合 数据迁移工具kettle安装和优化
kettle简介
Kettle最早是一个开源的ETL工具,全称为KDE Extraction, Transportation, Transformation and Loading Environment。
在2006年,Pentaho公司收购了Kettle项目,原Kettle项目发起人Matt Casters加入了Pentaho团队,成为Pentaho套件数据集成架构师 ;从此,Kettle成为企业级数据集成及商业智能套件Pentaho的主要组成部分,Kettle亦重命名为Pentaho Data Integration ,简称“PDI”。Pentaho公司于2015年被Hitachi Data Systems收购。 自2017年9月20日起,Pentaho已经被合并于日立集团下的新公司: Hitachi Vantara。
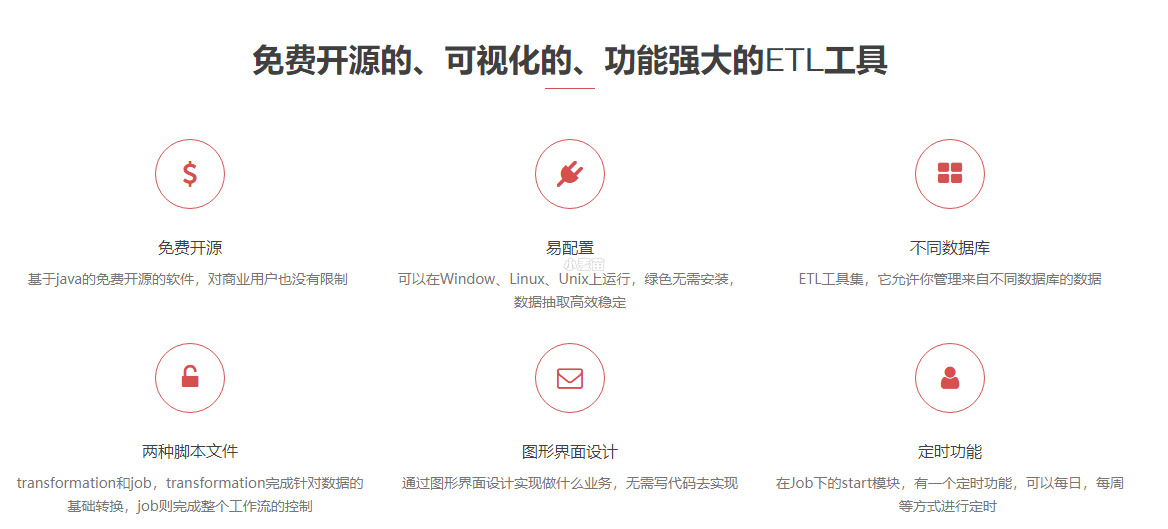
Pentaho Data Integration以Java开发,支持跨平台运行,其特性包括:支持100%无编码、拖拽方式开发ETL数据管道;可对接包括传统数据库、文件、大数据平台、接口、流数据等数据源;支持ETL数据管道加入机器学习算法。
Pentaho Data Integration分为商业版与开源版,开源版的截止2021年1月的累计下载量达836万,其中19%来自中国 。在中国,一般人仍习惯把Pentaho Data Integration的开源版称为Kettle。
Kettle是一款国外开源的ETL工具,纯java编写,可以在Windows、Linux、Unix上运行,数据抽取高效稳定。Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
kettle 的官网是 https://community.hitachivantara.com/docs/DOC-1009855
https://community.hitachivantara.com/home
github 地址是 https://github.com/pentaho/pentaho-kettle
下载地址:https://sourceforge.net/projects/pentaho/files/Data%20Integration/
参考:https://blog.51cto.com/51power/5216715
KETTLE常用功能
KETTLE常用在处理关系型数据库(RDBMS):mysql、oracle、gbase、国产达梦等各种数据库,也可以处理非关系型数据库:elasticsearch、hdfs等数据存储。主要是对数据进行处理操作,个人常用的功能如下:
(1)全量数据迁移:
就是将某个或多个表或库中的数据进行迁移,可以跨库,也可以同库迁移。速度比较快,性能稳定。
(2)增量数据迁移:
就是对某个表中的数据按照一定的设计思路,根据int的自增主键或datetime的时间戳实现增量数据迁移,并且可以统计增量数据量。速度比较快,性能稳定。
(3)解析xml文件(单个、批量):
可以通过读取本地或远程服务器中的单个、批量xml文件进行解析,高效率的实现xml数据解析入库。
(4)解析JSON数据:
可以零代码通过jsonPath快速完成JSON数据解析,高效率实现JSON解析数据入库。
(5)数据关联比对:
可以将多个数据库根据一定的业务字段进行关联,尤其是针对单表百万、千万级别上的数据比对,普通sql实现困难,可以通过KETTLE方便高效的完成数据关联比对功能。
(6)数据清洗转换:
可以通过KETTLE中设计一定的判断流程,在数据流中逐条对数据进行业务判断和过滤,实现数据清洗转换的功能。
架构
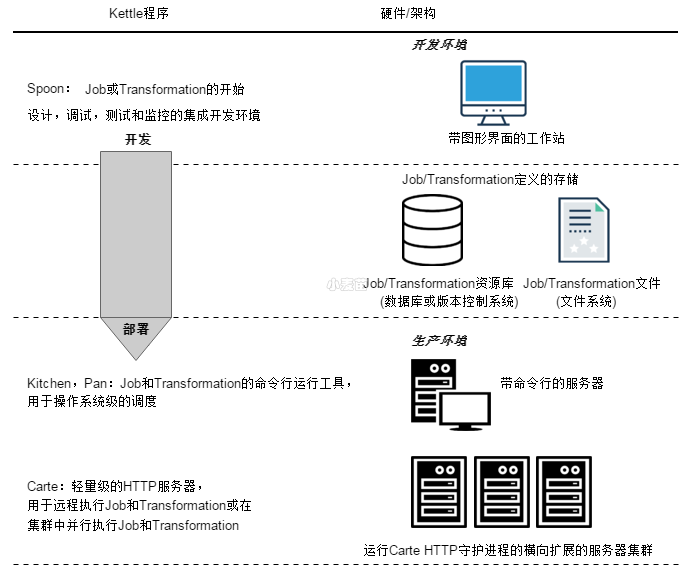
Kettle是一个组件化的集成系统,包括如下几个主要部分:
1.Spoon:图形化界面工具(GUI方式),Spoon允许你通过图形界面来设计Job和Transformation,可以保存为文件或者保存在数据库中。
也可以直接在Spoon图形化界面中运行Job和Transformation,
2.Pan:Transformation执行器(命令行方式),Pan用于在终端执行Transformation,没有图形界面。
3.Kitchen:Job执行器(命令行方式),Kitchen用于在终端执行Job,没有图形界面。
4.Carte:嵌入式Web服务,用于远程执行Job或Transformation,Kettle通过Carte建立集群。
5.Encr:Kettle用于字符串加密的命令行工具,如:对在Job或Transformation中定义的数据库连接参数进行加密。
基本概念
1.Transformation:定义对数据操作的容器,数据操作就是数据从输入到输出的一个过程,可以理解为比Job粒度更小一级的容器,我们将任务分解成Job,然后需要将Job分解成一个或多个Transformation,每个Transformation只完成一部分工作。
2.Step:是Transformation内部的最小单元,每一个Step完成一个特定的功能。
3.Job:负责将Transformation组织在一起进而完成某一工作,通常我们需要把一个大的任务分解成几个逻辑上隔离的Job,当这几个Job都完成了,也就说明这项任务完成了。
4.Job Entry:Job Entry是Job内部的执行单元,每一个Job Entry用于实现特定的功能,如:验证表是否存在,发送邮件等。可以通过Job来执行另一个Job或者Transformation,也就是说Transformation和Job都可以作为Job Entry。
5.Hop:用于在Transformation中连接Step,或者在Job中连接Job Entry,是一个数据流的图形化表示。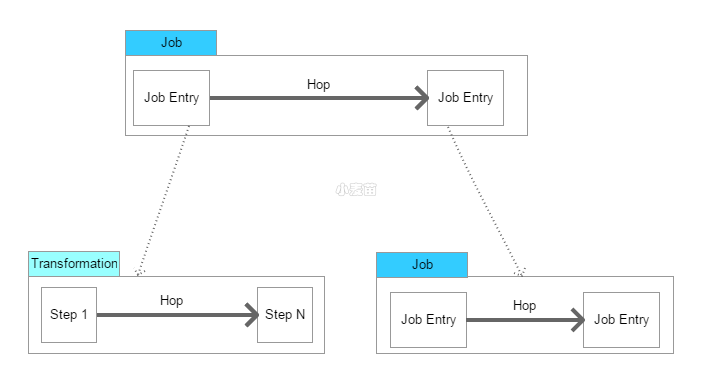
在Kettle中Job中的JobEntry是串行执行的,故Job中必须有一个Start的JobEntry;Transformation中的Step是并行执行的。
1、repository资源库
用来保存转换任务的,用户通过图形界面创建的的转换任务可以保存在资源库中。资源库可以使多用户共享转换任务,转换任务在资源库中是以文件夹形式分组管理的,用户可以自定义文件夹名称。
2、ktr转换
将一个或多个数据源组装成一条数据流水线,根据业务要求,利用Kettle内部的组件,进行数据处理,最后输出到某一个地方(文件或数据库)。
3、kjb作业
可以调度设计好的一个或多个转换,也可以执行一些文件处理(比较\删除等),还可以往ftp上传和下载文件,发送邮箱,执行shell命令等等。
4、连接线
连接转换步骤或者连接Job(实际上就是执行顺序)的连线。
5、转换连接
表示数据的流向。从输入开始,中间包括了:过滤等转换操作,最后到输出。
6、作业连接
表示作业的执行流程。作业连接时,可设置执行条件有3种:
a、无条件执行
b、当上一个Job执行结果为true时执行
c、当上一个Job执行结果为false时执行
组件对比
目前,ETL工具的典型代表有:
- 商业软件:Informatica PowerCenter,IBM InfoSphere DataStage,Oracle Data Integrator,Microsoft SQL Server Integration Services等
- 开源软件:Kettle,Talend,Apatar,Scriptella等
纯java编写,可以跨平台运行,绿色无需安装,数据抽取高效稳定。
相对于传统的商业软件,Kettle是一个易于使用的,低成本的解决方案。
Spoon是基于SWT(SWT使用了本地操作系统的组件库,性能更好,界面更符合本地操作系统的风格)开发的,支持多平台:
- Microsoft Windows: all platforms since Windows 95, including Vista
- Linux GTK: on i386 and x86_64 processors, works best on Gnome
- Apple's OSX: works both on PowerPC and Intel machines
- Solaris: using a Motif interface (GTK optional)
- AIX: using a Motif interface
- HP-UX: using a Motif interface (GTK optional)
- FreeBSD: preliminary support on i386, not yet on x86_64
Kettle使用场景
- Migrating data between applications or databases 在应用程序或数据库之间进行数据迁移
- Exporting data from databases to flat files 从数据库导出数据到文件
- Loading data massively into databases 导入大规模数据到数据库
- Data cleansing 数据清洗
- Integrating applications 集成应用程序
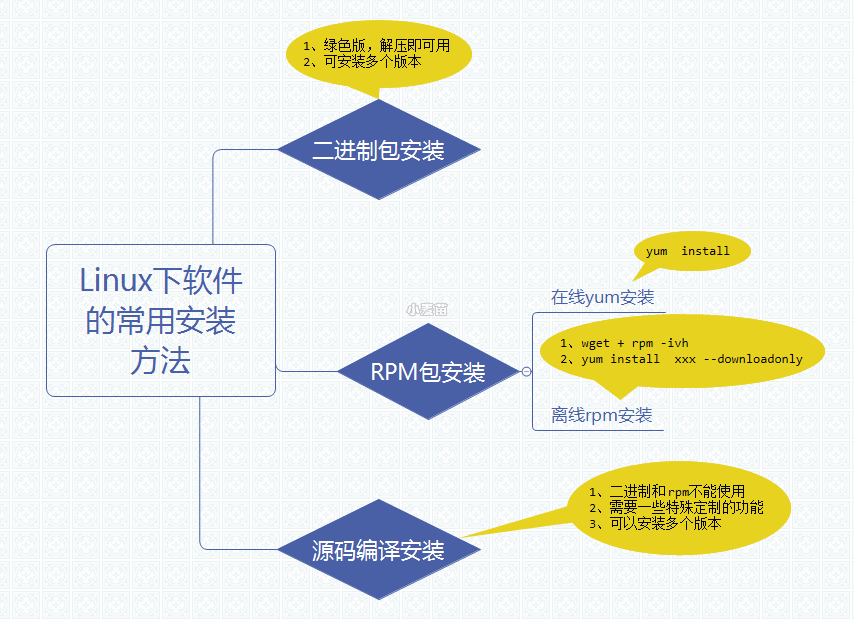
kettle安装
下载:https://sourceforge.net/projects/pentaho/files/Data%20Integration/
https://sourceforge.net/projects/pentaho/files/
Kettle免安装,在windows或linux环境下,直接解压到指定目录即可。
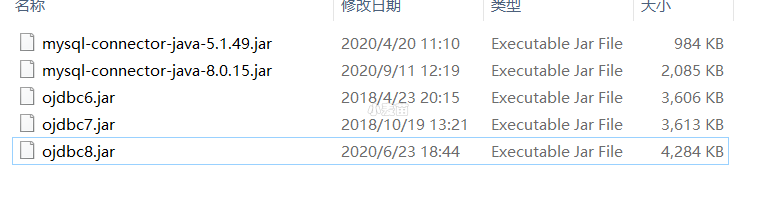
需要有java环境和下载相应的数据库驱动。由于 kettle 需要连接数据库,因此需要下载对应的数据库驱动。例如 MySQL 数据库需要下载 mysql-connector-java.jar,oracle 数据库需要下载 ojdbc.jar。下载完成后,将 jar 放入 kettle 解压后路径的 lib 文件夹中即可。
双击 Spoon.bat 就能启动 kettle 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | wget https://udomain.dl.sourceforge.net/project/pentaho/Pentaho-9.3/client-tools/pdi-ce-9.3.0.0-428.zip docker rm -f lhrkettle docker run -itd --name lhrkettle -h lhrkettle \ -p 9390:3389 \ -v /sys/fs/cgroup:/sys/fs/cgroup \ --privileged=true lhrbest/lhrcentos76:9.0 \ /usr/sbin/init docker cp pdi-ce-9.3.0.0-428.zip lhrkettle:/soft/ yum install -y webkitgtk* wget http://ftp.pbone.net/mirror/ftp5.gwdg.de/pub/opensuse/repositories/home:/matthewdva:/build:/EPEL:/el7/RHEL_7/x86_64/webkitgtk-2.4.9-1.el7.x86_64.rpm yum install -y webkitgtk-2.4.9-1.el7.x86_64.rpm unzip pdi-ce-9.3.0.0-428.zip -d /usr/local/ cd /usr/local/data-integration/lib 上传jar包: -- 修改如下参数,否则界面不能点击,会卡住,点不动 vi /usr/local/data-integration/spoon.sh export LANG=zh_CN.UTF-8 #export GDK_NATIVE_WINDOWS=0 export SWT_GTK3=1 cd /usr/local/data-integration [root@lhrkettle data-integration]# ./kitchen.sh Options: -rep = Repository name -user = Repository username -trustuser = !Kitchen.ComdLine.RepUsername! -pass = Repository password -job = The name of the job to launch -dir = The directory (dont forget the leading /) -file = The filename (Job XML) to launch -level = The logging level (Basic, Detailed, Debug, Rowlevel, Error, Minimal, Nothing) -logfile = The logging file to write to -listdir = List the directories in the repository -listjobs = List the jobs in the specified directory -listrep = List the available repositories -norep = Do not log into the repository -version = show the version, revision and build date -param = Set a named parameter <NAME>=<VALUE>. For example -param:FILE=customers.csv -listparam = List information concerning the defined parameters in the specified job. -export = Exports all linked resources of the specified job. The argument is the name of a ZIP file. -custom = Set a custom plugin specific option as a String value in the job using <NAME>=<Value>, for example: -custom:COLOR=Red -maxloglines = The maximum number of log lines that are kept internally by Kettle. Set to 0 to keep all rows (default) -maxlogtimeout = The maximum age (in minutes) of a log line while being kept internally by Kettle. Set to 0 to keep all rows indefinitely (default) [root@lhrkettle data-integration]# -- 启动图形界面 sh /usr/local/data-integration/spoon.sh & |
备注:
kitchen.sh:用来执行job作业
pan.sh:用来执行ktr转换
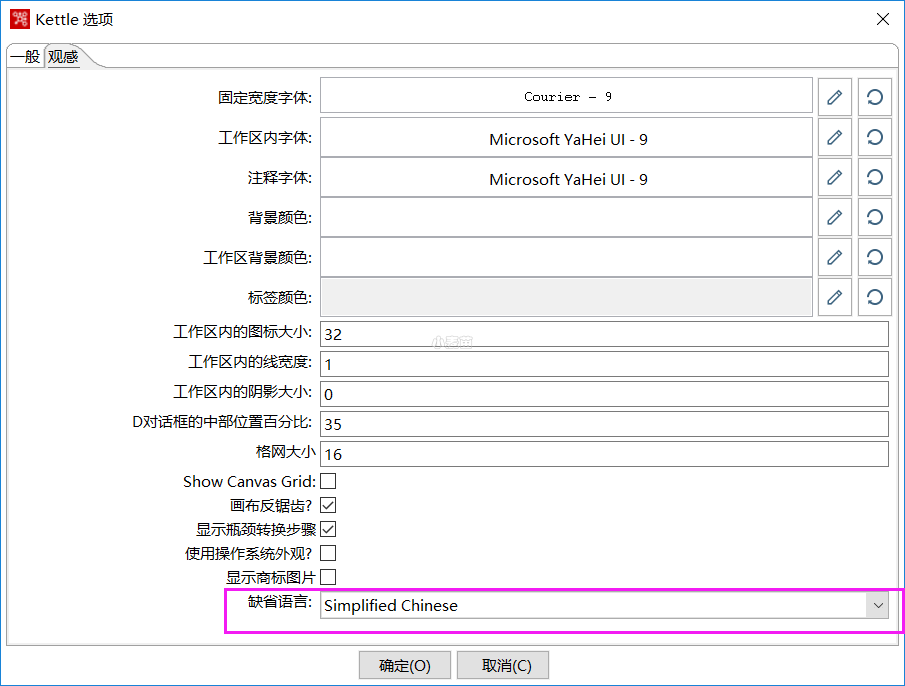
配置界面语言:
1 2 | vi /usr/local/data-integration/spoon.sh export LANG=zh_CN.UTF-8 |
或: