
合 数据迁移工具kettle使用详解
使用kettle实现Oracle到Oracle的数据同步
ETL技术是我们经常使用的数据库技术,大家可以通过很多种方式来实现。在大中型系统中,我们常用Oracle Data Integrator和Oracle GoldenGate来实现。但对于小型系统,大家认为简单易用的就是使用开源的Kettle,通过可视化的界面进行拖拽,轻松便捷地实现ETL。今天我们就和大家一起从安装开始,使用Kettle进行数据同步。
在今天的实验中,我们有3台独立的服务器,用途和分工如下:
- 主机1:源数据库:Oracle Database 19.5,数据库名称,orclpdb1
- 主机2:目标数据库:Oracle Database 19.5,数据库名称,orclpdb1
- 主机3:运行Kettle的Windows环境
Kettle可以运行在Windows、Linux以及Mac上。
第一步:安装JDK
今天我们以Windows作为Kettle运行的环境,在安装Kettle之前,需要安装JDK和JRE。您可以来到https://www.oracle.com/technetwork/java/javase/downloads/index.html下载适合您操作系统的JDK。在本实验中,我们将JDK安装在C盘下,路径如下:
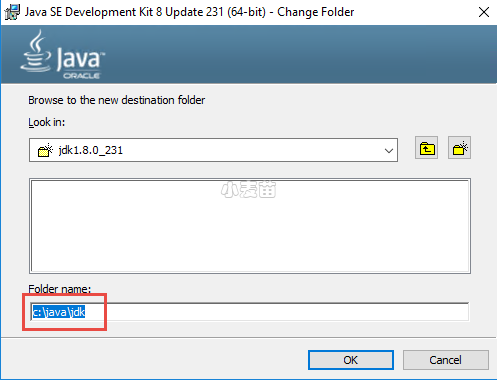
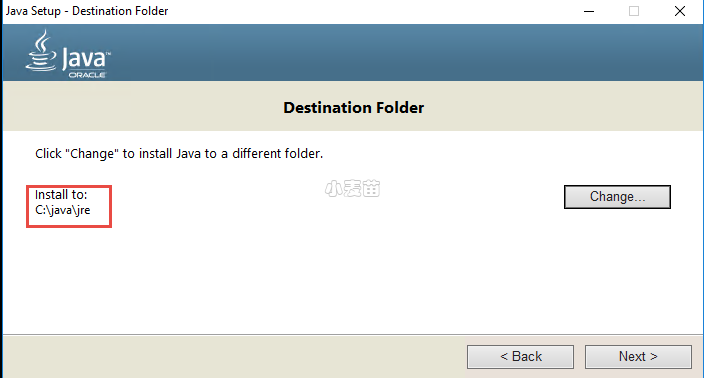
在安装的过程中会提示我们安装JRE,我们也选择在C盘安装。
第二步:设定环境变量
首先设定用户环境变量,将JDK下面的bin加入到Path当中。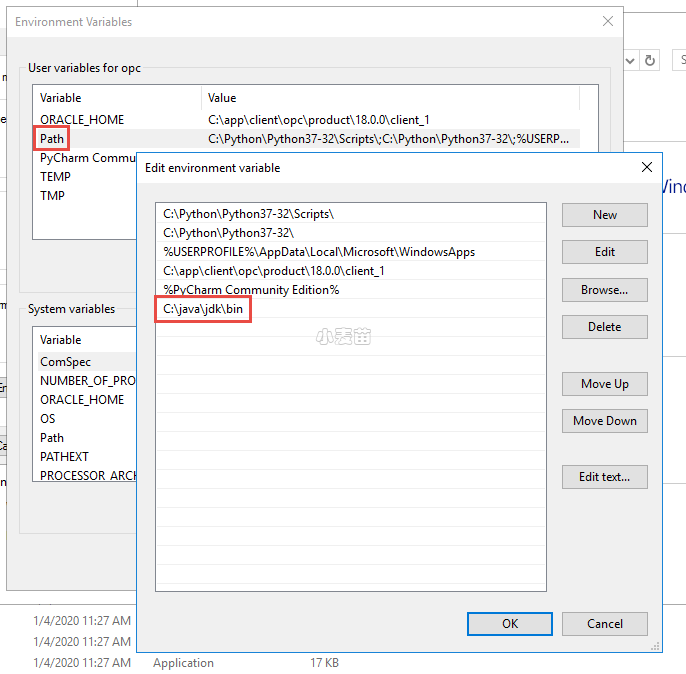
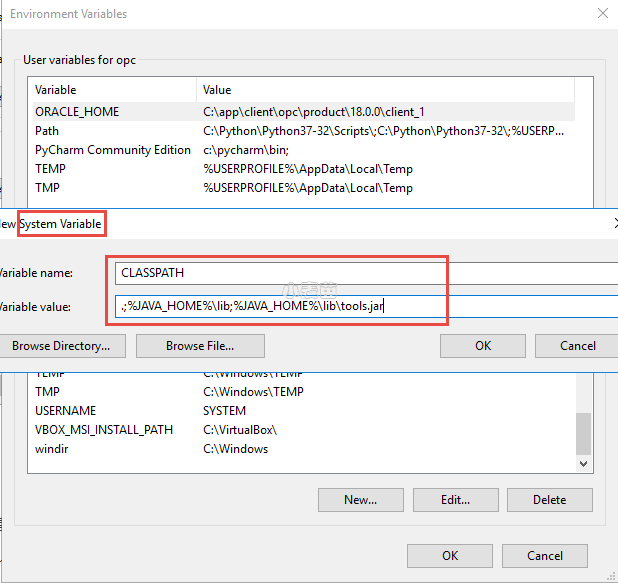
然后设定系统环境变量,加入JAVA_HOME,将JDK的路径加入其中。
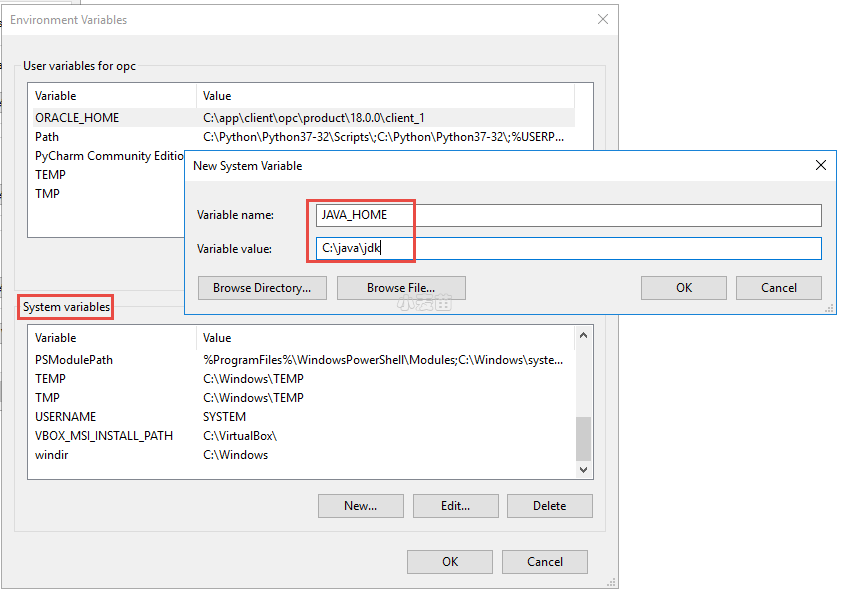
设定系统环境变量CLASSPATH,将
.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar加入其中。
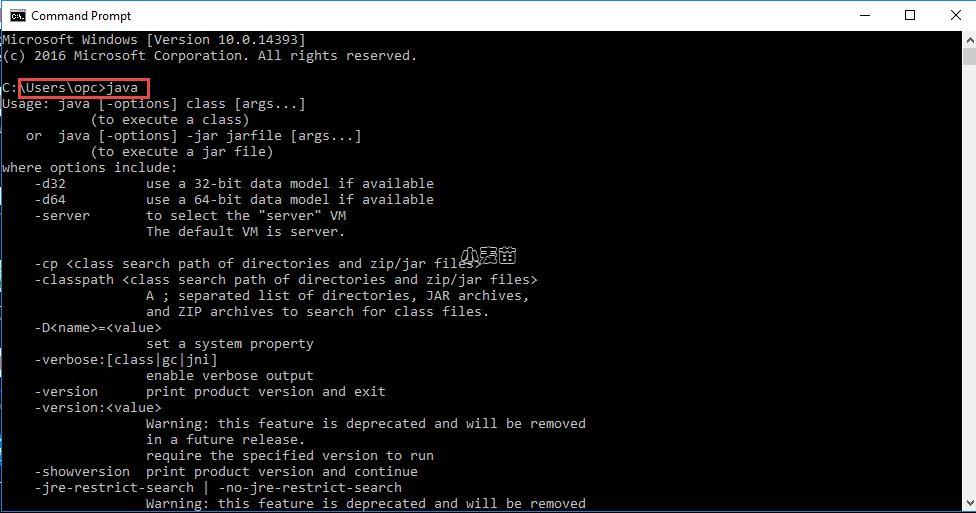
在命令行当中测试一下,看看java是否好用。

第三步:下载并解压并启动Kettle
您可以在
https://community.hitachivantara.com/s/article/data-integration-kettle下载Kettle
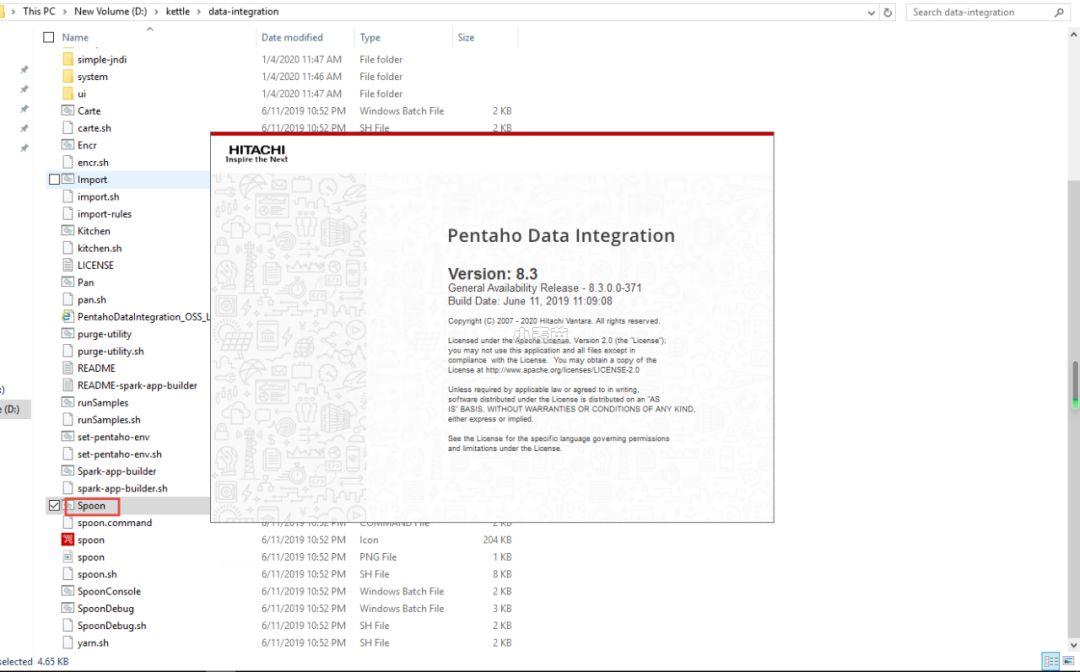
下载之后,执行解压文件夹下的Spoon.bat文件即可启动Kettle。Kettle的启动时间可能会稍微长一些,一般是因为JAVA的虚拟机配置的问题,您可以通过修改Spoon.bat这个文件中关于JAVA虚拟机的配置来调整Kettle的性能。比如修改这个文件中的如下代码:
if "%PENTAHO_DI_JAVA_OPTIONS%"=="" set PENTAHO_DI_JAVA_OPTIONS="-Xms512m" "-Xmx512m" "-XX:MaxPermSize=256m"
第四步:安装Oracle数据库驱动
Kettle自带了很多数据库的驱动,但是Oracle的数据库驱动没有在其中,我们需要下载与Kettle相匹配的数据库驱动,我们今天使用的数据库是Oracle Database19.5,但是通过测试发现,8.3的Kettle并不支持最新版的数据库驱动,所以我们下载Oracle Database 12c(
https://www.oracle.com/database/technologies/jdbc-drivers-12c-downloads.html
)的Java数据库驱动,并将它放在Kettle安装路径下的lib路径下。按照下图提示,将压缩文件下载之后,将里面的jar文件,放入Kettle安装路径下的lib当中。

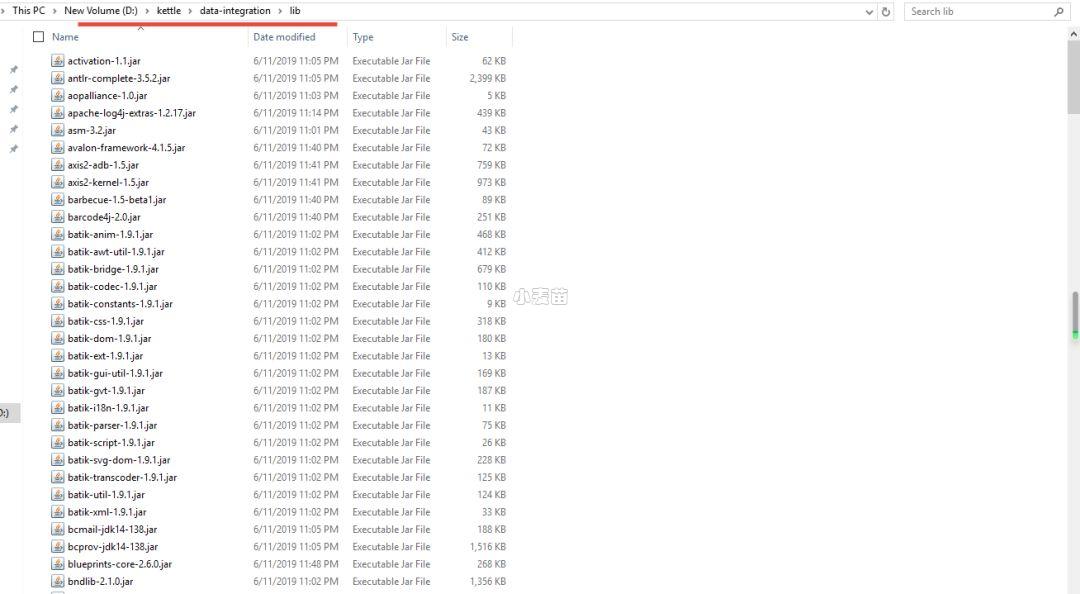

第五步:创建JNDI
连接数据库的方式有很多,在连接PDB的时候,我个人比较喜欢使用JNDI的方式进行连接,这种连接方式,简单明了。在Kettle的安装路径下,会找到simple-jndi路径,里面有一个jdbc.properties文件,编辑这个文件即可。
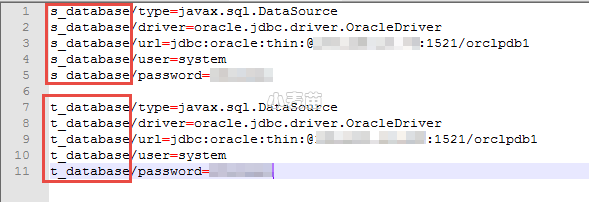
在今天的操作中,我们有两个数据库,我们给他们起名字为s_database和t_database,分别代表源数据库和目标数据库,请大家注意观察jdbc.properties文件中的写法。
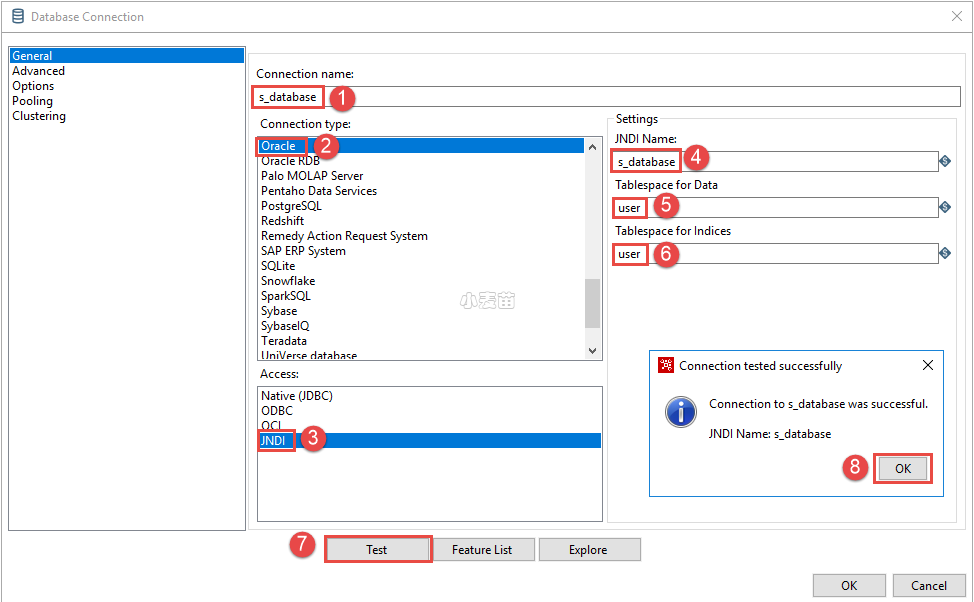
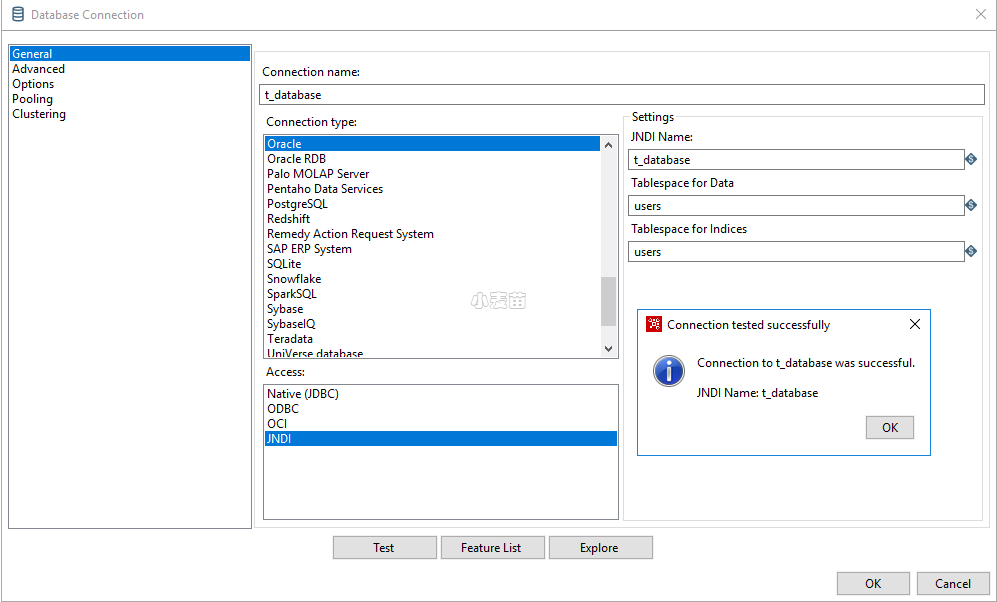
第六步:创建数据库连接
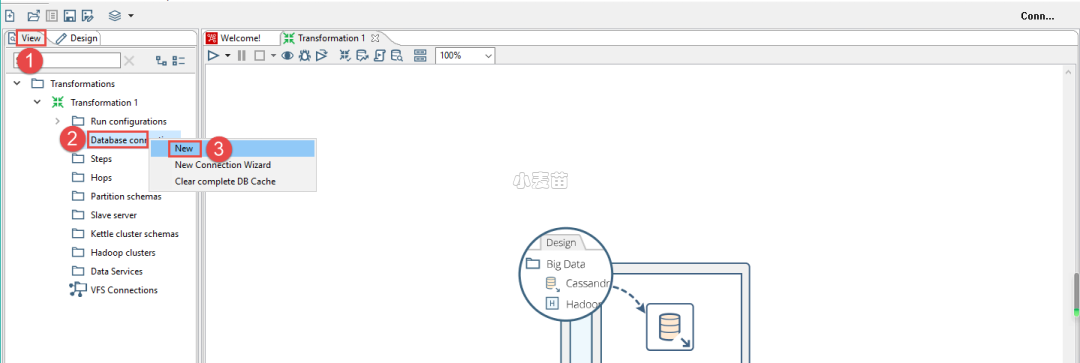
来到Kettle双击下图中的(2)所示的Transformations,Kettle会自动创建一个Transformation,但是页面会直接切换到Design,我们要手动按照下图的操作,切换回VIEW,并创建数据库连接。
按照下面的图中的顺序创建s_database和t_database两个数据库连接。如果没有问题,将看到下图中(8)所示的连接成功提示。

第七步:设定源数据表
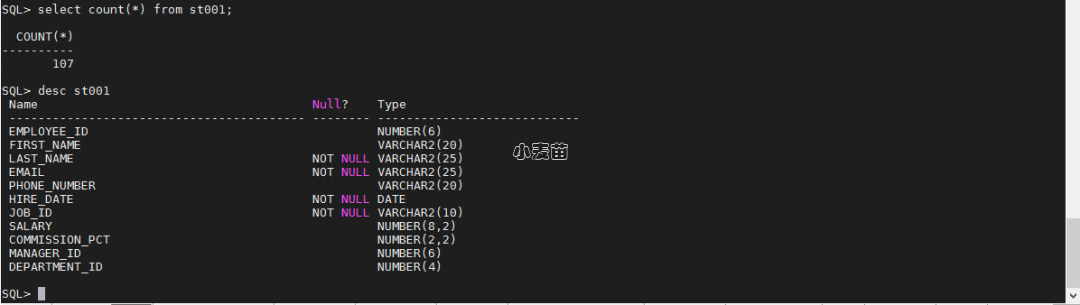
我们在s_database数据库中的chatbot这个schema当中,有个表叫做st001,数据有107条,有11个字段。
我们来到Kettle当中,按照下图所示,在input当中找到table input,将它拖拽到右侧空白处。


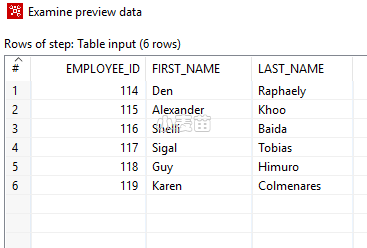
接下来,配置这个table input,双击它即可。我们只想同步employee_id,first_name和last_name这三个字段并且department_id为30的数据。
通过按Preview按钮,可以看到具体的查询结果。
第八步:设定目标数据表
我们在t_database数据库的HR schema下面有一张表,叫做tt001,结构和数据如下。

在Kettle当中将output当中的Table output拖入右侧空白处。
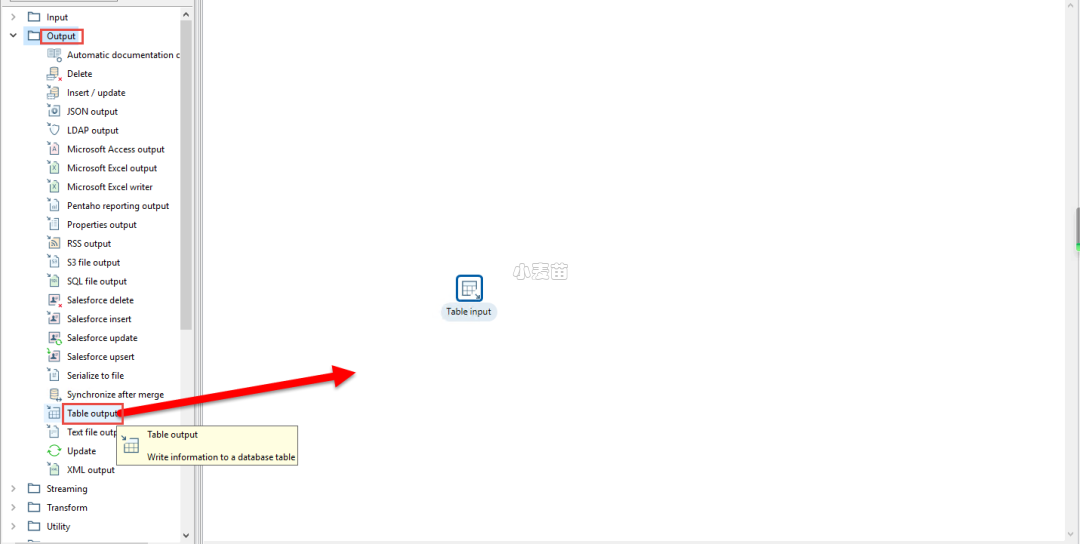
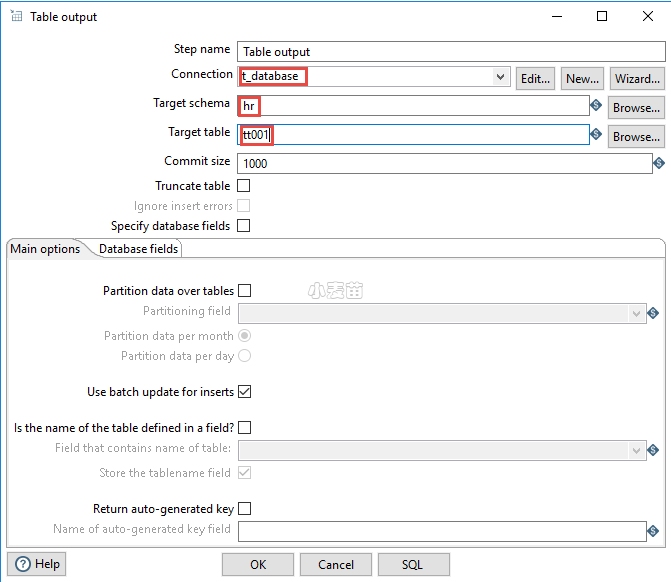
双击刚拖入的Table output图标,对它进行配置。
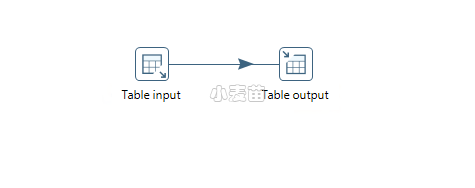
按住shift键,然后点击Table input,屏幕上会出现一个箭头,将箭头指向table output。
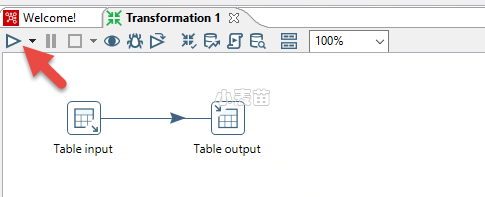
第九步:启动同步
按下图中红色箭头所指的图标,启动数据同步。
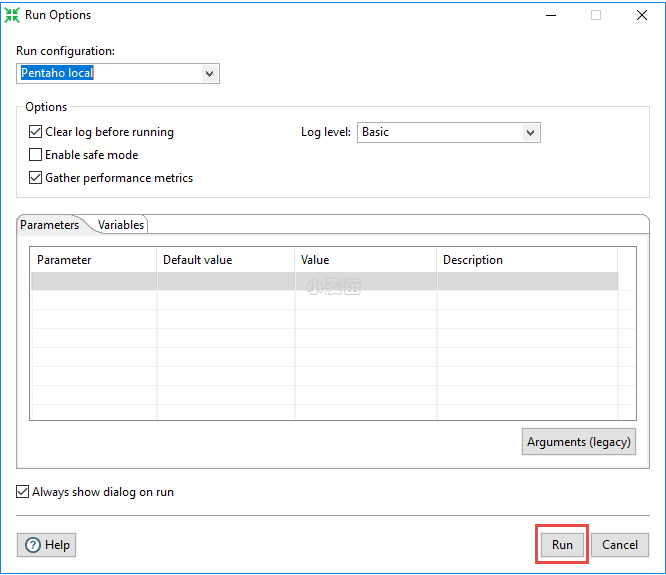
点击上面的图标之后,会出现下方的对话框,我们点击run即可。
按照要求,我们要将这个项目先保存,然后才可以执行。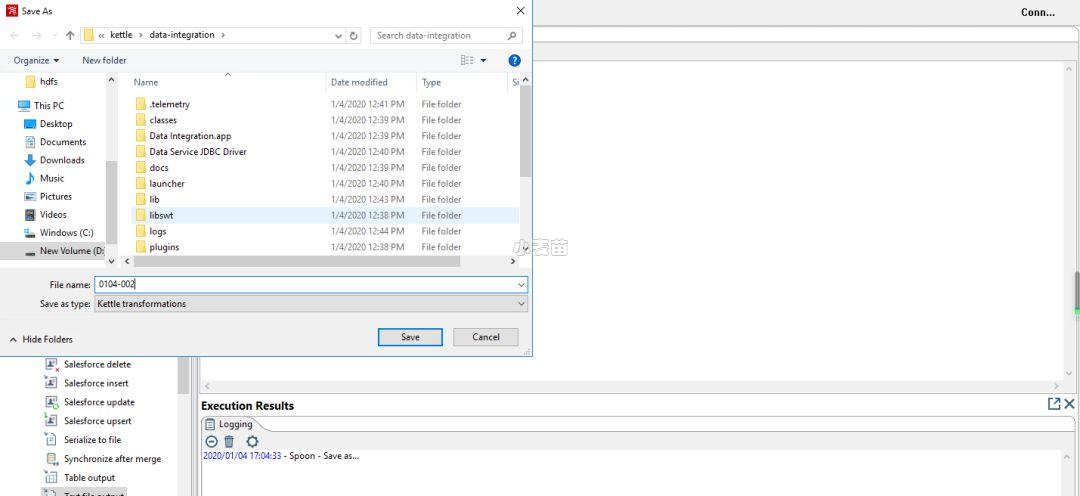
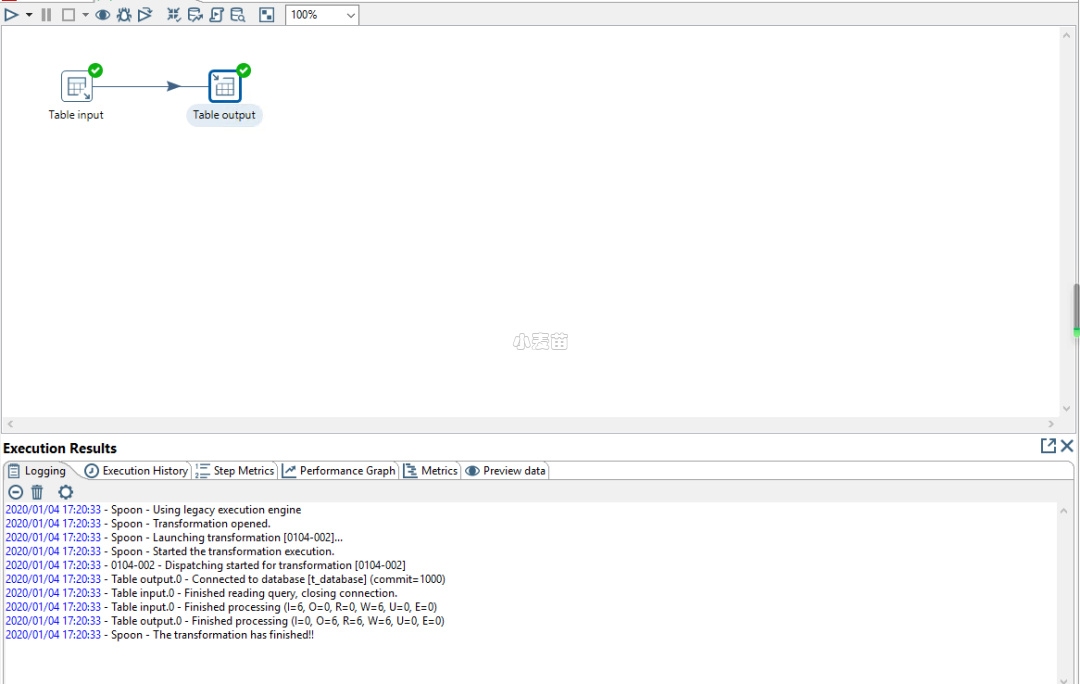
执行之后的结果如下,在下方可以看到日志,如果有错误,会提示错误原因。
第十步:验证同步结果

申请看kettel
公众号回复关键字“小麦苗博客”即可