原 SQL Server代理作业的巨大性能飞跃:从2天到2小时的调优
前言
在本文中,麦老师将给大家介绍如何调优SQL Server的代理作业JOB,并结合实际生产案例将一个运行时间从长达2天的作业调优缩短至令人欣喜的2小时。
本文所使用的调优方法论基本可以通用于其它SQL Server的数据库系统,该套方法论是麦老师经过好几个项目的实战案例总结所得。
闻道有先后,术业有专攻。善语结善缘,恶语伤人心。本文可能有不对之处,欢迎批评指正,欢迎转发评论。
调优前的作业情况及基本信息获取
SQL Server版本: 2012
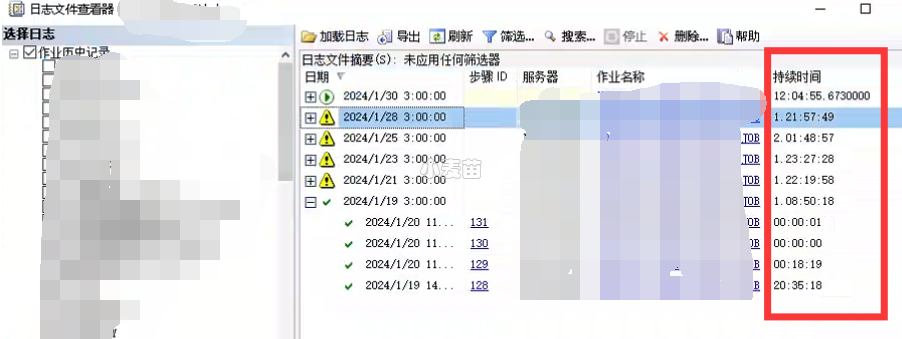
首先通过日志文件查看器,简单获取JOB的运行情况,可以发现如下几个问题:
1、该JOB共131个step,其实就是131个存储过程
2、历史日志中,总运行时间从1天到2天不等
3、1月30日运行了12个小时还未跑完,我开始介入进行调优
可以通过如下的SQL语句,查询出JOB中哪个步骤最耗费时间:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | SELECT sj.name AS [Name], sh.step_id, sh.step_name AS [StepName], DATETIMEFROMPARTS( LEFT(padded_run_date, 4), -- year SUBSTRING(padded_run_date, 5, 2), -- month RIGHT(padded_run_date, 2), -- day LEFT(padded_run_time, 2), -- hour SUBSTRING(padded_run_time, 3, 2), -- minute RIGHT(padded_run_time, 2), -- second 0) AS [LastRunDateTime], -- millisecond CASE WHEN sh.run_duration > 235959 THEN CAST((CAST(LEFT(CAST(sh.run_duration AS VARCHAR), LEN(CAST(sh.run_duration AS VARCHAR)) - 4) AS INT) / 24) AS VARCHAR) + '.' + RIGHT('00' + CAST(CAST(LEFT(CAST(sh.run_duration AS VARCHAR), LEN(CAST(sh.run_duration AS VARCHAR)) - 4) AS INT) % 24 AS VARCHAR), 2) + ':' + STUFF(CAST(RIGHT(CAST(sh.run_duration AS VARCHAR), 4) AS VARCHAR(6)), 3, 0, ':') ELSE STUFF(STUFF(RIGHT(REPLICATE('0', 6) + CAST(sh.run_duration AS VARCHAR(6)), 6), 3, 0, ':'), 6, 0, ':') END AS [LastRunDuration (d.HH:MM:SS)], sh.run_status, sh.message, sh.server, jstep.command FROM msdb.dbo.sysjobs sj INNER JOIN msdb.dbo.sysjobhistory sh ON sj.job_id = sh.job_id left JOIN [msdb].[dbo].[sysjobsteps] AS [jstep] ON sj.job_id = jstep.job_id and sh.step_id=jstep.step_id CROSS APPLY ( SELECT RIGHT('000000' + CAST(sh.run_time AS VARCHAR(6)), 6), RIGHT('00000000' + CAST(sh.run_date AS VARCHAR(8)), 8) ) AS shp(padded_run_time, padded_run_date) where name='ACT_JOB' and sh.run_duration>='6000' -- 执行时长大于60分钟 -- and instance_id>=557203 order by instance_id desc GO |
结果:
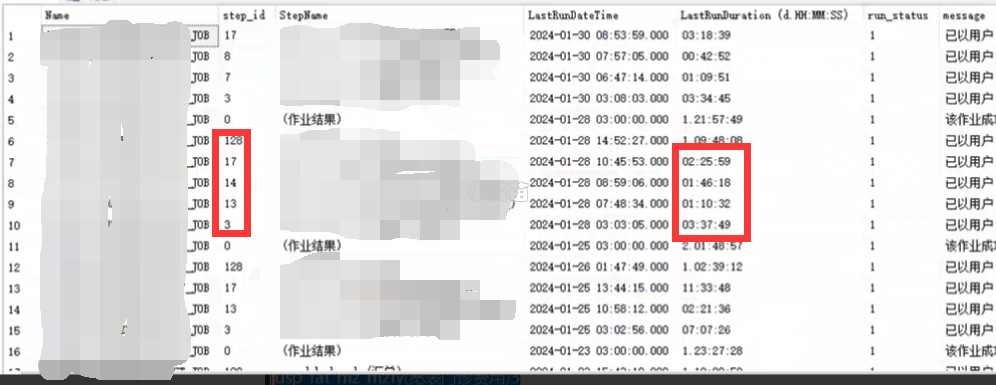
从结果可以看出,第3、7、8、13、14、14、17、128这几个存储过程最耗费时间,其中以3和128最耗费时间,尤其是128存储过程需要1天9小时。后边重点只跟踪调优这2个存储过程即可。
在这里,存储过程名称如何获取呢???就是麦老师给的SQL语句中的 jstep.command列或StepName列就可以获取到。
调优过程
整个调优过程,可能涉及3个大的环节:
A、数据库层面整体调优,包括内存、CPU调整;索引碎片重建;创建missing的索引
B、具体的存储过程的SQL级别的跟踪和调优
C、继续创建missing的索引
D、观察性能是否稳定
步骤A、整体调优
这个步骤先不分析具体的SQL语句,因为SQL实在太多,我们先做数据库整体的调优。
1、内存和CPU调优
先进行数据库配置方面的调优,尤其是内存和并发,可以根据实际情况进行调整,如下:
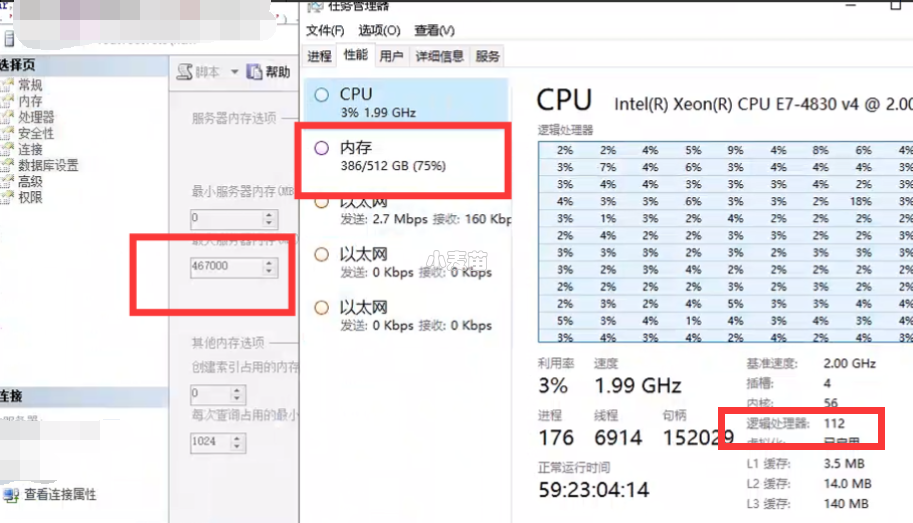
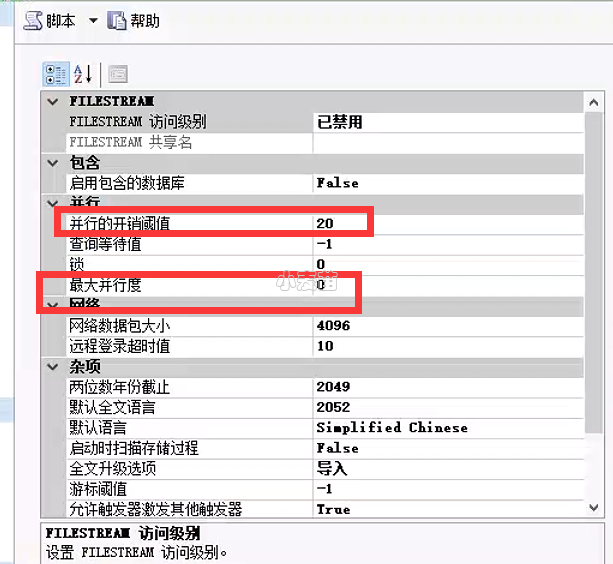
可以看出,内存和CPU都不是瓶颈。
2、数据库总体层面的索引碎片重建
根据麦老师的经验,若SQL Server的SQL性能渐渐慢下来的话,很大程度上跟大表的索引碎片严重有关系,很多大表的索引碎片会达到90%以上,所以,必须重建。
但是,这类JOB慢,涉及的表很多,作为DBA只能从数据库整体层面来进行索引的重建,我们可以使用如下脚本查询当前数据库中碎片率大于30%的所有索引,若有多个数据库,则需要分别对每个库进行查询,这个脚本执行很慢,可能需要七八个小时甚至十几个小时,不用着急,慢慢跑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | -- 数据库中碎片率大于30%的所有索引 SELECT db_name() dbname, OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name, OBJECT_NAME(ips.object_id) AS tb_name, i.name AS index_name, i.type_desc AS index_type, CAST(ips.avg_fragmentation_in_percent AS DECIMAL(5, 2)) avg_fragmentation_in_percent, -- 索引碎片总计百分比,大于30%就得重建 CAST(ips.avg_page_space_used_in_percent AS DECIMAL(5, 2)) avg_page_space_used_in_percent, -- 索引页填充度,小于70%就得重建 ips.index_depth, ips.page_count, ips.fragment_count, ips.alloc_unit_type_desc, 'ALTER INDEX '+ i.name +' ON '+ OBJECT_NAME(ips.object_id) +' REBUILD WITH (MAXDOP=16);' index_rebuild FROM ( select * from sys.dm_db_index_physical_stats(db_id(), null, NULL, NULL, NULL ) a where a.index_level=0 and alloc_unit_type_desc='IN_ROW_DATA' )AS ips LEFT JOIN sys.indexes AS i ON (ips.object_id = i.object_id AND ips.index_id = i.index_id and ips.index_level=0) where i.name is not null and ips.avg_fragmentation_in_percent > 30 ORDER BY page_count DESC; |
跑出结果后,拷贝index_rebuild列,然后执行SQL重建索引即可,可能又需要好几个小时甚至十几个小时。
3、创建missing的索引
相关理论可以参考:https://mp.weixin.qq.com/s/_0AqqTvsZXwPJ2tNrYH5Yw
缺失索引功能是一种轻量工具,用于查找可显著提高查询性能的缺失索引。
我们可以直接使用如下的SQL获取数据库运行过程中需要创建的索引:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | -- 缺失索引 select * from ( SELECT TOP 20 CONVERT (decimal (28, 1), migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) ) AS estimated_improvement, migs.unique_compiles, migs.user_seeks, migs.user_scans, migs.last_user_seek, migs.last_user_scan, migs.avg_user_impact, mid.database_id, mid.object_id, mid.equality_columns, mid.inequality_columns, mid.included_columns, mid.statement, 'CREATE INDEX idx_missing_index_' + CONVERT(varchar,mid.database_id) + '_' + CONVERT(varchar,mid.object_id) + '_' + CONVERT (varchar, mig.index_group_handle) + '_' + CONVERT (varchar, mid.index_handle) + ' ON ' + mid.statement + ' (' + ISNULL (mid.equality_columns, '') + CASE WHEN mid.equality_columns IS NOT NULL AND mid.inequality_columns IS NOT NULL THEN ',' ELSE '' END + ISNULL (mid.inequality_columns, '') + ')' + ISNULL (' INCLUDE (' + mid.included_columns + ')', '') +' with (maxdop=32);' AS create_index_statement FROM sys.dm_db_missing_index_groups mig WITH(NOLOCK) JOIN sys.dm_db_missing_index_group_stats migs WITH(NOLOCK) on migs.group_handle = mig.index_group_handle JOIN sys.dm_db_missing_index_details mid WITH(NOLOCK) on mig.index_handle = mid.index_handle where 1=1 and migs.last_user_seek >='2024-01-30 13:40' -- and migs.user_seeks>2 ORDER BY estimated_improvement DESC ) aa where estimated_improvement > 100 and avg_user_impact>30 order by database_id,object_id,equality_columns,included_columns GO |
我们可以直接复制create_index_statement列,拷贝到文本编辑器中,将查询出来的索引进行手工的合并,因为有的索引有重叠,该步骤可能需要业务人员进行介入讨论。另外,对于OLTP类型的重要业务库,一定要提交变更才能创建索引,否则最后背锅的都是自己。
修改或合并完成后,把这些缺失的索引都创建上,这个过程也需要很久。
调优结果1
其实,在经过以上1、2和3步骤后,数据库性能应该已经有了显著的提升了,例如,麦老师这个环境:
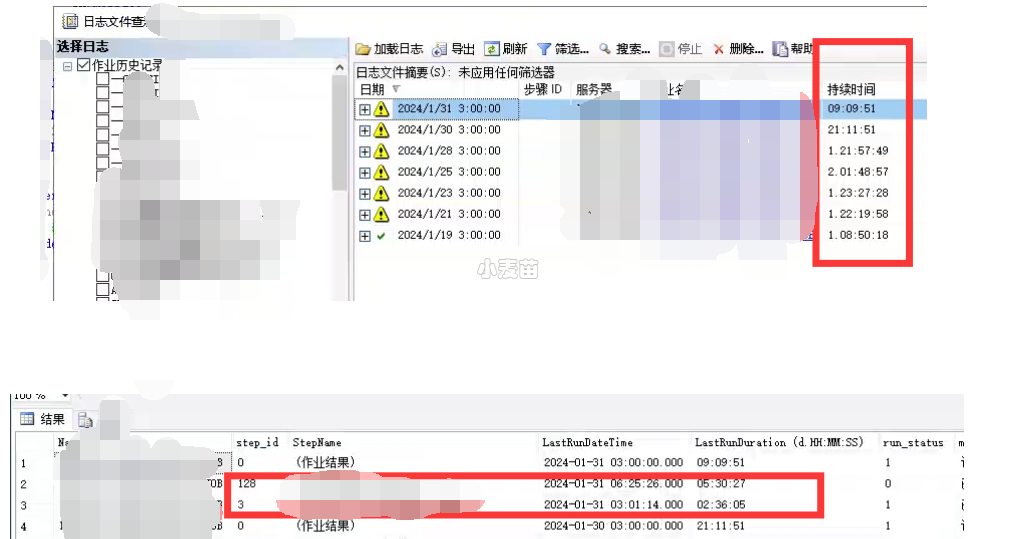
可以看到,整个job的运行时间先缩短到21小时(碎片重建),再缩短到9小时(创建missing索引)。
step 3从之前的7小时缩短到3小时,step 128从之前的1天9小时缩短到现在的6小时。
但,时间仍然有点长,需要继续进行深入调优。
步骤B、具体存储过程调优
接下来的调优,因为涉及具体的额存储过程,需要找到存储过程中到底是哪个SQL很慢导致的,所以,需要借助SQL Server Profiler功能进行跟踪,比较费时,使用方法具体可以参考:https://www.dbaup.com/mssqlruhehuoqucunchuguochengzhongzhengzaizhixingdezhenshisqlyuju.html,示例:
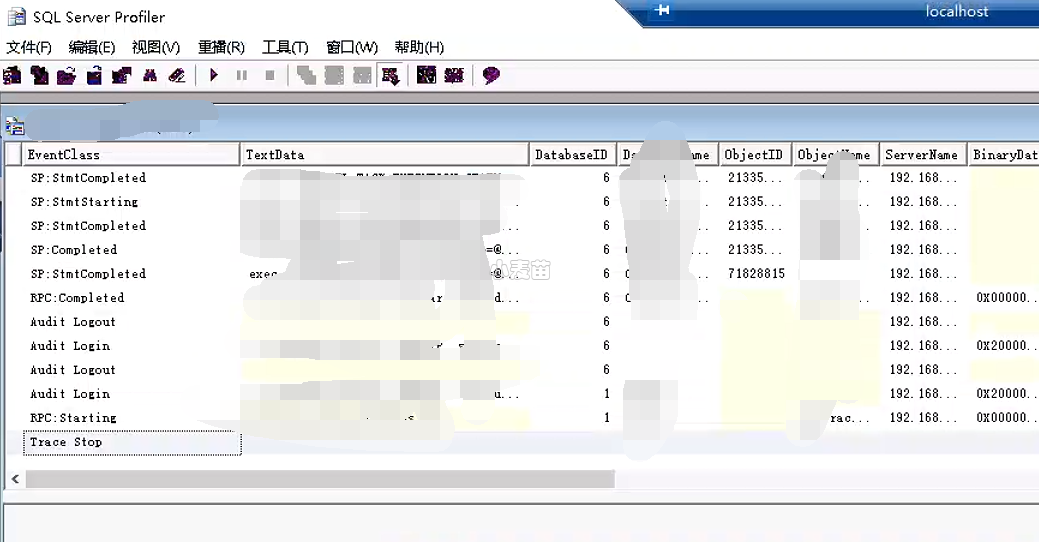
另外,开启SQL Server Profiler还不够,还需要做3个事情:
1、拷贝原来的存储过程来创建新的存储过程,可以以debug结尾,例如:sp_aaa 重建为sp_aaa_debug
2、修改sp_aaa_debug存储过程内容,把里边的#修改为##号,好处是,可以在新开的窗口中分析其执行计划(有的场景仍然不能显示)
3、执行存储过程时,若存储过程内容少且无循环语句,则可以选择“包括实际的执行计划”功能,这样,我们可以分析出来存储过程中每一步的执行计划,方便通过执行计划进行调优。
在观察执行计划时,重点关注rid,Key Lookup、开销比较大的步骤等,这些都是我们需要调优的地方。
1、step 128调优
step 128执行时间历史:
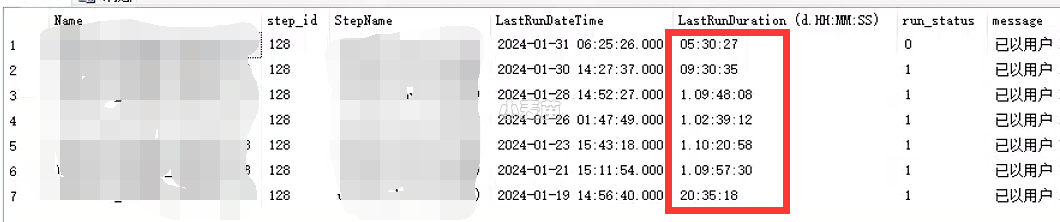
该存储过程由于之前的碎片重建和缺失索引创建,性能已经有所提升,从1天多到10小时,再到5小时。
接下来,继续SQL级别的调优。
在进行setp 128跟踪调优时,发现有一类插入语句很慢,
1 | select * from sql3 where Duration>=6000000; |
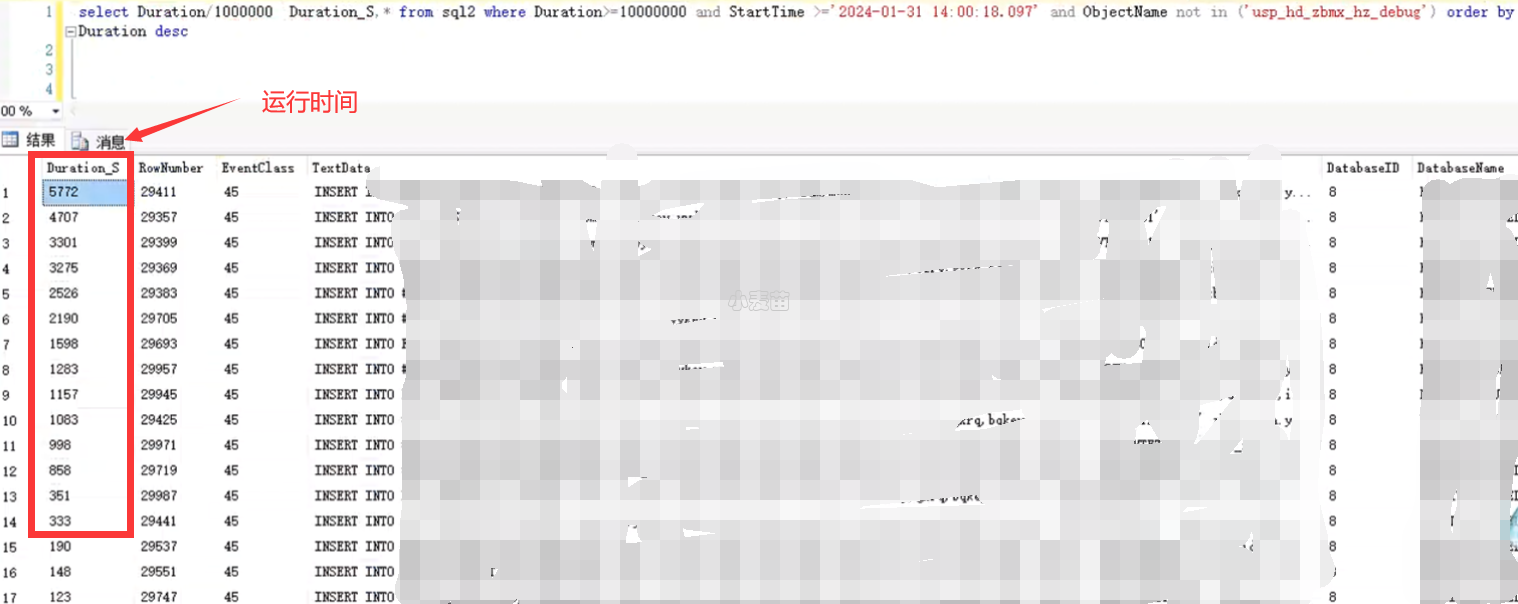
虽说SQL语句都是插入不同的表中,但是这些SQL语句中都包含了一个共同的表,暂且叫FACT_AA表,查询该表的信息:
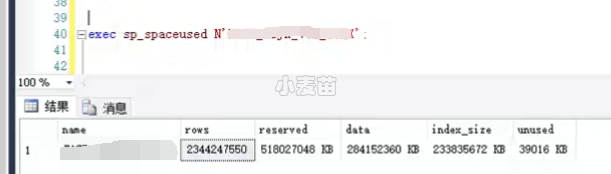
可以看到,该表大概 23亿,300GB大小。
找业务人员确认,只需要保留1个月的数据即可,做如下清理操作:
1 2 3 4 5 6 7 8 9 10 | select min(timekey),max(timekey) from FACT_AA select max(timekey) from FACT_AA where timekey >= getdate()-30 select * into FACT_AA_tmp from FACT_AA where timekey >= getdate()-30 EXEC sp_rename 'FACT_AA', 'FACT_AA_bk'; EXEC sp_rename 'FACT_AA_tmp', 'FACT_AA'; -- SSMS右键获取创建索引的语句,创建索引。。。 |
修改相关存储过程,并定期进行清理该表。
最终,step 128调优后的总运行时间为30分钟左右:
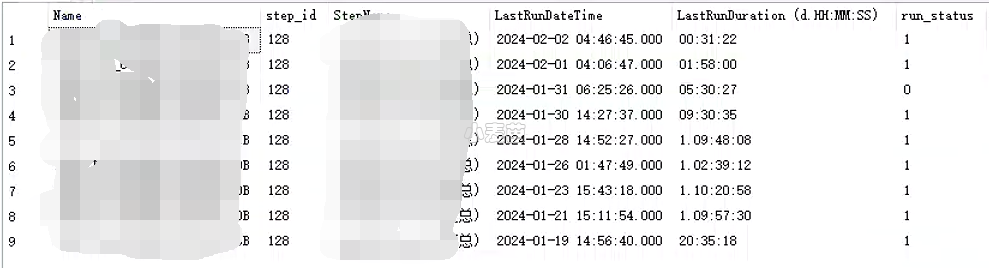
2、step 3调优
step 3执行时间历史:

该存储过程由于之前的碎片重建和缺失索引创建,性能也已经有所提升,从7小时到4小时,再到3小时。
接下来,继续SQL级别的调优。
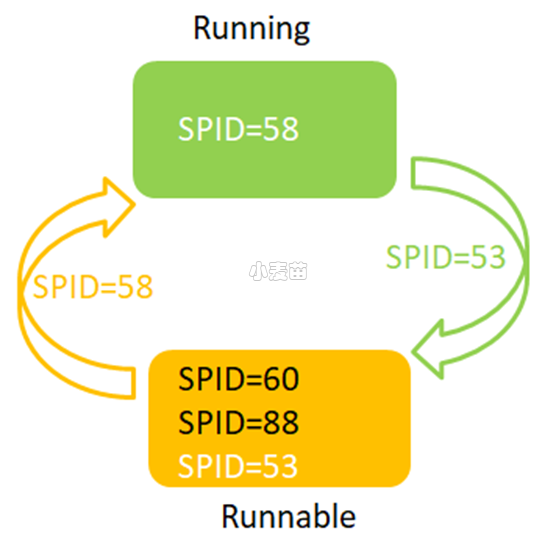
在进行setp 3 跟踪调优时,发现有一个插入语句很慢,查询该进程的等待事件发现是SOS_SCHEDULER_YIELD,查询SQL如下:
1 2 3 4 | -- 某个进程具体等待 SELECT sp.status,sp.cmd,sp.lastwaittype,sp.waitresource,sp.cpu,sp.physical_io,sp.spid,kpid,blocked,dbid FROM master.dbo.sysprocesses sp WITH(NOLOCK) where sp.spid=126; |
如图所示:
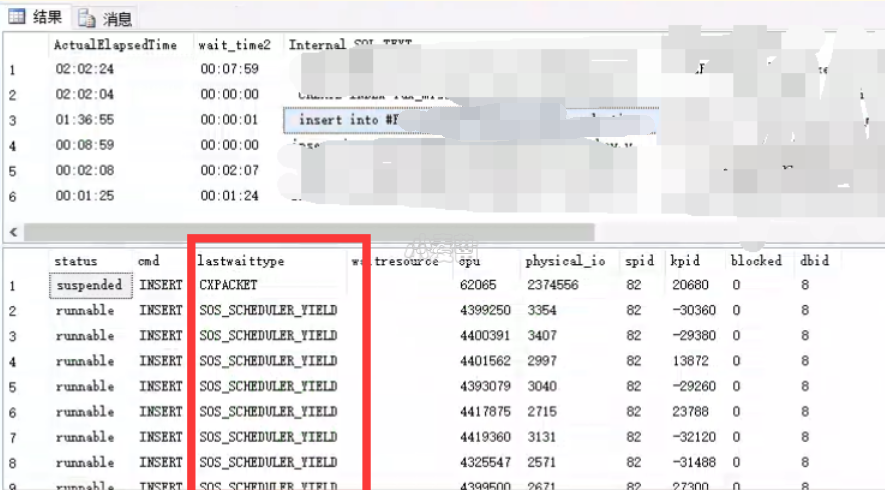
SOS_SCHEDULER_YIELD该等待事件比较有意思,表示一个任务自愿放弃当前的资源占用,让给其他任务使用。 有关该等待事件可以参考:https://www.dbaup.com/sql-serverzhongdedengdaishijiansos_scheduler_yieldshuoming.html