
合 Greenplum中的数据加载工具之gpfdist和gpload
Tags: GreenPlumgploadgpfdist数据加载
- 装载数据概述
- 简介
- 带列值的INSERT语句
- COPY语句
- 外部表
- 使用gpfdist外部表
- gpload
- 装载数据最佳实践
- gpfdist
- 概要
- 描述
- 选项
- 注解
- 示例
- gpload
- 概要
- 先决条件
- 描述
- 选项
- 控制文件格式
- 日志文件格式
- 注解
- 示例
- gpfdist和gpload的区别
- 使用gpfdist和gpload转换外部数据
- 关于gpfdist转换
- 确定转换方案
- 编写转换
- 编写gpfdist配置文件
- 传输数据
- 用GPLOAD转换
- 用INSERT INTO SELECT FROM转换
- 配置文件格式
- XML转换示例
- 基于命令的外部Web表
- IRS MeF XML 文件(在demo目录中)
- WITSML™ 文件 (在demo目录中)
- gpfdist示例
- 创建实验环境
- gpfdist加载数据
- 卸载数据
- gpload示例
- 创建实验环境
- 创建YAML格式控制文件
- 数据装载性能技巧
- 权限
- 错误
- hostname cannot be resolved 'gpfdist:/app3:8000//tmp/np_data.csv' (seg2 slice1 12.168.24.27:6002 pid=406768)
- UnboundLocalError: local variable 'has_seq_bool' referenced before assignmen
- 总结
- 参考
装载数据概述
简介
在GreenPlum中有以下几种方式来进行数据的加载,包括
- 通过insert命令来实现少量数据的导入;
- 通过copy命令来实现数据的导入导出;
- 通过建立外部表及gpfdist实现数据的导入导出;
- 通过gpload实现数据的导入;
注意:进行数据加载后,一个好的习惯是查看数据有没有倾斜。

带列值的INSERT语句
带有值的单个INSERT语句会向表中加入一行。这个行会流过master并且被分布到一个segment上。 这是最慢的方法并且不适合装载大量数据。
通过简单的insert语句来实现,常用于少量数据的导入,当数据量较大时,会很耗时,从而不适合使用。
1 | insert into tablename values('data'); |
COPY语句
PostgreSQL的COPY语句从外部文件拷贝数据到数据表中。它比INSERT 语句插入多行的效率更高,但是行仍需流过master。所有数据都在一个命令中被拷贝,它并不是一种并行处理。
对于数据加载,GreenPlum数据库提供copy工具,copy工具源于PostgreSQL数据库,copy命令支持文件与表之间的数据加载和表对文件的数据卸载。使用copy命令进行数据加载,数据需要经过Master节点分发到Segment节点,同样使用copy命令进行数据卸载,数据也需要由Segment发送到Master节点,由Master节点汇总后再写入外部文件。这样就限制了数据加载与卸载的效率,但是数据量较小的情况下,copy命令就非常方便。
COPY命令的数据输入来自于一个文件或者标准输入。例如:
1 | COPY table FROM '/data/mydata.csv' WITH CSV HEADER; |
使用COPY适合于增加相对较小的数据集合(例如多达上万行的维度表)或者一次性数据装载。
在编写脚本处理装载少于1万行的少量数据时使用COPY。
因为COPY是一个单一命令,在使用这种方法填充表时没有必要禁用自动提交。
使用者可以运行多个并发的COPY命令以提高性能。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | aalhr=## create table tbl_pay_log_copy (id int primary key,order_num varchar(100),accountid varchar(30),qn varchar(20),appid int,amount numeric(10,2),pay_time timestamp); aalhr=## \d tbl_pay_log_copy Table "public.tbl_pay_log_copy" Column | Type | Modifiers -----------+-----------------------------+----------- id | integer | not null order_num | character varying(100) | accountid | character varying(30) | qn | character varying(20) | appid | integer | amount | numeric(10,2) | pay_time | timestamp without time zone | Indexes: "tbl_pay_log_copy_pkey" PRIMARY KEY, btree (id), tablespace "tbs_aalhr" Distributed by: (id) Tablespace: "tbs_aalhr" [gpadmin@mdw ~]$ head ios_pay.txt 73,ysios_receipt_3793615cb10dc393bba87c82d3c6544f,27388062,yriu1244_16043_001,2616,98.00,2017-11-06 17:36:43 72,ysios_receipt_32946f3d37e774781babe103352bd230,27424976,yriu1244_16043_001,2616,30.00,2017-11-06 15:18:56 75,ysios_receipt_3e2e432550253450412692392c7675d0,27388294,yriu1244_16043_001,2616,98.00,2017-10-19 07:33:03 74,ysios_receipt_3793615cb10dc393bba87c82d3c6544f,27388062,yriu1244_16043_001,2616,98.00,2017-11-06 20:40:46 77,ysios_receipt_ee6bed338a32f836a999133cd2e6d547,27388294,yriu1244_16043_001,2616,98.00,2017-10-19 22:27:46 76,ysios_receipt_ae53b142924c0604820537d61a9dd73e,27424976,yriu1244_16043_001,2616,648.00,2017-10-19 12:10:17 79,ysios_receipt_30ec130bcdf0e864629d12f8392d4b43,27385229,yriu1244_16043_001,2616,98.00,2017-10-21 07:46:01 78,ysios_receipt_e2b62024f1b0c3a2c3aae1e80f126eb6,27387306,yriu1244_16043_001,2616,25.00,2017-10-20 01:54:24 81,ysios_receipt_3e72a8e32c9fee546ab08d103606e6cb,27424976,yriu1244_16043_001,2616,30.00,2017-10-21 13:55:54 80,ysios_receipt_6ca291884fcfe3d1583b49a3611b4ccc,27424976,yriu1244_16043_001,2616,25.00,2017-10-21 13:55:51 [gpadmin@mdw ~]$ wc -l ios_pay.txt 20027 ios_pay.txt [gpadmin@mdw ~]$ du -sh ios_pay.txt 1.9M ios_pay.txt |
外部表
外部表提供了对Greenplum数据库之外的数据来源的访问。可以用SELECT语句访问它们,外部表 通常被用于抽取、装载、转换(ELT)模式,这是一种抽取、转换、装载(ETL)模式的变种,这种模式可以利用 Greenplum数据库的快速并行数据装载能力。
通过ETL,数据被从其来源抽取,在数据库外部使用外部转换工具(Informatica或者Datastage)转换,然后 被装载到数据库中。
通过ELT,Greenplum外部表提供对外部来源中数据的访问,外部来源可以是只读文件(例如文本、CSV或者XML文件)、 Web服务器、Hadoop文件系统、可执行的OS程序或者Greenplum gpfdist文件服务器,这些在 下一节中描述。外部表支持选择、排序和连接这样的SQL操作,这样数据可以被同时装载和转换,或者被装载到一个 装载表并且在数据库内被转换成目标表。
外部表使用CREATE EXTERNAL TABLE语句定义,该语句有一个LOCATION 子句定义数据的位置以及一个FORMAT子句定义源数据的格式,这样系统才能够解析输入数据。 文件使用file://协议,并且文件必须位于一台segment主机上由Greenplum超级用户可访问 的位置。数据可以被分散在segment主机上,并且每台主机上的每个主segment有不超过一个文件。LOCATION 子句中列出的文件的数量是将并行读取该外部表的segment的数量。
使用gpfdist外部表
外部表提供了对Greenplum数据库之外的来源中数据的访问。可以用SELECT语句访问它们,外部表通常被用于抽取、装载、转换(ELT)模式,这是一种抽取、转换、装载(ETL)模式的变种,这种模式可以利用Greenplum数据库的快速并行数据装载能力。这是COPY命令不持有的。
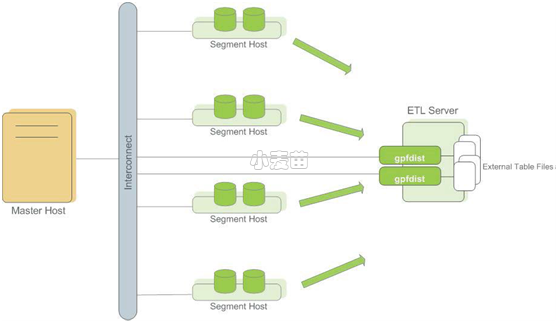
gpfdist原理:
gpfdist是一个使用HTTP协议的文件服务器程序,它以并行的方式向Greenplum数据库的Segment供应外部数据文件一个gpfdist实例,每秒能供应200MB并且很多gpfdist进程可以同时运行,每一个供应要被装载的数据的一部分。当使用者用INSERT INTO <table> SELECT * FROM <external_table>这样的语句开始装载时,INSERT语句会被Master解析并且分布给主Segment。Segment连接到gpfdist服务器并且并行检索数据,解析并验证数据,从分布键数据计算一个哈希值并且基于哈希键把行发送给它的目标Segment。每个gpfdist实例默认将接受最多64个来自Segment的连接。通过让许多Segment和gpfdist服务器参与到装载处理中,可以以非常高的速率被装载。
装载大型事实表的最快方式是使用基于gpfdist的外部表。gpfdist 是一个使用HTTP协议的文件服务器程序,它以并行的方式向Greenplum数据库的segment供应外部数据文件。 一个gpfdist实例每秒能供应200MB并且很多gpfdist进程可以 同时运行,每一个供应要被装载的数据的一部分。当使用者用INSERT INTO SELECT * FROM 这样的语句开始装载时,INSERT语句会被master解析并且分布给主segment。segment 连接到gpfdist服务器并且并行检索数据,解析并验证数据,从分布键数据计算一个哈希值 并且基于哈希键把行发送给它的目标segment。每个gpfdist实例默认将接受最多64个 来自segment的连接。通过让更多的segment和gpfdist服务器参与到装载处理中,可以 以非常高的速度进行数据装载。
在使用gpfdist数量达到配置参数gp_external_max_segments 的最大值时,主segment会并行访问外部文件。在优化gpfdist的性能时,随着 segment的数量增加会最大化并行性。在尽可能多的ETL节点上均匀地散布数据。将非常大型的数据文件 分解成相等的部分,并且把数据分散在尽可能多的文件系统上。
在每个文件系统上运行两个gpfdist实例。在装载数据时,gpfdist 在segment节点上容易变成CPU密集型的操作。举个例子,如果有八个机架的segment节点,在segment上就有大量 可用的CPU来驱动更多的gpfdist进程。在尽可能多的接口上运行gpfdist。 要注意绑定网卡并且确保启动足够的gpfdist实例配合它们一起工作。
有必要在所有这些资源上保持工作处于均衡状态。装载的速度与最慢的节点相同。装载文件布局上的倾斜将导致 整体装载受制于资源瓶颈。
gp_external_max_segs配置参数控制每个gpfdist进程能服务的 segment数量。默认值是64。使用者可以在saster上的postgresql.conf配置文件中设置 一个不同的值。总是保持gp_external_max_segs和gpfdist进程的 数量为一个偶因子,也就是说gp_external_max_segs值应该是gpfdist 进程数的倍数。例如,如果有12个segment和4个gpfdist进程,规划器会按照下面的方式循环分配segment连接:
1 2 3 4 5 6 7 8 9 10 11 12 | Segment 1 - gpfdist 1 Segment 2 - gpfdist 2 Segment 3 - gpfdist 3 Segment 4 - gpfdist 4 Segment 5 - gpfdist 1 Segment 6 - gpfdist 2 Segment 7 - gpfdist 3 Segment 8 - gpfdist 4 Segment 9 - gpfdist 1 Segment 10 - gpfdist 2 Segment 11 - gpfdist 3 Segment 12 - gpfdist 4 |
在装载到已有表之前删除索引,并且在装载之后重建索引。在装载完数据后重新创建索引比装载每行时增量更新 索引更快。
装载后在表上运行ANALYZE。在装载期间通过设置gp_autostats_mode 为NONE来禁用自动统计信息收集。在装载出错后运行VACUUM来回收空间。
对重度分区的列存表执行少量高频的数据装载可能会对系统有很大影响,因为在每个时间间隔内被访问的物理文件会很多。
gpload
gpload是一种数据装载工具,它扮演着Greenplum外部表并行装载特性的接口的角色。
要当心对gpload的使用,因为它会创建并且删除外部表,从而可能会导致系统目录膨胀。 可转而使用gpfdist,因为它能提供最好的性能。
gpload使用定义在一个YAML格式的控制文件中的规范来执行一次装载。它会执行下列操作:
- 调用gpfdist进程
- 基于定义的源数据创建一个临时的外部表定义
- 执行INSERT、UPDATE或者MERGE操作 将源数据载入数据库中的目标表
- 删除临时外部表
- 清除gpfdist进程
装载会在单个事务中完成。
装载数据最佳实践
在装载数据之前删掉现有表上的任何索引,并且在装载之后重建那些索引。新创建索引比装载每行时 增量更新索引更快。
在装载期间通过将gp_autostats_mode配置参数设置为NONE 禁用自动统计信息收集。
外部表并非为频繁访问或者ad hoc访问而设计。
外部表没有统计信息来告知优化器。可以用下面这样的语句在pg_class系统目录中为 外部表设置粗略的行数和磁盘页数估计:
1UPDATE pg_class SET reltuples=400000, relpages=400 WHERE relname='myexttable';在使用gpfdist时,通过为ETL服务器上的每一块NIC运行一个gpfdist 实例以最大化网络带宽。在gpfdist实例之间均匀地划分源数据。
在使用gpload时,在资源允许的情况下同时运行尽可能多的gpload 实例。利用可用的CPU、内存和网络资源以增加能从ETL服务器传输到Greenplum数据库的数据量。
使用COPY语句的SEGMENT REJECT LIMIT子句设置在 COPY FROM命令被中止之前可以出现错误的行的百分数限制。这个拒绝限制是针对每个 segment的,当任意一个segment超过该限制时,命令将被中止且不会有行被增加。使用LOG ERRORS 子句可以保存错误行。如果有一行在格式上有错误—例如缺少值或者有多余的值,或者数据类型不对— Greenplum数据库会在内部存储错误信息和行。使用内建SQL函数gp_read_error_log() 可以访问这种存储下来的信息。
如果装载出现错误,在该表上运行VACUUM以恢复空间。
在用户装载数据到表中后,在堆表(包括系统目录)上运行VACUUM,并且在所有的表上运行 ANALYZE。没有必要在追加优化表上运行VACUUM。如果表已经被分过区, 用户可以只清理和分析受数据装载影响的分区。这些步骤会清除来自于被中止的装载、删除或者更新中的行并且为表 更新统计信息。
在装载大量数据之后重新检查表中的segment倾斜。用户可以使用下面这样的查询来检查倾斜:
1SELECT gp_segment_id, count(*) FROM schema.table GROUP BY gp_segment_id ORDER BY 2;gpfdist默认假定最大记录尺寸为32K。要装载大于32K的数据记录,用户必须通过在 gpfdist命令行上指定-m <bytes选项来增加最大行 尺寸参数。如果用户使用的是gpload,在gpload控制文件中设置 MAX_LINE_LENGTH参数。
Note: 与Informatica Power Exchange的集成当前被限制为默认的32K记录长度。
gpfdist
将数据文件载入Greenplum数据库Segment或从其中写出数据文件到文件系统。
概要
1 2 3 4 5 6 | gpfdist [-d directory] [-p http_port] [-P last_http_port] [-l log_file] [-t timeout] [-S] [-w time] [-v | -V] [-s] [-m max_length] [--ssl certificate_path [--sslclean wait_time] ] [-c config.yml] gpfdist -? | --help gpfdist --version |
描述
gpfdist是Greenplum数据库并行文件分发程序。它可以被外部表和gpload 用来并行地将外部表文件提供给所有的Greenplum数据库Segment。它由可写外部表使用,并行接受来自Greenplum数据库 Segment的输出流,并将它们写出到文件中。
Note: gpfdist和gpload是在Greenplum的主版本级别有效的。 例如,Greenplum 4.x版本的gpfdist不能用于Greenplum 5.x或6.x版本。
为了使外部表使用gpfdist,外部表定义的LOCATION子句必须使用 gpfdist://协议(参见Greenplum数据库命令CREATE EXTERNAL TABLE)。
Note: 如果--ssl选项被指定来启用SSL安全性,请使用gpfdists://协议创建外部表。
使用gpfdist的好处是在读取或写入外部表时可以保证最大的并行性,从而提供最佳的性能, 并且更容易管理外部表。
对于只读外部表,当用户在外部表中SELECT时,gpfdist 将数据文件均匀地分析并提供给Greenplum数据库系统的所有Segment实例。对于可写的外部表, gpfdist在用户INSERT外部表时接受来自Segment的 并行输出流,并写入输出文件。
对于可读外部表,如果被加载的文件使用gzip或bzip2 (具有.gz或.bz2的文件扩展名),gpfdist 会在装载之前自动解压文件,前提是gunzip或bunzip2在用户的 可执行文件路径中。
Note: 目前,可读外部表不支持在Windows平台上的压缩,可写外部表不支持任何平台上的压缩。
当使用gpfdist或gpfdists协议读写数据时,Greenplum数据库 在HTTP请求头部中包含X-GP-PROTO,以指示该请求来自Greenplum数据库。该工具拒绝 请求头部中不包含X-GP-PROTO的HTTP请求。
大多数情况下,用户很可能希望在ETL机器而不是安装Greenplum数据库的主机上运行gpfdist。 要在其他主机上安装gpfdist,只需简单的将该程序复制到该主机上,然后将gpfdist 添加到用户的$PATH路径中。
Note: 使用IPv6时,请始终将数字IP地址包裹在括号内。
选项
-d directory
指定一个目录,gpfdist将从该目录中为可读外部表提供文件,或为可写外部表创建 输出文件。如果没有指定,默认为当前目录。
-l log_file
要记录标准输出消息的完全限定路径和日志文件名称。
-p http_port
gpfdist提供文件要使用的HTTP端口。默认为8080。
-P last_http_port
gpfdist将会提供文件服务的端口号范围 (http_port到last_http_port 包含岂止号码)中最后一个HTTP端口号号码。gpfdist会 以端口号设定范围内第一个成功绑定的端口号作为服务端口。
-t timeout
设置Greenplum数据库建立与gpfdist进程的连接所允许的时间。默认值是5秒。 允许的值是2到7200秒(2小时)。在网络流量大的系统上可能要增加。
-m max_length
设置以字节为单位的最大数据行长度。默认值是32768。当用户数据包含非常宽的行时 (或者当line too long错误消息发生时)应该使用,否则不应该使用, 因为它会增加资源分配。有效范围是32K到256MB(Windows系统上限为1MB)。
Note: 如果用户指定较大的最大行长度并运行大量的gpfdist并发连接, 则可能会发生内存问题。例如,使用96个并行gpfdist进程需要大约 24GB的内存((96 + 1) x 246MB)。
-s
启用简化的日志记录。指定此选项时,只有具有WARN级别或者更高级别的消息才 会写入gpfdist日志文件。INFO级别的消息不写入日志文件。 如果未指定这一选项,则所有gpfdist消息都写入日志文件。
用户可以指定此选项以减少写入日志文件的信息。
-S (use O_SYNC)
使用O_SYNC标志打开同步I/O的文件。任何对结果文件描述的写都会阻塞gpfdist, 直到数据被物理地写到底层硬件。
-w time
设置关闭目标文件(如命名管道)之前Greenplum数据库延迟的秒数。 默认值是0,没有延迟。最大值是7200秒(2小时)。
对于具有多个Segment的Greenplum数据库,在将不同Segment中的数据写入文件时,Segment之间可能会有延迟。 用户可以指定Greenplum数据库关闭文件之前要等待的时间,以确保所有数据都被写入文件。
--ssl certificate_path
将SSL加密添加到使用gpfdist传输的数据。使用--ssl certificate_path选项执行gpfdist之后, 从此文件服务器加载数据的唯一方法是使用gpfdist://协议。 有关gpfdist:// 协议的信息,请参阅Greenplum数据库管理员指南中的“装载和卸载数据”部分。
在certificate_path中指定的位置必须包含以下文件:
- 服务器证书文件,server.crt
- 服务器私钥文件,server.key
- 可信证书机构,root.crt
根目录(/)不能指定为certificate_path。
--sslclean wait_time
使用--ssl选项运行该工具时,设置该工具完成向Greenplum数据库Segment读写数据 后关闭SSL会话和清除SSL资源之前要延迟的秒数。默认值是0,没有延迟。最大值是500秒。如果延迟增加, 传输速度降低。
在某些情况下,复制大量数据时可能会发生此错误:gpfdist server closed connection。 为了避免这类错误,用户可以增加一个延迟,例如--sslclean 5。
-c config.yaml
指定gpfdist在装载或抽取数据时,用来选择要应用的转换的规则。 gpfdist配置文件是一个YAML1.1文档。
有关文件格式的信息,请参阅Greenplum数据库管理员指南中的配置文件格式配置件格式。 有关用gpfdist配置数据转换的信息,请参阅Greenplum数据库管理员指南 中的使用gpfdist和gpload转换外部数据转换XML数据。
该选项在windows平台中不可用。
-v(详细模式)
显示进度和状态信息的详细模式。
-V(非常详细模式)
显示由该工具生成的所有输出信息的详细模式。
-?(帮助)
显示在线帮助。
--version
显示该工具的版本。
注解
服务器配置文件verify_gpfdists_cert用来控制Greenplum数据库与gpfdist 工具沟通进行读写数据时是否启用SSL授权。当在进行Greenplum数据库外部表与gpfdist 工具测试时,客户可以设置该参数值为false来禁用授权。如果参数设置为false, 以下SSL异常会被忽略:
- gpfdist使用的自有签名SSL证书授权不被Greenplum信任。
- SSL证书中包含的主机名与gpfdist主机名不匹配。
Warning: 禁用SSL证书授权会暴露安全风险,因为gpfdist SSL不会再进行验证。
如果gpfdist工具在读写操作中hang住,客户可以在下次hang住时生成一个 core dump文件来帮助调试问题原因。在gpfdist强制退出之前, 设置环境变量GPFDIST_WATCHDOG_TIMER为异常时间段的秒数。 当客户设置了该环境变量,并且gpfdist hang住时,工具会在特定秒数后停止并创建 core dump文件,发送相关信息到日志文件。
例子中设置的Linux系统环境变量为gpfdist在无活动操作后300秒(5分钟)退出。
1 | export GPFDIST_WATCHDOG_TIMER=300 |
示例
使用端口8081从指定目录提供文件(并在后台启动gpfdist):
1 | gpfdist -d /var/load_files -p 8081 & |
在后台启动gpfdist并将输出和错误重定向到日志文件:
1 | gpfdist -d /var/load_files -p 8081 -l /home/gpadmin/log & |
停止在后台运行的gpfdist:
--首先找到它的进程ID:
1 | ps ax | grep gpfdist |
--然后杀死该进程,例如:
1 | kill 3456 |
gpload
按照一个YAML格式的控制文件的定义运行一个装载作业。
Greenplum的gpload工具使用可读外部表和Greenplum并行文件服务器(gpfdist或者gpfdists)来装载数据。它处理并行的基于文件的外部表设置并且允许用户在一个单一配置文件中配置他们的数据格式、外部表定义以及gpfdist或者gpfdists设置。
Note: gpfdist和gpload仅与发布它们的Greenplum数据库主要版本兼容。 例如,与Greenplum Database 4.x一起安装的gpfdist实用程序不能与Greenplum Database 5.x或6.x一起使用。
Note: 如果目标表列名是保留关键字,即包含大写字母,或者包含需要引号(“”)来标识列的任何字符,则不支持MERGE和UPDATE操作。
概要
1 2 3 4 5 | gpload -f control_file [-l log_file] [-h hostname] [-p port] [-U username] [-d database] [-W] [--gpfdist_timeout seconds] [--no_auto_trans] [[-v | -V] [-q]] [-D] gpload -? gpload --version |
先决条件
要执行gpload命令的客户机必须具有下列要求:
Python 2.6.2或更新版本,装有pygresql (Python的PostgreSQL接口包 ),和pyyaml。注意Python及所需的Python库被包含在Greenplum数据库安装包中, 因此如果在gpload运行的机器上安装有Greenplum数据库,用户就不需要单独安装Python。
Note: Greenplum数据库的Windows装载客户端仅支持Python 2.5(您可以从https://www.python.org获取)
。
gpfdist并行文件分发程序被安装在$PATH中。这个程序位于Greenplum 数据库的$GPHOME/bin目录下。
gpload客户机可以访问(被访问)Greenplum数据库集群(Master和Segments)中所有主机。
gpload客户及可以访问(被访问)所有可能用来装载数据的主机(ETL服务器)。
描述
gpload是一个数据装载工具,它扮演着Greenplum数据库外部表并行装载 特性的接口的角色。通过一个用YAML格式控制文件定义的装载说明,gpload 调用Greenplum数据库的并行文件服务器 (gpfdist)执行 文件装载,基于源数据的定义创建一个外部表定义,并且指定INSERT、 UPDATE或MERGE操作把源数据装载到数据库中的目标表中。
Note: gpfdist和gpload是在Greenplum的主版本级别有效的。 例如,Greenplum 4.x版本的gpfdist不能用于Greenplum 5.x或6.x版本。
Note: 如果目标表的列名为保留关键字、有大写字母或包含任何双引号, 那么MERGE和UPDATE操作不被支持。
在目标表上指定多个同时的装载操作时,操作包括在YAML控制文件(控制文件格式见控制文件格式)的SQL集合中指定的任何SQL命令会在单个事务中 执行以防止数据不一致。
选项
-f control_file
必选项。包含装载说明详情的YAML文件。请见 控制文件格式。
--gpfdist_timeout seconds
为gpfdist并行文件分发程序发送响应设置超时时间。 输入一个从0到30秒的值(输入”0”会禁用超时)。 注意在高流量网络上可能需要增加这个值。
-l log_file
指定在哪里写日志文件。默认是~/gpAdminLogs/gpload_YYYYMMDD。 有关日志文件的更多信息请见日志文件格式。
--no_auto_trans
如果用户在目标表上执行单个装载操作,可指定--no_auto_trans 禁用把装载操作作为单个事务处理的特性。
默认情况下,在一个目标表上执行多个同时的操作时,gpload把每个装载操作处理为 单个事务以防止不一致的数据。
-q (无屏幕输出)
运行在静默模式中。命令输出不会被显示在屏幕上,但仍将被写入到日志文件。
-D (调试模式)
检查错误情况,但是不执行装载。
-v (详细模式)
在装载步骤被执行时,显示它们的详细输出。
-V (非常详细模式)
显示非常详细的输出。
-? (显示帮助)
显示帮助,然后退出。
--version
显示这个工具的版本,然后退出。
连接选项
-d database
要装载到的数据库。如果没有指定,则从装载控制文件、环境变量$PGDATABASE 读取或者默认为当前系统用户名。
-h hostname
指定Greenplum的Master数据库服务器在其上运行的机器的主机名。如果没有指定, 会从装载控制文件、环境变量$PGHOST读取或者默认为 localhost。
-p port
指定Greenplum的Master数据库服务器在其上监听连接的TCP端口。如果没有指定, 会从装载控制文件、环境变量$PGPORT读取或者默认为5432。
-U username
要用其进行连接的数据库角色名。如果没有指定,会从装载控制文件、环境变量$PGUSER 读取或者默认为当前系统用户名。
-W (强制口令提示)
强制口令提示。如果没有指定,会从环境变量$PGPASSWORD、 $PGPASSFILE指定的口令文件或~/.pgpass 中的口令文件中读取口令。如果这些都没有设置,即使没有提供-W, gpload也将提示要求一个口令。
控制文件格式
gpload控制文件使用 YAML 1.1 文档格式,然后为定义Greenplum数据库装载操作的多个步骤实现了其自身的模式。 该控制文件必须是一个有效的YAML文档。
gpload程序按顺序处理控制文件文档并且使用缩进(空格)来判断文档层次以及 各个部分之间的关系。空格的使用是有意义的。不能把空格简单地用于格式化目的,并且不能使用制表符。
一个装载控制文件的基础结构是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | --- VERSION: 1.0.0.1 DATABASE: db_name USER: db_username HOST: master_hostname PORT: master_port GPLOAD: INPUT: - SOURCE: LOCAL_HOSTNAME: - hostname_or_ip PORT: http_port | PORT_RANGE: [start_port_range, end_port_range] FILE: - /path/to/input_file SSL: true | false CERTIFICATES_PATH: /path/to/certificates - FULLY_QUALIFIED_DOMAIN_NAME: true | false - COLUMNS: - field_name: data_type - TRANSFORM: 'transformation' - TRANSFORM_CONFIG: 'configuration-file-path' - MAX_LINE_LENGTH: integer - FORMAT: text | csv - DELIMITER: 'delimiter_character' - ESCAPE: 'escape_character' | 'OFF' - NULL_AS: 'null_string' - FORCE_NOT_NULL: true | false - QUOTE: 'csv_quote_character' - HEADER: true | false - ENCODING: database_encoding - ERROR_LIMIT: integer - LOG_ERRORS: true | false EXTERNAL: - SCHEMA: schema | '%' OUTPUT: - TABLE: schema.table_name - MODE: insert | update | merge - MATCH_COLUMNS: - target_column_name - UPDATE_COLUMNS: - target_column_name - UPDATE_CONDITION: 'boolean_condition' - MAPPING: target_column_name: source_column_name | 'expression' PRELOAD: - TRUNCATE: true | false - REUSE_TABLES: true | false - STAGING_TABLE: external_table_name - FAST_MATCH: true | false SQL: - BEFORE: "sql_command" - AFTER: "sql_command" |
VERSION
可选。gpload控制文件模式的版本。当前版本是1.0.0.1。
DATABASE
可选。指定Greenplum数据库系统要连接到哪个数据库。如果没有指定则默认为$PGDATABASE。 如果$PGDATABASE也没有设置,则默认为当前系统用户名。用户还可以在命令行上用 -d选项指定数据库。
USER
可选。指定用于连接的数据库角色。如果没有指定,默认为当前用户或者$PGUSER (如果设置)。用户还可以在命令行上用-U选项指定数据库角色。
如果运行gpload的用户不是Greenplum数据库的超级用户, 那么必须为该用户授予适当的权限。更多信息请见Greenplum数据库参考指南。
HOST
可选。指定Greenplum数据库的Master主机名。如果没有指定,默认为localhost或者 $PGHOST(如果设置)。用户还可以在命令行上用-h 选项指定Master主机名。
PORT
可选。指定Greenplum数据库的Master端口。如果没有指定,默认为5432或者 $PGPORT(如果设置)。用户还可以在命令行上用-p 选项指定Master端口。
GPLOAD
必需。开始装载说明部分。GPLOAD说明必须定义有一个INPUT 小节和一个OUTPUT小节。- INPUT
必需。定义要装载的输入数据的位置和格式。gpload 将在当前主机上启动gpfdist文件分布程序的一个或者更多 实例并且在Greenplum数据库中创建指向源数据的外部表定义。注意在其上运行 gpload的主机必须对所有的Greenplum数据库主机(Master和Segment) 通过网络可访问。- SOURCE
必需。INPUT说明的SOURCE块定义源文件的位置。 一个INPUT小节可以定义多个SOURCE块。每个定义 的SOURCE块对应于将在本地机器上启动的一个gpfdist文件分布程序的实例。 每个定义的SOURCE块必须有一个FILE说明。
更多关于使用gpfdist并行文件服务器和单个以及多个 gpfdist实例的信息,请见Greenplum数据库管理员指南 中的“装载和卸载数据”部分。
LOCAL_HOSTNAME
可选。指定gpload运行其上的本地机器 的主机名或者IP地址。如果这个机器被配置有多个网络接口卡(NICs), 用户可以指定每块NIC的主机名或者IP,以便允许网络流量同时使用所有的NIC。 默认是仅使用本地机器的主要主机名或者IP。
PORT
可选。指定gpfdist 文件分布程序应该使用的特定端口号。用户还可以提供一个PORT_RANGE 来从指定的范围中选择可用的端口。如果PORT和 PORT_RANGE同时被定义,那么PORT优先。 如果PORT和PORT_RANGE都没有定义, 默认为在8000和9000之间选择一个可用端口。
如果在LOCAL_HOSTNAME中声明多个主机名, 这个端口号被用于所有主机。如果用户想要使用所有的NICs装载一个给定目录位置的同一个 文件或者文件集合,这种配置就是用户想要的。
PORT_RANGE
可选。可被用来代替PORT提供一个端口号范围, gpload可以从其中为这个gpfdist 文件分布程序实例选择一个可用的端口。
FILE
必需。指定本地文件系统上的一个文件位置、命名管道或者目录位置, 其中包含要被装载的数据。用户可以声明多于一个文件, 只要所有指定文件中数据的格式相同。
如果这些文件被使用gzip或者bzip2 (有.gz或者.bz2文件扩展名)压缩, 这些文件将被自动解压缩(在用户路径中有gunzip或者 bunzip2)。
在指定要装载哪些源文件时,用户可以使用通配符(*) 或其他C风格的模式匹配来指示多个文件。被指定的文件假定在相对于gpload 被执行的当前目录的位置(或者用户可以声明绝对路径)。
SSL
可选。指定SSL加密的使用。 如果SSL被设置为true,gpload 用--ssl启动gpfdist 服务器并且使用gpfdists://协议。
CERTIFICATES_PATH
当SSL为true时必需; 当SSL为false或者没有指定时 不能指定这个参数。CERTIFICATES_PATH 中指定的位置必须包含下列文件:
- 服务器证书文件 server.crt
- 服务器私钥文件 server.key
- 可信证书授权 root.crt
根目录(/) 不能被指定为 CERTIFICATES_PATH。
FULLY_QUALIFIED_DOMAIN_NAME
可选。指定gpload是否把主机名解析成完全限定的域名 (FQDN)或者本地主机名。如果值被设置为true, 名称会被解析到FQDN。如果该值被设置为false, 则解析到本地主机名。默认是false。
在某些情况下可能要求一个完全限定的域名。例如,如果Greenplum 数据库系统在与ETL应用不同的域且该域能够被gpload访问。
COLUMNS
可选。以field_name:data_type 这样的格式指定源数据文件的模式。源文件中的DELIMITER 字符是分隔两个数据值域(列)的东西。一行由一个换行字符(0x0a决定)。
如果输入COLUMNS没有指定,则使用输出TABLE的模式, 意味着源数据必须与目标表具有相同的列序、列数以及数据格式。
默认的source-to-target映射基于这一节定义的列名与目标TABLE 中列名之间的匹配。默认映射可以使用MAPPING小节覆盖。
TRANSFORM
可选。指定传递给gpload的输入转换的名字。 有关XML转换的信息,请见Greenplum数据库管理员指南 中的“装载和卸载数据”。
TRANSFORM_CONFIG
当TRANSFORM被指定时,这个元素是必需的。 指定在上面TRANSFORM参数中指定的转换的 配置文件位置。
MAX_LINE_LENGTH
可选。一个整数,指定传递给gpload 的XML转换数据中一行的最大长度。
FORMAT
可选。指定源数据文件的格式:纯文本(TEXT)格式, 逗号分隔值(CSV)格式。如果没有指定,这个默认为 TEXT。更多有关源数据格式的信息,请见 Greenplum数据库管理员指南中的“装载和卸载数据”。
DELIMITER
可选。指定在每行数据内分隔列的单个ASCII字符。在TEXT模式中默认是一个制表符, 在CSV模式中默认是一个逗号。用户还可以指定一个非可打印ASCII字符或者非可打印 Unicode字符,例如:"\x1B"或者 "\u001B"。 对于非可打印字符也支持转义字符串语法E'character-code'。 ASCII或Unicode字符必须被封闭在单引号中。例如:E'\x1B'或者 E'\u001B'。
ESCAPE
指定用于C转义序列(例如\n、\t、 \100等等)以及转义可能被当作行列定界符的数据字符的 单个字符。确保选择一个在实际列数据中任何地方都没有使用的转义字符。文本 格式文件的默认转义字符是一个\(反斜线),csv格式文件的默认转义字符是 一个"(双引号)。不过可以指定另一个字符来表示转义。 还可以在文本格式文件中通过指定'OFF'值作为转义值来 禁用转义。这对于其中嵌有很多不准备作为转义字符的反斜线的文本格式的Web 日志数据非常有用。
NULL_AS
可选。指定表示空值的字符串。TEXT模式中默认是\N (反斜线-N),CSV模式中默认是没有引用的空的值。 即便在TEXT模式中,对于想要把空值与空字符串区分 开来的情况,用户也可以使用空字符串。任何匹配这个字符串的源数据项将 被认为是一个空值。
FORCE_NOT_NULL
可选。在CSV模式中,处理每个被指定的列,仿佛它被引用并且因此 不是一个NULL值。对于CSV模式中的默认空值字符串(两个定界符之 间什么都没有),这导致缺失的值被计算为长度为零的字符串。
QUOTE
当FORMAT是CSV时, 这个元素是必需的。为CSV模式指定引用 字符。默认是双引号(")。
HEADER
可选。指定数据文件中的第一行是一个头部行(包含列名)并且不 应被包括在要被装载的数据中。如果使用多个数据源文件,所有的 文件必须有一个头部行。默认是假定输入文件没有头部行。
ENCODING
可选。源数据的字符集编码。可指定一个字符串常量(例如'SQL_ASCII')、 一个整数编码编号,或者指定'DEFAULT'以使用默认客户端编码。 如果没有指定,默认的客户端编码会被使用。有关支持的字符集的信息, 请见Greenplum数据库参考指南。
ERROR_LIMIT
可选。为这个装载操作启用单行错误隔离模式。当被启用时, 在输入被处理期间只要没有达到错误限制计数,任何Greenplum数据库 Segment会抛弃有格式错误的输入行。如果错误限制没有达到,所有 好的行将会被装载并且任何错误行都将被抛弃或者被捕捉在错误日志 信息中。默认是在遇到第一个错误时中止装载操作。注意单行错误隔离 只适用于有格式错误的数据行,例如有额外或者缺失的属性、有错误 数据类型的属性或者有无效的客户端编码序列。如果遇到约束错误 (例如主键约束)仍将导致装载操作中止。有关处理装载错误的信息, 请见Greenplum数据库管理员指南中的“装载和卸载数据”。
LOG_ERRORS
当ERROR_LIMIT被声明时,这个元素是可选的。 值可以是true或者false。 默认值是false。如果值是true, 当运行在单行错误隔离模式中时,格式错误的行会被内部记录下来。 用户可以用Greenplum数据库的内建SQL函数gp_read_error_log('table_name') 检查格式错误。如果在装载数据时检测到格式错误,gpload 会用包含错误信息的表的名字生成一个警告消息,看起来类似于这个消息。
timestamp|WARN|1 bad row, please use GPDB built-in function gp_read_error_log('table-name')
to access the detailed error row
- 可信证书授权 root.crt
- 服务器私钥文件 server.key
如果LOG_ERRORS: true被指定,必须指定REUSE_TABLES: true 以便在Greenplum数据库的错误日志中保留格式错误。如果没有指定REUSE_TABLES: true, 错误信息会在gpload操作后被删除。只有关于格式错误的总结信息会被返回。 用户可以用Greenplum数据库的函数gp_truncate_error_log()从错误日志 中删除格式错误。
更多有关处理装载错误的信息,请见Greenplum数据库管理员指南中的“装载和卸载数据”。 有关gp_read_error_log()函数的信息,请见Greenplum数据库参考指南 中的CREATE EXTERNAL TABLE命令。

