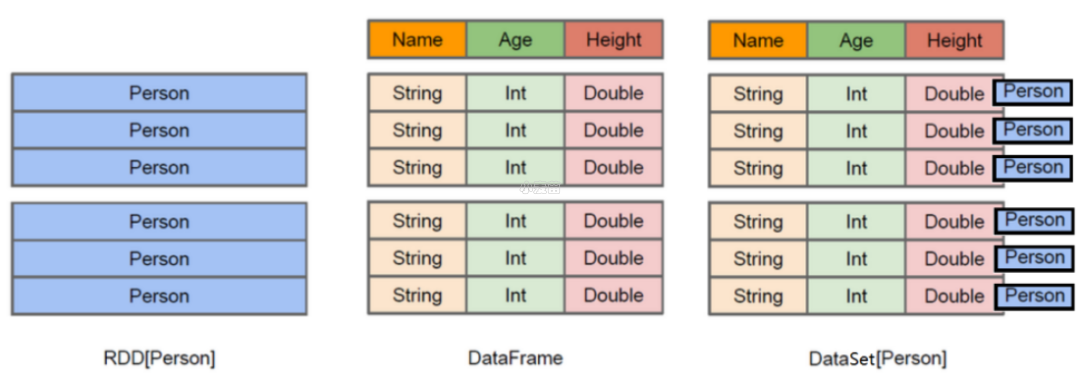
RDD[Person]:
以 Person 为类型参数,但不了解 其内部结构。
DataFrame:
提供了详细的结构信息 schema 列的名称和类型。这样看起来就像一张表了。
DataSet[Person]
不光有 schema 信息,还有类型信息。
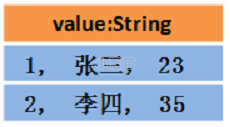
- 数据图解:
假设 RDD 中的两行数据长这样:
1RDD[Person]:那么 DataFrame 中的数据长这样:
DataFrame = RDD[Person] - 泛型 + Schema + SQL 操作 + 优化:


那么 Dataset 中的数据长这样:
Dataset[Person] = DataFrame + 泛型:

Dataset 也可能长这样:Dataset[Row]:
即 DataFrame = DataSet[Row]:
4) 总结
DataFrame = RDD - 泛型 + Schema + SQL + 优化
DataSet = DataFrame + 泛型
DataSet = RDD + Schema + SQL + 优化
6. Spark SQL 应用
在 spark2.0 版本之前
SQLContext 是创建 DataFrame 和执行 SQL 的入口。
HiveContext 通过 hive sql 语句操作 hive 表数据,兼容 hive 操作,hiveContext 继承自 SQLContext。
在 spark2.0 之后
这些都统一于 SparkSession,SparkSession 封装了 SqlContext 及 HiveContext;
实现了 SQLContext 及 HiveContext 所有功能;
通过 SparkSession 还可以获取到 SparkConetxt。
1) 创建 DataFrame/DataSet
- 读取文本文件:
- 在本地创建一个文件,有 id、name、age 三列,用空格分隔,然后上传到 hdfs 上。
vim root/person.txt
1 2 3 4 5 6 | 1 zhangsan 20 2 lisi 29 3 wangwu 25 4 zhaoliu 30 5 tianqi 35 6 kobe 40 |
- 打开 spark-shell
1 | spark/bin/spark-shell |
创建 RDD
1 | val lineRDD= sc.textFile("hdfs://node1:8020/person.txt").map(_.split(" ")) RDD[Array[String]] |
- 定义 case class(相当于表的 schema)
1 | case class Person(id:Int, name:String, age:Int) |
- 将 RDD 和 case class 关联 val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt)) RDD[Person]
- 将 RDD 转换成 DataFrame
1 | val personDF = personRDD.toDF DataFrame |
- 查看数据和 schema
personDF.show
1 2 3 4 5 6 7 8 9 10 | +---+--------+---+ | id| name|age| +---+--------+---+ | 1|zhangsan| 20| | 2| lisi| 29| | 3| wangwu| 25| | 4| zhaoliu| 30| | 5| tianqi| 35| | 6| kobe| 40| +---+--------+---+ |
personDF.printSchema
- 注册表
1 | personDF.createOrReplaceTempView("t_person") |
- 执行 SQL
1 | spark.sql("select id,name from t_person where id > 3").show |
- 也可以通过 SparkSession 构建 DataFrame
1 2 3 | val dataFrame=spark.read.text("hdfs://node1:8020/person.txt") dataFrame.show //注意:直接读取的文本文件没有完整schema信息 dataFrame.printSchema |
- 读取 json 文件:
1 | val jsonDF= spark.read.json("file:///resources/people.json") |
接下来就可以使用 DataFrame 的函数操作
1 | jsonDF.show |
注意:直接读取 json 文件有 schema 信息,因为 json 文件本身含有 Schema 信息,SparkSQL 可以自动解析。
- 读取 parquet 文件:
1 | val parquetDF=spark.read.parquet("file:///resources/users.parquet") |
接下来就可以使用 DataFrame 的函数操作
1 | parquetDF.show |
注意:直接读取 parquet 文件有 schema 信息,因为 parquet 文件中保存了列的信息。
2) 两种查询风格:DSL 和 SQL
- 准备工作:
先读取文件并转换为 DataFrame 或 DataSet:
1 2 3 4 5 6 7 | val lineRDD= sc.textFile("hdfs://node1:8020/person.txt").map(_.split(" ")) case class Person(id:Int, name:String, age:Int) val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt)) val personDF = personRDD.toDF personDF.show //val personDS = personRDD.toDS //personDS.show |
- DSL 风格:
SparkSQL 提供了一个领域特定语言(DSL)以方便操作结构化数据
- 查看 name 字段的数据
1 2 3 4 | personDF.select(personDF.col("name")).show personDF.select(personDF("name")).show personDF.select(col("name")).show personDF.select("name").show |
- 查看 name 和 age 字段数据
1 | personDF.select("name", "age").show |
- 查询所有的 name 和 age,并将 age+1
1 2 3 4 5 6 | personDF.select(personDF.col("name"), personDF.col("age") + 1).show personDF.select(personDF("name"), personDF("age") + 1).show personDF.select(col("name"), col("age") + 1).show personDF.select("name","age").show //personDF.select("name", "age"+1).show personDF.select($"name",$"age",$"age"+1).show |
- 过滤 age 大于等于 25 的,使用 filter 方法过滤
1 2 | personDF.filter(col("age") >= 25).show personDF.filter($"age" >25).show |
- 统计年龄大于 30 的人数
1 2 | personDF.filter(col("age")>30).count() personDF.filter($"age" >30).count() |
- 按年龄进行分组并统计相同年龄的人数
1 | personDF.groupBy("age").count().show |
- SQL 风格:
DataFrame 的一个强大之处就是我们可以将它看作是一个关系型数据表,然后可以通过在程序中使用 spark.sql() 来执行 SQL 查询,结果将作为一个 DataFrame 返回。
如果想使用 SQL 风格的语法,需要将 DataFrame 注册成表,采用如下的方式:
1 2 | personDF.createOrReplaceTempView("t_person") spark.sql("select * from t_person").show |
- 显示表的描述信息
1 | spark.sql("desc t_person").show |
- 查询年龄最大的前两名
1 | spark.sql("select * from t_person order by age desc limit 2").show |
- 查询年龄大于 30 的人的信息
1 | spark.sql("select * from t_person where age > 30 ").show |
- 使用 SQL 风格完成 DSL 中的需求
1 2 3 4 | spark.sql("select name, age + 1 from t_person").show spark.sql("select name, age from t_person where age > 25").show spark.sql("select count(age) from t_person where age > 30").show spark.sql("select age, count(age) from t_person group by age").show |
- 总结:
- DataFrame 和 DataSet 都可以通过 RDD 来进行创建;
- 也可以通过读取普通文本创建--注意:直接读取没有完整的约束,需要通过 RDD+Schema;
- 通过 josn/parquet 会有完整的约束;
- 不管是 DataFrame 还是 DataSet 都可以注册成表,之后就可以使用 SQL 进行查询了! 也可以使用 DSL!
3) Spark SQL 完成 WordCount
- SQL 风格:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | import org.apache.spark.SparkContext import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} object WordCount { def main(args: Array[String]): Unit = { //1.创建SparkSession val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("WARN") //2.读取文件 val fileDF: DataFrame = spark.read.text("D:\\data\\words.txt") val fileDS: Dataset[String] = spark.read.textFile("D:\\data\\words.txt") //fileDF.show() //fileDS.show() //3.对每一行按照空格进行切分并压平 //fileDF.flatMap(_.split(" ")) //注意:错误,因为DF没有泛型,不知道_是String import spark.implicits._ val wordDS: Dataset[String] = fileDS.flatMap(_.split(" "))//注意:正确,因为DS有泛型,知道_是String //wordDS.show() /* +-----+ |value| +-----+ |hello| | me| |hello| | you| ... */ //4.对上面的数据进行WordCount wordDS.createOrReplaceTempView("t_word") val sql = """ |select value ,count(value) as count |from t_word |group by value |order by count desc """.stripMargin spark.sql(sql).show() sc.stop() spark.stop() } } |
- DSL 风格:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | import org.apache.spark.SparkContext import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} object WordCount2 { def main(args: Array[String]): Unit = { //1.创建SparkSession val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("WARN") //2.读取文件 val fileDF: DataFrame = spark.read.text("D:\\data\\words.txt") val fileDS: Dataset[String] = spark.read.textFile("D:\\data\\words.txt") //fileDF.show() //fileDS.show() //3.对每一行按照空格进行切分并压平 //fileDF.flatMap(_.split(" ")) //注意:错误,因为DF没有泛型,不知道_是String import spark.implicits._ val wordDS: Dataset[String] = fileDS.flatMap(_.split(" "))//注意:正确,因为DS有泛型,知道_是String //wordDS.show() /* +-----+ |value| +-----+ |hello| | me| |hello| | you| ... */ //4.对上面的数据进行WordCount wordDS.groupBy("value").count().orderBy($"count".desc).show() sc.stop() spark.stop() } } |
4) Spark SQL 多数据源交互
- 读数据:
读取 json 文件:
1 | spark.read.json("D:\\data\\output\\json").show() |
读取 csv 文件:
1 | spark.read.csv("D:\\data\\output\\csv").toDF("id","name","age").show() |
读取 parquet 文件:
1 | spark.read.parquet("D:\\data\\output\\parquet").show() |
读取 mysql 表:
1 2 3 4 5 | val prop = new Properties() prop.setProperty("user","root") prop.setProperty("password","root") spark.read.jdbc( "jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8","person",prop).show() |
- 写数据:
写入 json 文件:
1 | personDF.write.json("D:\\data\\output\\json") |
写入 csv 文件:
1 | personDF.write.csv("D:\\data\\output\\csv") |
写入 parquet 文件:
1 | personDF.write.parquet("D:\\data\\output\\parquet") |
写入 mysql 表:
1 2 3 4 5 | val prop = new Properties() prop.setProperty("user","root") prop.setProperty("password","root") personDF.write.mode(SaveMode.Overwrite).jdbc( "jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8","person",prop) |
四、Spark Streaming
Spark Streaming 是一个基于 Spark Core 之上的实时计算框架,可以从很多数据源消费数据并对数据进行实时的处理,具有高吞吐量和容错能力强等特点。

Spark Streaming 的特点:
- 易用
可以像编写离线批处理一样去编写流式程序,支持 java/scala/python 语言。
- 容错
SparkStreaming 在没有额外代码和配置的情况下可以恢复丢失的工作。
- 易整合到 Spark 体系
流式处理与批处理和交互式查询相结合。
1. 整体流程
Spark Streaming 中,会有一个接收器组件 Receiver,作为一个长期运行的 task 跑在一个 Executor 上。Receiver 接收外部的数据流形成 input DStream。
DStream 会被按照时间间隔划分成一批一批的 RDD,当批处理间隔缩短到秒级时,便可以用于处理实时数据流。时间间隔的大小可以由参数指定,一般设在 500 毫秒到几秒之间。
对 DStream 进行操作就是对 RDD 进行操作,计算处理的结果可以传给外部系统。
Spark Streaming 的工作流程像下面的图所示一样,接受到实时数据后,给数据分批次,然后传给 Spark Engine 处理最后生成该批次的结果。
2. 数据抽象
Spark Streaming 的基础抽象是 DStream(Discretized Stream,离散化数据流,连续不断的数据流),代表持续性的数据流和经过各种 Spark 算子操作后的结果数据流。
可以从以下多个角度深入理解 DStream:
- DStream 本质上就是一系列时间上连续的 RDD
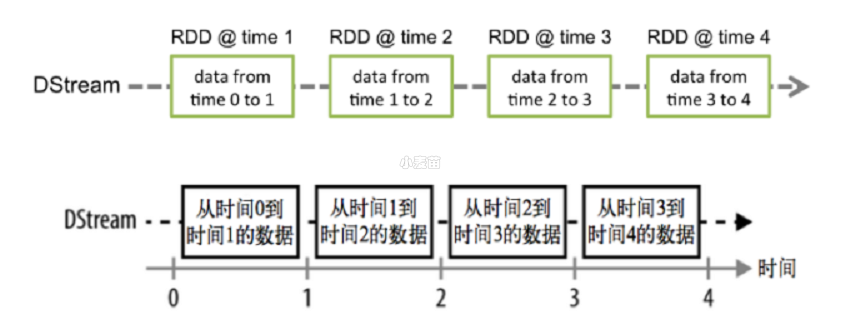
- 对 DStream 的数据的进行操作也是按照 RDD 为单位来进行的
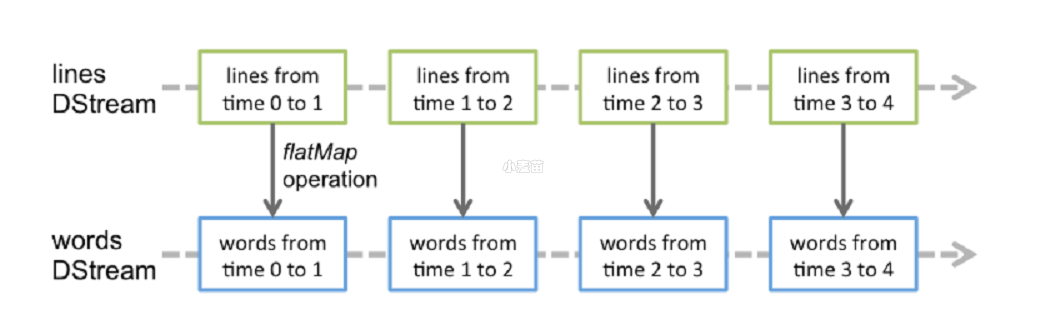
- 容错性,底层 RDD 之间存在依赖关系,DStream 直接也有依赖关系,RDD 具有容错性,那么 DStream 也具有容错性
- 准实时性/近实时性
Spark Streaming 将流式计算分解成多个 Spark Job,对于每一时间段数据的处理都会经过 Spark DAG 图分解以及 Spark 的任务集的调度过程。
对于目前版本的 Spark Streaming 而言,其最小的 Batch Size 的选取在 0.5~5 秒钟之间。
所以 Spark Streaming 能够满足流式准实时计算场景,对实时性要求非常高的如高频实时交易场景则不太适合。
- 总结
简单来说 DStream 就是对 RDD 的封装,你对 DStream 进行操作,就是对 RDD 进行操作。
对于 DataFrame/DataSet/DStream 来说本质上都可以理解成 RDD。
3. DStream 相关操作
DStream 上的操作与 RDD 的类似,分为以下两种:
- Transformations(转换)
- Output Operations(输出)/Action
1) Transformations
以下是常见 Transformation---都是无状态转换:即每个批次的处理不依赖于之前批次的数据:
| Transformation | 含义 |
|---|---|
| map(func) | 对 DStream 中的各个元素进行 func 函数操作,然后返回一个新的 DStream |
| flatMap(func) | 与 map 方法类似,只不过各个输入项可以被输出为零个或多个输出项 |
| filter(func) | 过滤出所有函数 func 返回值为 true 的 DStream 元素并返回一个新的 DStream |
| union(otherStream) | 将源 DStream 和输入参数为 otherDStream 的元素合并,并返回一个新的 DStream |
| reduceByKey(func, [numTasks]) | 利用 func 函数对源 DStream 中的 key 进行聚合操作,然后返回新的(K,V)对构成的 DStream |
| join(otherStream, [numTasks]) | 输入为(K,V)、(K,W)类型的 DStream,返回一个新的(K,(V,W)类型的 DStream |
| transform(func) | 通过 RDD-to-RDD 函数作用于 DStream 中的各个 RDD,可以是任意的 RDD 操作,从而返回一个新的 RDD |
除此之外还有一类特殊的 Transformations---有状态转换:当前批次的处理需要使用之前批次的数据或者中间结果。
有状态转换包括基于追踪状态变化的转换(updateStateByKey)和滑动窗口的转换:
- UpdateStateByKey(func)
- Window Operations 窗口操作
2) Output/Action
Output Operations 可以将 DStream 的数据输出到外部的数据库或文件系统。
当某个 Output Operations 被调用时,spark streaming 程序才会开始真正的计算过程(与 RDD 的 Action 类似)。
| Output Operation | 含义 |
|---|---|
| print() | 打印到控制台 |
| saveAsTextFiles(prefix, [suffix]) | 保存流的内容为文本文件,文件名为"prefix-TIME_IN_MS[.suffix]" |
| saveAsObjectFiles(prefix,[suffix]) | 保存流的内容为 SequenceFile,文件名为 "prefix-TIME_IN_MS[.suffix]" |
| saveAsHadoopFiles(prefix,[suffix]) | 保存流的内容为 hadoop 文件,文件名为"prefix-TIME_IN_MS[.suffix]" |
| foreachRDD(func) | 对 Dstream 里面的每个 RDD 执行 func |
4. Spark Streaming 完成实时需求
1) WordCount
首先在 linux 服务器上安装 nc 工具
nc 是 netcat 的简称,原本是用来设置路由器,我们可以利用它向某个端口发送数据 yum install -y nc
启动一个服务端并开放 9999 端口,等一下往这个端口发数据
nc -lk 9999
发送数据
接收数据,代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.streaming.{Seconds, StreamingContext} object WordCount { def main(args: Array[String]): Unit = { //1.创建StreamingContext //spark.master should be set as local[n], n > 1 val conf = new SparkConf().setAppName("wc").setMaster("local[*]") val sc = new SparkContext(conf) sc.setLogLevel("WARN") val ssc = new StreamingContext(sc,Seconds(5))//5表示5秒中对数据进行切分形成一个RDD //2.监听Socket接收数据 //ReceiverInputDStream就是接收到的所有的数据组成的RDD,封装成了DStream,接下来对DStream进行操作就是对RDD进行操作 val dataDStream: ReceiverInputDStream[String] = ssc.socketTextStream("node01",9999) //3.操作数据 val wordDStream: DStream[String] = dataDStream.flatMap(_.split(" ")) val wordAndOneDStream: DStream[(String, Int)] = wordDStream.map((_,1)) val wordAndCount: DStream[(String, Int)] = wordAndOneDStream.reduceByKey(_+_) wordAndCount.print() ssc.start()//开启 ssc.awaitTermination()//等待停止 } } |
2) updateStateByKey
- 问题:
在上面的那个案例中存在这样一个问题:
每个批次的单词次数都被正确的统计出来,但是结果不能累加!
如果需要累加需要使用 updateStateByKey(func)来更新状态。
代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.{SparkConf, SparkContext} object WordCount2 { def main(args: Array[String]): Unit = { //1.创建StreamingContext //spark.master should be set as local[n], n > 1 val conf = new SparkConf().setAppName("wc").setMaster("local[*]") val sc = new SparkContext(conf) sc.setLogLevel("WARN") val ssc = new StreamingContext(sc,Seconds(5))//5表示5秒中对数据进行切分形成一个RDD //requirement failed: ....Please set it by StreamingContext.checkpoint(). //注意:我们在下面使用到了updateStateByKey对当前数据和历史数据进行累加 //那么历史数据存在哪?我们需要给他设置一个checkpoint目录 ssc.checkpoint("./wc")//开发中HDFS //2.监听Socket接收数据 //ReceiverInputDStream就是接收到的所有的数据组成的RDD,封装成了DStream,接下来对DStream进行操作就是对RDD进行操作 val dataDStream: ReceiverInputDStream[String] = ssc.socketTextStream("node01",9999) //3.操作数据 val wordDStream: DStream[String] = dataDStream.flatMap(_.split(" ")) val wordAndOneDStream: DStream[(String, Int)] = wordDStream.map((_,1)) //val wordAndCount: DStream[(String, Int)] = wordAndOneDStream.reduceByKey(_+_) //====================使用updateStateByKey对当前数据和历史数据进行累加==================== val wordAndCount: DStream[(String, Int)] =wordAndOneDStream.updateStateByKey(updateFunc) wordAndCount.print() ssc.start()//开启 ssc.awaitTermination()//等待优雅停止 } //currentValues:当前批次的value值,如:1,1,1 (以测试数据中的hadoop为例) //historyValue:之前累计的历史值,第一次没有值是0,第二次是3 //目标是把当前数据+历史数据返回作为新的结果(下次的历史数据) def updateFunc(currentValues:Seq[Int], historyValue:Option[Int] ):Option[Int] ={ val result: Int = currentValues.sum + historyValue.getOrElse(0) Some(result) } } |
3) reduceByKeyAndWindow
使用上面的代码已经能够完成对所有历史数据的聚合,但是实际中可能会有一些需求,需要对指定时间范围的数据进行统计。
比如:
百度/微博的热搜排行榜 统计最近 24 小时的热搜词,每隔 5 分钟更新一次,所以面对这样的需求我们需要使用窗口操作 Window Operations。
图解:
我们先提出一个问题:统计经过某红绿灯的汽车数量之和?
假设在一个红绿灯处,我们每隔 15 秒统计一次通过此红绿灯的汽车数量,如下图: 可以把汽车的经过看成一个流,无穷的流,不断有汽车经过此红绿灯,因此无法统计总共的汽车数量。但是,我们可以换一种思路,每隔 15 秒,我们都将与上一次的结果进行 sum 操作(滑动聚合, 但是这个结果似乎还是无法回答我们的问题,根本原因在于流是无界的,我们不能限制流,但可以在有一个有界的范围内处理无界的流数据。
可以把汽车的经过看成一个流,无穷的流,不断有汽车经过此红绿灯,因此无法统计总共的汽车数量。但是,我们可以换一种思路,每隔 15 秒,我们都将与上一次的结果进行 sum 操作(滑动聚合, 但是这个结果似乎还是无法回答我们的问题,根本原因在于流是无界的,我们不能限制流,但可以在有一个有界的范围内处理无界的流数据。
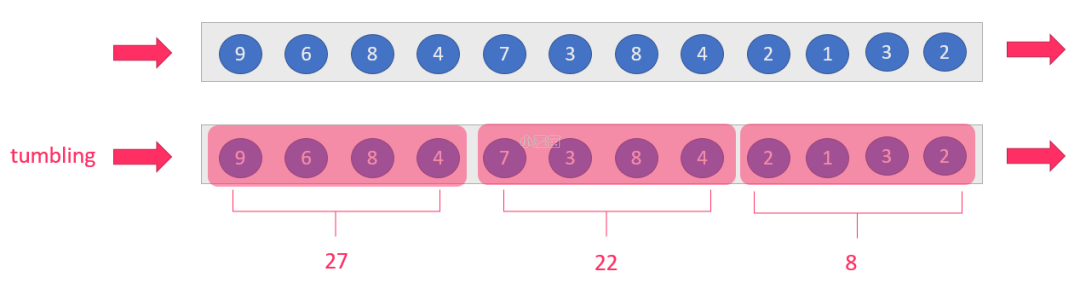
因此,我们需要换一个问题的提法:每分钟经过某红绿灯的汽车数量之和?
这个问题,就相当于一个定义了一个 Window(窗口),window 的界限是 1 分钟,且每分钟内的数据互不干扰,因此也可以称为翻滚(不重合)窗口,如下图:
第一分钟的数量为 8,第二分钟是 22,第三分钟是 27。。。这样,1 个小时内会有 60 个 window。
再考虑一种情况,每 30 秒统计一次过去 1 分钟的汽车数量之和: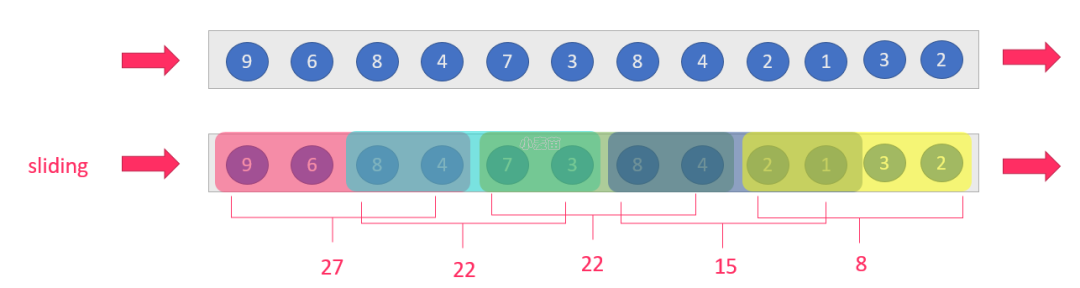 此时,window 出现了重合。这样,1 个小时内会有 120 个 window。
此时,window 出现了重合。这样,1 个小时内会有 120 个 window。
滑动窗口转换操作的计算过程如下图所示:

我们可以事先设定一个滑动窗口的长度(也就是窗口的持续时间),并且设定滑动窗口的时间间隔(每隔多长时间执行一次计算),
比如设置滑动窗口的长度(也就是窗口的持续时间)为 24H,设置滑动窗口的时间间隔(每隔多长时间执行一次计算)为 1H
那么意思就是:每隔 1H 计算最近 24H 的数据
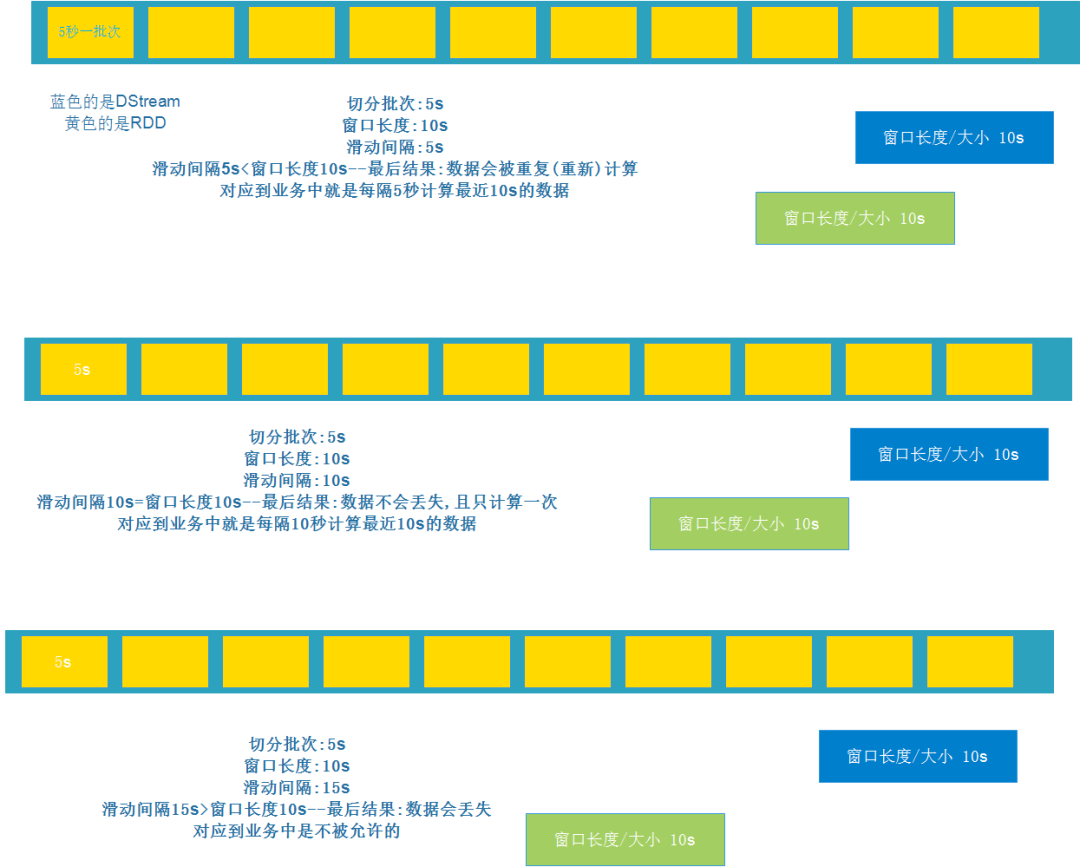
代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.{SparkConf, SparkContext} object WordCount3 { def main(args: Array[String]): Unit = { //1.创建StreamingContext //spark.master should be set as local[n], n > 1 val conf = new SparkConf().setAppName("wc").setMaster("local[*]") val sc = new SparkContext(conf) sc.setLogLevel("WARN") val ssc = new StreamingContext(sc,Seconds(5))//5表示5秒中对数据进行切分形成一个RDD //2.监听Socket接收数据 //ReceiverInputDStream就是接收到的所有的数据组成的RDD,封装成了DStream,接下来对DStream进行操作就是对RDD进行操作 val dataDStream: ReceiverInputDStream[String] = ssc.socketTextStream("node01",9999) //3.操作数据 val wordDStream: DStream[String] = dataDStream.flatMap(_.split(" ")) val wordAndOneDStream: DStream[(String, Int)] = wordDStream.map((_,1)) //4.使用窗口函数进行WordCount计数 //reduceFunc: (V, V) => V,集合函数 //windowDuration: Duration,窗口长度/宽度 //slideDuration: Duration,窗口滑动间隔 //注意:windowDuration和slideDuration必须是batchDuration的倍数 //windowDuration=slideDuration:数据不会丢失也不会重复计算==开发中会使用 //windowDuration>slideDuration:数据会重复计算==开发中会使用 //windowDuration<slideDuration:数据会丢失 //下面的代码表示: //windowDuration=10 //slideDuration=5 //那么执行结果就是每隔5s计算最近10s的数据 //比如开发中让你统计最近1小时的数据,每隔1分钟计算一次,那么参数该如何设置? //windowDuration=Minutes(60) //slideDuration=Minutes(1) val wordAndCount: DStream[(String, Int)] = wordAndOneDStream.reduceByKeyAndWindow((a:Int,b:Int)=>a+b,Seconds(10),Seconds(5)) wordAndCount.print() ssc.start()//开启 ssc.awaitTermination()//等待优雅停止 } } |
五、Structured Streaming
在 2.0 之前,Spark Streaming 作为核心 API 的扩展,针对实时数据流,提供了一套可扩展、高吞吐、可容错的流式计算模型。Spark Streaming 会接收实时数据源的数据,并切分成很多小的 batches,然后被 Spark Engine 执行,产出同样由很多小的 batchs 组成的结果流。本质上,这是一种 micro-batch(微批处理)的方式处理,用批的思想去处理流数据.这种设计让Spark Streaming 面对复杂的流式处理场景时捉襟见肘。
spark streaming 这种构建在微批处理上的流计算引擎,比较突出的问题就是处理延时较高(无法优化到秒以下的数量级),以及无法支持基于 event_time 的时间窗口做聚合逻辑。
spark 在 2.0 版本中发布了新的流计算的 API,Structured Streaming/结构化流。
Structured Streaming 是一个基于 Spark SQL 引擎的可扩展、容错的流处理引擎。统一了流、批的编程模型,你可以使用静态数据批处理一样的方式来编写流式计算操作。并且支持基于 event_time 的时间窗口的处理逻辑。
随着数据不断地到达,Spark 引擎会以一种增量的方式来执行这些操作,并且持续更新结算结果。可以使用 Scala、Java、Python 或 R 中的 DataSet/DataFrame API 来表示流聚合、事件时间窗口、流到批连接等。此外,Structured Streaming 会通过 checkpoint 和预写日志等机制来实现 Exactly-Once 语义。
简单来说,对于开发人员来说,根本不用去考虑是流式计算,还是批处理,只要使用同样的方式来编写计算操作即可,Structured Streaming 提供了快速、可扩展、容错、端到端的一次性流处理,而用户无需考虑更多细节。
默认情况下,结构化流式查询使用微批处理引擎进行处理,该引擎将数据流作为一系列小批处理作业进行处理,从而实现端到端的延迟,最短可达 100 毫秒,并且完全可以保证一次容错。自 Spark 2.3 以来,引入了一种新的低延迟处理模式,称为连续处理,它可以在至少一次保证的情况下实现低至 1 毫秒的端到端延迟。也就是类似于 Flink 那样的实时流,而不是小批量处理。实际开发可以根据应用程序要求选择处理模式,但是连续处理在使用的时候仍然有很多限制,目前大部分情况还是应该采用小批量模式。
1. API
Spark Streaming 时代 -DStream-RDD
Spark Streaming 采用的数据抽象是 DStream,而本质上就是时间上连续的 RDD,对数据流的操作就是针对 RDD 的操作。

Structured Streaming 时代 - DataSet/DataFrame -RDD
Structured Streaming 是 Spark2.0 新增的可扩展和高容错性的实时计算框架,它构建于 Spark SQL 引擎,把流式计算也统一到 DataFrame/Dataset 里去了。
Structured Streaming 相比于 Spark Streaming 的进步就类似于 Dataset 相比于 RDD 的进步。
2. 核心思想
Structured Streaming 最核心的思想就是将实时到达的数据看作是一个不断追加的 unbound table 无界表,到达流的每个数据项(RDD)就像是表中的一个新行被附加到无边界的表中.这样用户就可以用静态结构化数据的批处理查询方式进行流计算,如可以使用 SQL 对到来的每一行数据进行实时查询处理。
3. 应用场景
Structured Streaming 将数据源映射为类似于关系数据库中的表,然后将经过计算得到的结果映射为另一张表,完全以结构化的方式去操作流式数据,这种编程模型非常有利于处理分析结构化的实时数据;
4. Structured Streaming 实战
1) 读取 Socket 数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | import org.apache.spark.SparkContext import org.apache.spark.sql.streaming.Trigger import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession} object WordCount { def main(args: Array[String]): Unit = { //1.创建SparkSession,因为StructuredStreaming的数据模型也是DataFrame/DataSet val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("WARN") //2.接收数据 val dataDF: DataFrame = spark.readStream .option("host", "node01") .option("port", 9999) .format("socket") .load() //3.处理数据 import spark.implicits._ val dataDS: Dataset[String] = dataDF.as[String] val wordDS: Dataset[String] = dataDS.flatMap(_.split(" ")) val result: Dataset[Row] = wordDS.groupBy("value").count().sort($"count".desc) //result.show() //Queries with streaming sources must be executed with writeStream.start(); result.writeStream .format("console")//往控制台写 .outputMode("complete")//每次将所有的数据写出 .trigger(Trigger.ProcessingTime(0))//触发时间间隔,0表示尽可能的快 //.option("checkpointLocation","./ckp")//设置checkpoint目录,socket不支持数据恢复,所以第二次启动会报错,需要注掉 .start()//开启 .awaitTermination()//等待停止 } } |
2) 读取目录下文本数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | import org.apache.spark.SparkContext import org.apache.spark.sql.streaming.Trigger import org.apache.spark.sql.types.StructType import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession} /** * {"name":"json","age":23,"hobby":"running"} * {"name":"charles","age":32,"hobby":"basketball"} * {"name":"tom","age":28,"hobby":"football"} * {"name":"lili","age":24,"hobby":"running"} * {"name":"bob","age":20,"hobby":"swimming"} * 统计年龄小于25岁的人群的爱好排行榜 */ object WordCount2 { def main(args: Array[String]): Unit = { //1.创建SparkSession,因为StructuredStreaming的数据模型也是DataFrame/DataSet val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("WARN") val Schema: StructType = new StructType() .add("name","string") .add("age","integer") .add("hobby","string") //2.接收数据 import spark.implicits._ // Schema must be specified when creating a streaming source DataFrame. val dataDF: DataFrame = spark.readStream.schema(Schema).json("D:\\data\\spark\\data") //3.处理数据 val result: Dataset[Row] = dataDF.filter($"age" < 25).groupBy("hobby").count().sort($"count".desc) //4.输出结果 result.writeStream .format("console") .outputMode("complete") .trigger(Trigger.ProcessingTime(0)) .start() .awaitTermination() } } |
3) 计算操作
获得到 Source 之后的基本数据处理方式和之前学习的 DataFrame、DataSet 一致,不再赘述。
官网示例代码:
1 2 3 4 5 6 7 8 9 10 11 | case class DeviceData(device: String, deviceType: String, signal: Double, time: DateTime) val df: DataFrame = ... // streaming DataFrame with IOT device data with schema { device: string, deviceType: string, signal: double, time: string } val ds: Dataset[DeviceData] = df.as[DeviceData] // streaming Dataset with IOT device data // Select the devices which have signal more than 10 df.select("device").where("signal > 10") // using untyped APIs ds.filter(_.signal > 10).map(_.device) // using typed APIs // Running count of the number of updates for each device type df.groupBy("deviceType").count() // using untyped API // Running average signal for each device type import org.apache.spark.sql.expressions.scalalang.typed ds.groupByKey(_.deviceType).agg(typed.avg(_.signal)) // using typed API |
4) 输出
计算结果可以选择输出到多种设备并进行如下设定:
- output mode:以哪种方式将 result table 的数据写入 sink,即是全部输出 complete 还是只输出新增数据;
- format/output sink 的一些细节:数据格式、位置等。如 console;
- query name:指定查询的标识。类似 tempview 的名字;
- trigger interval:触发间隔,如果不指定,默认会尽可能快速地处理数据;
- checkpointLocation:一般是 hdfs 上的目录。注意:Socket 不支持数据恢复,如果设置了,第二次启动会报错,Kafka 支持。
output mode:
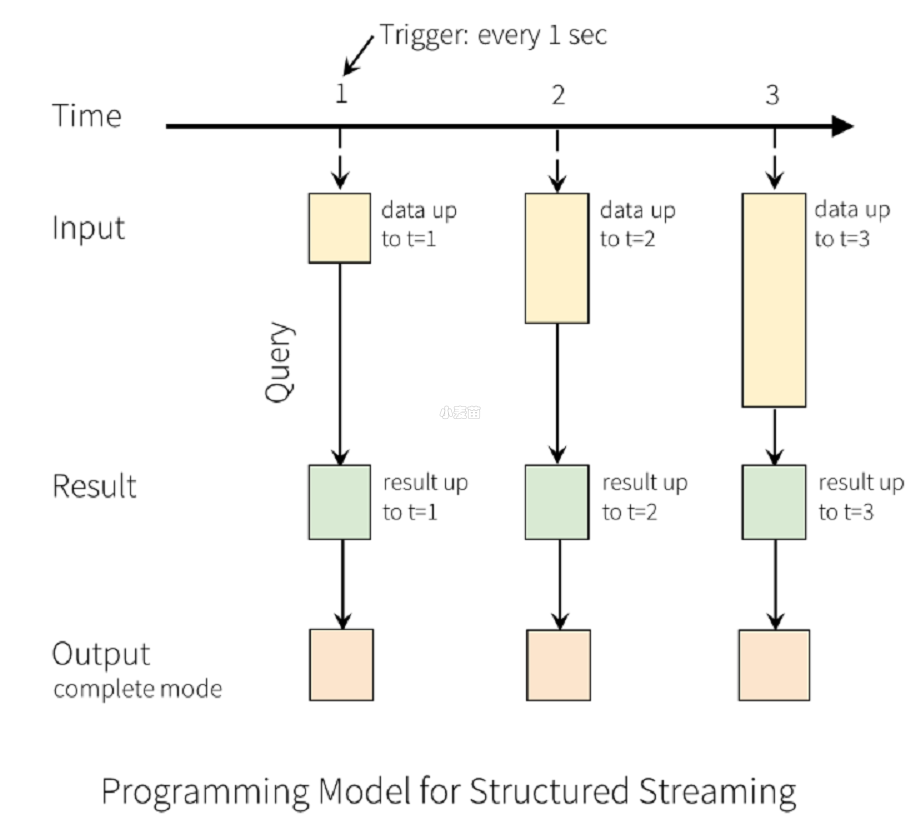
每当结果表更新时,我们都希望将更改后的结果行写入外部接收器。
这里有三种输出模型:
- Append mode:默认模式,新增的行才输出,每次更新结果集时,只将新添加到结果集的结果行输出到接收器。仅支持那些添加到结果表中的行永远不会更改的查询。因此,此模式保证每行仅输出一次。例如,仅查询 select,where,map,flatMap,filter,join 等会支持追加模式。不支持聚合
- Complete mode:所有内容都输出,每次触发后,整个结果表将输出到接收器。聚合查询支持此功能。仅适用于包含聚合操作的查询。
- Update mode:更新的行才输出,每次更新结果集时,仅将被更新的结果行输出到接收器(自 Spark 2.1.1 起可用),不支持排序
output sink:

- 说明:
File sink:输出存储到一个目录中。支持 parquet 文件,以及 append 模式。
1 2 3 4 | writeStream .format("parquet") // can be "orc", "json", "csv", etc. .option("path", "path/to/destination/dir") .start() |
Kafka sink:将输出存储到 Kafka 中的一个或多个 topics 中。
1 2 3 4 5 | writeStream .format("kafka") .option("kafka.bootstrap.servers", "host1:port1,host2:port2") .option("topic", "updates") .start() |
Foreach sink:对输出中的记录运行任意计算