原 GreenPlum备份恢复工具之gpbackup和gprestore
Tags: 原创GreenPlum数据迁移备份恢复gpbackupgprestore增量备份逻辑备份恢复全量备份增量恢复全量恢复
- 简介及总结
- 安装gpbackup和gprestore
- 下载
- 安装
- gppkg安装
- 命令帮助
- gpbackup帮助命令
- gprestore帮助命令
- gpbackup_manager帮助命令
- 使用示例
- gpbackup
- 常规备份,只指定--dbname参数
- 指定--backup-dir参数进行备份
- 指定--data-only参数只备份数据
- 指定--jobs参数进行并行备份
- 指定--single-data-file参数将segment数据备份成单个文件
- 指定--incremental参数进行增量备份
- gprestore
- 常规恢复,只指定 --timestamp 参数
- 指定 --create-db 参数,自动创建数据库
- 指定 --truncate-table 参数,恢复前把表清空
- 指定 --redirect-schema 参数,恢复到指定的模式
- 指定 --on-error-continue 参数,遇到问题并继续
- 指定 --redirect-db 参数,恢复到特定数据库
- 备份恢复操作的状态码
- 邮件告警配置
- 编写配置文件 gp_email_contacts.yaml
- gpbackup
- 概要
- 描述
- 选项
- 返回码
- 模式和表名
- 示例
- gprestore
- 概要
- 描述
- 选项
- Return Codes
- 示例
- 效率比较
- 异机备份恢复、segment节点数不同的说明
- 8个segment备份后还原到 16个segment
- 16个segment备份后还原到 8个segment(报错)
- 异机备份时的gpsegX对应问题
- 数据库版本不一致
- 全量+增量备份
- 参数--copy-queue-size和--jobs性能测试
- 备份测试
- 恢复测试
- 删除备份集
- 参考
简介及总结
有关gpbackup和gprestore有如下总结点,其它请参考:https://www.dbaup.com/greenplumshujukudebeifenhehuifu.html
1、gpbackup和gprestore是一个逻辑备份工具
2、gpbackup和gprestore是可以并行备份的工具
3、gpbackup和gprestore支持增量备份和压缩备份等功能,增量备份只对AO表起作用
4、gpbackup和gprestore是GreenPlum官方提供的备份恢复工具
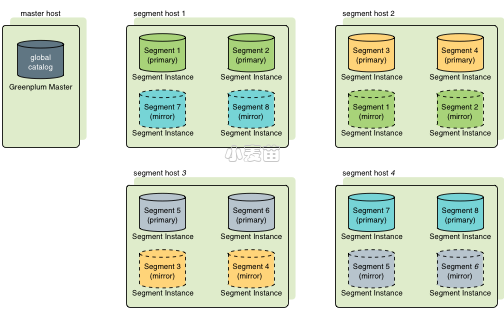
5、默认情况下,gpbackup仅在Greenplum数据库master数据目录中存储备份的对象元数据文件和DDL文件。 Greenplum数据库节点使用COPY … ON SEGMENT命令将备份表的数据存储在位于每个节点的backups目录中的压缩CSV数据文件中。
6、需要额外进行安装,默认安装包不带该工具
7、工具是基于Golang写的
8、gpbackup 的必选参数只有 --dbname,每次只能备份一个数据库,其他参数均为可选参数,有些参数之间是存在互斥关系的,建议命令:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | -- 生成备份命令 SELECT 'gpbackup --dbname='||datname||' --backup-dir=/home/gpadmin/bk/ --jobs=8' bk, 'gpbackup --dbname='||datname||' --jobs=16 --plugin-config /home/newgp/s3-config.yaml' bk2, 'gprestore --backup-dir=/home/gpadmin/bk/ --timestamp=20230724123806 --jobs 8 --create-db --redirect-db '||datname||' --on-error-continue' restore, pg_size_pretty(pg_database_size(datname)) db_size FROM pg_database WHERE datname not in ('template0','template1','postgres','gpperfmon') ORDER BY pg_database_size(datname) desc ; -- 备份路径 gpssh -f ~/conf/all_hosts -v -e 'mkdir -p /home/gpadmin/bk/' ==================================== -- 每个segment主实例单个备份文件(例如,某个sdw1上有4个p实例,则备份会生成4个压缩文件) -- 若使用--single-data-file参数,则备份和还原都不能使用--jobs参数,但可以使用--copy-queue-size参数表示同时备份或恢复几个表,默认为1,性能提升主要在恢复 -- 注意: -- 1、使用--single-data-file --copy-queue-size 8参数和不加--copy-queue-size 8参数在备份时的效率差距没有多大(400个表,200g数据,测试--copy-queue-size参数,备份效率并没有多大变化) -- 2、若备份时未使用--copy-queue-size 8参数,但在还原时也可以使用--copy-queue-size 8参数,但性能并不会提升多少;若在备份和恢复时都使用了--copy-queue-size 8参数,则恢复的性能会有很大提升 -- 3、有该参数时,只会稍微提高性能,但是也更容易引起阻塞 gpbackup --dbname=db1 --backup-dir=/home/gpadmin/bk/ --single-data-file --copy-queue-size 8 gprestore --backup-dir=/home/gpadmin/bk/ --timestamp=20230724123806 --copy-queue-size 8 --create-db --redirect-db db1 --on-error-continue ==================================== -- 使用jobs备份成多个文件 gpbackup --dbname=db1 --backup-dir=/home/gpadmin/bk/ --jobs=8 -- 备份单个schema gpbackup --dbname db1 --backup-dir=/home/gpadmin/bk/ --include-schema='public' --jobs=10 -- 恢复 gprestore --backup-dir=/home/gpadmin/bk/ --timestamp=20230724123806 --jobs 8 --create-db --redirect-db db1 --on-error-continue -- 备份日志 find /data2/bk/gpseg-1/backups/ -name gpbackup_*_report -- 单表备份恢复(3节点9个实例,单表260GB,备份5分钟,备份文件22GB,恢复18分钟) gpssh -f ~/conf/all_hosts -v -e 'mkdir -p /data/gpdb/bk' gpbackup --dbname="HDW_20" --backup-dir=/data/gpdb/bk/ --include-table="public"."eport_result" create database db2; gprestore --backup-dir=/data/gpdb/bk/ --timestamp=20231229192249 --redirect-db db2 --on-error-continue scp -r -c aes192-cbc /data/gpdb/bk/* gpadmin@10.8.31.76:/data/gpdb/bk/ -- 不建议元数据和数据分开迁移,因为先创建索引后再导入数据会很慢 -- 只迁移元数据 gpbackup --dbname=HDW --backup-dir=/home/gpadmin/bk/ --metadata-only gprestore --backup-dir=/home/gpadmin/bk/ --timestamp=20240731133106 --metadata-only --create-db --redirect-db HDW --on-error-continue -- 只迁移数据 gpbackup --dbname=HDW --backup-dir=/home/gpadmin/bk/ --single-data-file --copy-queue-size 8 --leaf-partition-data gprestore --backup-dir=/home/gpadmin/bk/ --timestamp=20240730185544 --data-only --redirect-db HDW --on-error-continue -- 只迁移元数据2 gpbackup --dbname=HDW --backup-dir=/home/gpadmin/bk/ --metadata-only gprestore --backup-dir=/home/gpadmin/bk/ --timestamp=20240731133106 --metadata-only --create-db --redirect-db HDW --on-error-continue -- 只迁移数据2 gpbackup --dbname=HDW --backup-dir=/home/gpadmin/bk/ --data-only --jobs=12 --exclude-schema=odr60_tmp --exclude-schema=tmp gprestore --backup-dir=/home/gpadmin/bk/ --timestamp=20240730185544 --data-only --redirect-db HDW --on-error-continue |
9、一般备份要比恢复快很多,所以恢复的时候一定要加上--jobs或--copy-queue-size参数。这2个参数在数据库有特大表存在的时候,对整个备份进度影响不大,但恢复的时候会有很大提升。另外,并发度不能太高(配置8、12、16即可),否则也影响整体的效率。 这2个参数在备份效率方面并没有差很多。
10、gpbackup在每个独立的表级别使用ACCESS SHARE锁,而不是在pg_class catalog表里加EXCLUSIVE锁。 这使得你可以在backup期间执行任意查询和DML语句,但是如CREATE,ALTER,DROP和TRUNCATE操作,则这些操作会被阻塞。可以考虑通过--exclude-table-file=/home/gpadmin/exclude_tb.txt、--include-schema=public或 --exclude-schema=tmp等参数排除掉不需要的表或schema,但是建表语句也会处于排队状态,删表语句会处于阻塞状态,影响还是比较大的,不过这些可能和版本有一定的关系,我测试的不同版本情况不太一样,在生产环境上还是要慎重。
11、若不指定备份路径--backup-dir参数,则备份文件会保存在 $MASTER_DATA_DIRECTORY/backups/YYYYMMDD/YYYYMMDDhhmmss/ 路径下
12、若还原的集群和备份的集群的segment个数不一样,则还原时需要添加--resize-cluster参数,该参数仅在gpbackup 1.30.5后才生效。
Invoke this option to enable restoring data to a cluster that has a different number of segments than the cluster from which the data was backed up.
In order to enable the
--resize-clusterfeature you must take backups usinggpbackup1.30.5 or later.
13、若源集群和目标集群的segment数不一致,则分为如下情况:
1、源<目标 ,则备份文件需要拷贝到至少和源一样的segment上
2、源>目标,不能恢复,报错Expected to find 4 file(s) on segment 2 on host sdw1, but found 6 instead.(目前未解决)
14、gpbackup_manager可以列出历史备份信息,这些信息存储在$MASTER_DATA_DIRECTORY/gpbackup_history.db的SQLite的数据库文件中。所以,若要清空历史备份信息,则直接删除文件rm -rf $MASTER_DATA_DIRECTORY/gpbackup_history.db即可。 只有当GreenPlum数据库正常运行时,才可以使用gpbackup_manager工具。
15、若源端和目标端的数据库大版本或小版本不一致,也可以使用gpbackup和gprestore进行备份和还原,但是要保证源端和目标端的gpbackup和gprestore的版本是一样的。例如从GP6备份,还原到GP7上经测试也可以。 若生产上使用,还需进一步详细测试。
16、若使用--single-data-file --copy-queue-size 8参数进行备份,4个节点,16个segment实例,备份1T数据量大约需要1小时
17、gprestore过程是先创建表,再copy导入数据,最后再创建索引。
18、备份时的会话查询:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | SELECT pgsa.pid, ( case when pgsa.waiting='t' then (SELECT max(nb2.pid) FROM (select a1.relation,a1.database,a1.pid from pg_locks a1 where a1.pid=pgsa.pid and a1.database>0 and a1.gp_segment_id=-1 and a1.GRANTED='f' ) nb1 left join pg_locks nb2 on (nb1.relation=nb2.relation and nb1.database=nb2.database and nb1.pid!=nb2.pid and nb2.gp_segment_id=-1 and nb2.GRANTED='t' )) end ) as blocking_pid, -- pg_blocking_pids(pid) AS blocking_pid, TO_CHAR(INTERVAL '1 second' * trunc(EXTRACT(epoch FROM (NOW() - pgsa.query_start))), 'HH24:MI:SS') AS query_runtime, TO_CHAR(INTERVAL '1 second' * trunc(EXTRACT(epoch FROM (NOW() - pgsa.xact_start))), 'HH24:MI:SS') AS xact_runtime, pgsa.sess_id, pgsa.client_port, pgsa.datname AS datname, pgsa.usename AS usename, (SELECT nb.rrrsqname from gp_toolkit.gp_resq_role nb where nb.rrrolname=pgsa.usename) rsqname, pgsa.client_addr client_addr, pgsa.application_name AS application_name, pgsa.state AS state, pgsa.waiting, pgsa.waiting_reason, pgsa.backend_start AS backend_start, pgsa.xact_start AS xact_start, state_change, pgsa.query_start AS query_start, TRUNC(EXTRACT( epoch FROM (NOW() - pgsa.xact_start) )) AS xact_stay, trunc(EXTRACT( epoch FROM (NOW() - pgsa.query_start) )) AS query_stay, REPLACE(pgsa.QUERY, chr(10), ' ') AS QUERY, 'select pg_terminate_backend('||pgsa.pid||');' kill1, 'select pg_cancel_backend('||pgsa.pid||');' kill2 FROM pg_stat_activity AS pgsa WHERE pgsa.state not in ( 'idle','idle in transaction (aborted)' ) and pgsa.application_name like 'gpbackup_%' or pgsa.application_name like 'gprestore_%' and pgsa.pid not in (pg_backend_pid()) ORDER BY query_stay DESC,xact_stay DESC LIMIT 1000; |
19、该工具在系统内部采用SSH连接执行各项操作任务。在大型Greenplum集群、云部署或每台主机部署了大量的 segment实例时,可能会遇到超过主机最大授权连接数限制的情况。此时需要考虑更新SSH配置参数MaxStartups 以提高该限制。
1 2 3 4 5 6 7 | cat >> /etc/ssh/sshd_config <<"EOF" MaxSessions 1000 MaxStartups 1000 # MaxStartups 50:80:200 EOF systemctl restart sshd |
20、gpbackup的--exclude-table-file和--include-table-file参数不能添加数据库名,示例如下:
1 2 | "public"."t1" "public"."t2" |
21、增量备份参数--incremental,需要与--leaf-partition-data参数同时使用,并且在创建基础全量备份时,也必须带有--leaf-partition-data参数,否则增量备份找不到基础备份会报错退出。另外增量备份只对AO表有效,Heap表每次都会进行全量备份。
1 2 3 4 | [CRITICAL]:-The flags of the backup with timestamp = 20240630101503 does not match that of the current one. Please refer to the report to view the flags supplied for the previous backup. [CRITICAL]:-There was no matching previous backup found with the flags provided. Please take a full backup. |
增量恢复时需要添加参数: --data-only --incremental
21、官方文档:
22、异地备份到S3存储,建议使用新用户gpbk进行备份,配置PGUSER参数和pg_hba.conf文件即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | create user gpbk pasword 'lhr' superuser; vi $MASTER_DATA_DIRECTORY/pg_hba.conf host all gpbk 127.0.0.1/32 trust gpstop -u cat > /home/gpadmin/s3_config.yaml <<"EOF" executablepath: $GPHOME/bin/gpbackup_s3_plugin options: region: endpoint: http://192.16.7.162:9001 aws_access_key_id: YcZocbjsiEn3wOYrq28X aws_secret_access_key: p5oejaWSRFMIm0nT0LzYPn6v28D0jTEmDhmN5YqD bucket: gpbk folder: HDW EOF gpbackup --dbname HDW --jobs=16 --plugin-config /home/gpadmin/s3_config.yaml gprestore --plugin-config /home/gpadmin/s3_config.yaml --timestamp=20240829095143 --jobs 8 --create-db --redirect-db test2 --on-error-continue |
脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | cat > /home/gpadmin/bkgp_minio.sh <<"EOF00" #!/bin/bash . /usr/local/greenplum-db/greenplum_path.sh . /home/gpadmin/.bashrc . /home/gpadmin/.bash_profile export PGUSER=gpbk # delete 2 months ago bakcups # DELETE_DATE=`date -d "2 months ago" +%Y%m%d%H%M%S` # echo Y | gpbackup_manager delete-backups-before $DELETE_DATE --plugin-config /home/gpadmin/s3_config.yaml # delete all backups DELETE_DATE=`date +%Y%m%d%H%M%S` echo Y | gpbackup_manager delete-backups-before $DELETE_DATE --plugin-config /home/gpadmin/s3_config.yaml cat > /home/gpadmin/s3_config.yaml <<"EOF" executablepath: $GPHOME/bin/gpbackup_s3_plugin options: region: endpoint: http://192.16.7.162:9001 aws_access_key_id: 12345678 aws_secret_access_key: 12345678 bucket: gpbk folder: gpdb7 EOF gpbackup --dbname=db1 --jobs=16 --plugin-config /home/gpadmin/s3_config.yaml gpbackup --dbname=sbtest --jobs=16 --plugin-config /home/gpadmin/s3_config.yaml gpbackup --dbname=db2 --jobs=16 --plugin-config /home/gpadmin/s3_config.yaml gpbackup --dbname=postgres --jobs=16 --plugin-config /home/gpadmin/s3_config.yaml EOF00 chmod +x /home/gpadmin/bkgp_minio.sh 0 20 * * 5 sh /home/gpadmin/bkgp_minio.sh > /tmp/bkgp_minio.log /* 生成备份脚本 select datname AS database_name,pg_size_pretty(pg_database_size(datname)) AS db_size, 'gpbackup --dbname='||datname||' --jobs=16 --plugin-config /home/gpadmin/s3_config.yaml' bk from pg_database d WHERE d.datname not in ('template0','template1','gpperfmon') order by pg_database_size(datname) desc ; */ |
23、异地备份到sshfs文件系统,建议使用新用户gpbk进行备份,配置PGUSER参数和pg_hba.conf文件即可:
安装gpbackup和gprestore
安装参考:
下载
下载地址(最新版1.30.5):
- https://github.com/greenplum-db/gpbackup
- https://network.pivotal.io/products/pivotal-gpdb-backup-restore (推荐)
注意:
1、官网下载比GitHub多gpbackup_ddboost_plugin、gpbackup_s3_plugin和gpbackup_manager这几个文件,且目录稍有不同。
2、建议使用官网的工具。

安装
需要安装在所有的master、standby master和所有segment主机上:
使用gpadmin用户在master节点执行即可:
1 2 3 4 5 6 7 8 | -- 拷贝 gpscp -v -f ~/conf/all_hosts greenplum_backup_restore-1.30.5-rhel7.tar.gz =:/tmp/ -- 安装 gpssh -f ~/conf/all_hosts -v -e 'tar -xzvf /tmp/greenplum_backup_restore-1.30.5-rhel7.tar.gz -C $GPHOME/' -- 测试 gpssh -f ~/conf/all_hosts -v -e 'gpbackup --version' |
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | [gpadmin@mdw tmp]$ gpscp -v -f ~/conf/seg_hosts greenplum_backup_restore-1.30.5-rhel7.tar.gz =:/soft/ [INFO] scp -o "BatchMode yes" -o "StrictHostKeyChecking no" greenplum_backup_restore-1.30.5-rhel7.tar.gz sdw1:/soft/ [INFO] scp -o "BatchMode yes" -o "StrictHostKeyChecking no" greenplum_backup_restore-1.30.5-rhel7.tar.gz sdw2:/soft/ [INFO] completed successfully [gpadmin@mdw tmp]$ gpssh -f ~/conf/all_hosts -v -e 'tar -xzvf /soft/greenplum_backup_restore-1.30.5-rhel7.tar.gz -C $GPHOME/' Using delaybeforesend 0.05 and prompt_validation_timeout 1.0 [Reset ...] [INFO] login mdw [INFO] login sdw1 [INFO] login sdw2 [ mdw] tar -xzvf /soft/greenplum_backup_restore-1.30.5-rhel7.tar.gz -C /usr/local/greenplum-db-6.25.2/ [ mdw] bin/ [ mdw] bin/gpbackup [ mdw] bin/gpbackup_manager [ mdw] bin/gpbackup_helper [ mdw] bin/gpbackup_ddboost_plugin [ mdw] bin/gprestore [ mdw] bin/gpbackup_s3_plugin [ mdw] lib/ [ mdw] lib/libDDBoost.so [ mdw] open_source_licenses_VMware_Greenplum_Backup_and_Restore.txt [sdw1] tar -xzvf /soft/greenplum_backup_restore-1.30.5-rhel7.tar.gz -C /usr/local/greenplum-db-6.25.2/ [sdw1] bin/ [sdw1] bin/gpbackup [sdw1] bin/gpbackup_manager [sdw1] bin/gpbackup_helper [sdw1] bin/gpbackup_ddboost_plugin [sdw1] bin/gprestore [sdw1] bin/gpbackup_s3_plugin [sdw1] lib/ [sdw1] lib/libDDBoost.so [sdw1] open_source_licenses_VMware_Greenplum_Backup_and_Restore.txt [sdw2] tar -xzvf /soft/greenplum_backup_restore-1.30.5-rhel7.tar.gz -C /usr/local/greenplum-db-6.25.2/ [sdw2] bin/ [sdw2] bin/gpbackup [sdw2] bin/gpbackup_manager [sdw2] bin/gpbackup_helper [sdw2] bin/gpbackup_ddboost_plugin [sdw2] bin/gprestore [sdw2] bin/gpbackup_s3_plugin [sdw2] lib/ [sdw2] lib/libDDBoost.so [sdw2] open_source_licenses_VMware_Greenplum_Backup_and_Restore.txt [INFO] completed successfully [Cleanup...] [gpadmin@mdw tmp]$ [gpadmin@mdw tmp]$ gpssh -f ~/conf/all_hosts -v -e 'gpbackup --version' Using delaybeforesend 0.05 and prompt_validation_timeout 1.0 [Reset ...] [INFO] login sdw2 [INFO] login mdw [INFO] login sdw1 [sdw2] gpbackup --version [sdw2] gpbackup version 1.30.5 [ mdw] gpbackup --version [ mdw] gpbackup version 1.30.5 [sdw1] gpbackup --version [sdw1] gpbackup version 1.30.5 [INFO] completed successfully [Cleanup...] |
gppkg安装
在GP数据库启动的情况下安装:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | -- GP6 [gpadmin@gpdb6270 soft]$ gppkg -i greenplum_backup_restore-1.30.6-gp6-rhel7-x86_64.gppkg 20240829:09:41:25:1589843 gppkg:gpdb6270:gpadmin-[INFO]:-Starting gppkg with args: -i greenplum_backup_restore-1.30.6-gp6-rhel7-x86_64.gppkg 20240829:09:41:25:1589843 gppkg:gpdb6270:gpadmin-[INFO]:-Installing package greenplum_backup_restore-1.30.6-gp6-rhel7-x86_64.gppkg 20240829:09:41:25:1589843 gppkg:gpdb6270:gpadmin-[INFO]:-Validating rpm installation cmdStr='rpm --test -i /usr/local/greenplum-db-6.27.0/.tmp/gpbackup_tools_RHEL7-1.30.6-1.x86_64.rpm --dbpath /usr/local/greenplum-db-6.27.0/share/packages/database --prefix /usr/local/greenplum-db-6.27.0' 20240829:09:41:28:1589843 gppkg:gpdb6270:gpadmin-[INFO]:-Installing greenplum_backup_restore-1.30.6-gp6-rhel7-x86_64.gppkg locally 20240829:09:41:28:1589843 gppkg:gpdb6270:gpadmin-[INFO]:-Validating rpm installation cmdStr='rpm --test -i /usr/local/greenplum-db-6.27.0/.tmp/gpbackup_tools_RHEL7-1.30.6-1.x86_64.rpm --dbpath /usr/local/greenplum-db-6.27.0/share/packages/database --prefix /usr/local/greenplum-db-6.27.0' 20240829:09:41:28:1589843 gppkg:gpdb6270:gpadmin-[INFO]:-greenplum_backup_restore-1.30.6-gp6-rhel7-x86_64.gppkg is already installed. 20240829:09:41:28:1589843 gppkg:gpdb6270:gpadmin-[INFO]:-gpbackup 1.30.6 successfully installed 20240829:09:41:28:1589843 gppkg:gpdb6270:gpadmin-[INFO]:-greenplum_backup_restore-1.30.6-gp6-rhel7-x86_64.gppkg successfully installed. [gpadmin@gpdb6270 soft]$ gpbackup gpbackup gpbackup_ddboost_plugin gpbackup_helper gpbackup_manager gpbackup_s3_plugin -- GP7 [gpadmin@gpdb7 ~]$ gppkg install /soft/greenplum_backup_restore-1.30.6-gp7-rhel8-x86_64.gppkg Detecting network topology: [==============================================================] [OK] 2 coordinators and 4 segment instances are detected on 1 unique host. Distributing package: [==============================================================] [OK] Decoding package: [==============================================================] [OK] Verifying package installation:[==============================================================] [OK] Verifying package integrity: [==============================================================] [OK] You are going to install the following packages: Install 'greenplum_backup_restore@1.30.6-gp7' Continue? [y/N] y Allocating disk space: [==============================================================] [OK] Install 'greenplum_backup_rest:[==============================================================] [OK] Result: greenplum_backup_restore has been successfully installed Clean Up: [==============================================================] [OK] [gpadmin@gpdb7 ~]$ gpbackup gpbackup gpbackup_ddboost_plugin gpbackup_helper gpbackup_manager gpbackup_s3_plugin |
命令帮助
gpbackup帮助命令
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | [chris@gpt1 ~]$ gpbackup --help gpbackup is the parallel backup utility for Greenplum Usage: gpbackup [flags] Flags: --backup-dir string `可选参数`, 写入备份文件的绝对路径,不能采用相对路径,如果您指定了该路径,备份操作会将所有备份文件(包括元数据文件)都放到这个目录下。如果您不指定这个选项,元数据文件会保存到Master节点的 `$MASTER_DATA_DIRECTORY/backups/YYYYMMDD/YYYYMMDDhhmmss/` 目录下,数据文件会存放在segment主机的 `<seg_dir>/backups/YYYYMMDD/ YYYYMMDDhhmmss/`目录下。该选项不能与 `--plugin-config` 选项共同使用。 --compression-level int `可选参数`, 压缩级别。大家需要注意,在当前随GPDB版本发布的gpbackup包中,只支持gzip压缩格式,如果您自行编译gpbackup,可以看到已经增加了 `compression-type` 类型,该类型支持其他的压缩类型。压缩级别的默认值为1,gpbackup在备份时,会默认启用gzip压缩。 --compression-type string `可选参数`, 压缩类型。有效值有 'gzip','zstd',默认为 'gzip',如果要使用 'zstd' 压缩,需要在所有服务器上安装该压缩类型以保证shell可以执行 `zstd` 命令,安装方式参考:https://github.com/facebook/zstd 。 --copy-queue-size int `可选参数`, 自行编译最新版本gpbackup带有的参数,该参数只能配合 `--single-data-file` 参数一起使用,当定义了 `--single-data-file` 参数以后,通过执行 `--copy-queue-size` 参数的值来指定gpbackup命令使用COPY命令的个数,默认值为1。 --data-only `可选参数`, 只备份数据,不备份元数据。 --dbname string `必选参数`, 只要进行备份的数据库名称,必须指定,否则会报错,备份无法进行。 --debug `可选参数`, 显示备份过程中详细的debug信息,通常用在排错场景。 --exclude-schema stringArray `可选参数`, 指定备份操作要排除的数据库模式(schema), 如果要排除多个模式,需要多次定义,不支持 `--exclude-schema=schema1,schema2` 的方式。另外该参数与 '--exclude-schema-file, exclude-table, --exclude-table-file, --include-schema, --include-schema-file, --include-table, --include-table-file' 这几个参数不能同时使用。 --exclude-schema-file string `可选参数`, 包含备份操作要排除的数据库模式的文件,每一行为一个模式名,该文件不能包含多余的符号,如果数据库中的模式包含除了:字母、数字和下划线以外的特殊符号,那么请在文件中用双引号进行包裹。该参数与 '--exclude-schema, --exclude-table, --exclude-table-file, --include-schema, --include-schema-file, --include-table, --include-table-file' 这几个参数不能同时使用。 --exclude-table stringArray `可选参数`, 指定备份操作中要排除的表名,该参数与 '--exclude-schema, --exclude-schema-file, --exclude-table-file, --include-schema, --include-schema-file, --include-table, --include-table-file' 这几个参数不能同时使用。指定表名时,必须使用 `<schema-name>.<table-name>` 的格式指定匹配到具体的模式,如果数据库中的模式包含除了:字母、数字和下划线以外的特殊符号,那么请在文件中用双引号进行包裹。另外该参数也支持多次指定。 --exclude-table-file string `可选参数`, 指定文件包含备份操作中要排除的表名,该参数与 '--exclude-schema, --exclude-schema-file, --exclude-table, --include-schema, --include-schema-file, --include-table, --include-table-file' 这几个参数不能同时使用。指定表名时,必须使用 `<schema-name>.<table-name>` 的格式指定匹配到具体的模式,如果数据库中的模式包含除了:字母、数字和下划线以外的特殊符号,那么请在文件中用双引号进行包裹。如果有多个表,需要在文件中分行多次指定。 --from-timestamp string `可选参数`, 指定增量备份的时间戳。被指定的备份必须有增量备份集,如果没有,备份操作会自动创建一个增量备份集;如果被指定的备份是一个增量备份,则备份操作会向备份集增加一个备份。使用该参数时,必须指定参数 `--leaf-partition-data`, 并且不能与`--data-only或--metadata-only`参数一起使用。如果没有任何全量备份存在,则会报错退出备份过程。 --help 显示命令行参数帮助信息。 --include-schema stringArray `可选参数`, 指定备份操作要包含的数据库模式(schema), 如果要包含多个模式,需要多次定义,不支持 `--include-schema=schema1,schema2` 的方式。另外该参数与 '--exclude-schema, --exclude-schema-file, exclude-table, --exclude-table-file, --include-schema-file, --include-table, --include-table-file' 这几个参数不能同时使用。 --include-schema-file string `可选参数`, 包含备份操作要包含的数据库模式的文件,每一行为一个模式名,该文件不能包含多余的符号,如果数据库中的模式包含除了:字母、数字和下划线以外的特殊符号,那么请在文件中用双引号进行包裹。该参数与 '--exclude-schema, --exclude-schema-file, --exclude-table, --exclude-table-file, --include-schema, --include-table, --include-table-file' 这几个参数不能同时使用。 --include-table stringArray `可选参数`, 指定备份操作中要包含的表名,该参数与 '--exclude-schema, --exclude-schema-file, --exclude-table, --exclude-table-file, --include-schema, --include-schema-file, --include-table-file' 这几个参数不能同时使用。指定表名时,必须使用 `<schema-name>.<table-name>` 的格式指定匹配到具体的模式,如果数据库中的模式包含除了:字母、数字和下划线以外的特殊符号,那么请在文件中用双引号进行包裹。另外该参数也支持多次指定。 --include-table-file string `可选参数`, 指定文件包含备份操作中要包含的表名,该参数与 '--exclude-schema, --exclude-schema-file, --exclude-table, --exclude-table-file, --include-schema, --include-schema-file, --include-table' 这几个参数不能同时使用。指定表名时,必须使用 `<schema-name>.<table-name>` 的格式指定匹配到具体的模式,如果数据库中的模式包含除了:字母、数字和下划线以外的特殊符号,那么请在文件中用双引号进行包裹。如果有多个表,需要在文件中分行多次指定。 --incremental `可选参数`, 增量备份功能,增量备份只支持AO表的增量,Heap表不支持增量备份。指定该选项后,会在备份集合中继续增加增量备份。在GPDB里面,备份可以全部都由全量备份构成,也可以由全量备份+增量备份的方式构成,增量备份必须与前面的全量备份组成一个连续的集合,否则无法进行恢复。如果已经做了一个全量备份但是没有增量备份,那该参数会在备份时创建一个增量备份集;如果全量和增量都已经存在了,那么该参数会在现有增量备份集中增加一个最新的备份;另外也可以通过指定 '--from-timestamp' 参数来改变默认行为。 --jobs int `可选参数`, 指定进行表备份过程中的并行任务数,如果不指定,该值默认为1,gpbackup会使用一个任务(即一个数据库连接)进行备份。可以通过增加该值来提升备份速度,如果指定了大于1的值,备份操作会以表为单位进行并发操作,每个表开启一个单独的事务。需要特别注意的是,指定该参数进行并发备份时,不要进行外部程序操作,否则无法保证多表之间的事物一致性。该参数可以与 `--metadata-only, -- single-data-file, --plugin-config` 参数共同使用。 --leaf-partition-data `可选参数`, 为分区表的每一个叶子节点单独创建备份文件,而不是为整个表创建一个备份文件(默认)。使用该参数配合 `--include-table, -- include-table-file, --exclude-table, --exclude-table-file` 参数可以实现包含或排除叶子节点数据的操作。 --metadata-only `可选参数`, 仅备份元数据(即创建数据库对象的DDL语句),不备份任何实际的生产表数据。 --no-compression `可选参数`, 不启用压缩。 --plugin-config string `可选参数`, 指定plugin配置文件位置,该文件是一个有效的YAML文件,用来指定在备份过程中使用的plugin应用的配置信息。由于备份的plugin通常都是为了将备份放到远程存储,所以该选项不能与 `--backup-dir` 同时使用;例如可以使用s3的库将备份文件放到亚马逊S3存储上。也可以通过开放接口自己编写plugin --quiet `可选参数`, 静默模式,除了warning和error信息都不打印。 --single-data-file `可选参数`, 每个segment的数据备份成一个文件,而不是每个表备份一个文件(默认)。如果指定了该选项,在使用gprestore恢复的时候,不能使用 `--job` 选项进行并发恢复。需要特别注意,如果要使用该参数,需要配合 `gpbackup_helper` 命令一起使用,该命令与gpbackup和gpresotre一起编译生成,需要把这个命令放到所有segment host的greenplum-db/bin目录下。 --verbose `可选参数`, 打印详细日志信息。 --version 打印gpbackup的版本号并退出。 --with-stats `可选参数`, 备份查询计划统计信息。 --without-globals `可选参数`, 不备份全局对象。 |
从上面各个参数的详细解释中,大家也可以得出一个总结,gpbackup 的必选参数只有 --dbname,其他参数均为可选参数,有些参数之间是存在互斥关系的,大家在使用过程中一定要注意。
gprestore帮助命令
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | [chris@gpt1 ~]$ gprestore --help gprestore is the parallel restore utility for Greenplum Usage: gprestore [flags] Flags: --backup-dir string `可选参数`, 写入备份文件的绝对路径,不能采用相对路径,如果您指定了该路径,恢复操作会在所有机器上的这个目录下查找备份文件(包括元数据文件)。如果您不指定这个选项,元数据文件会从Master节点的 `$MASTER_DATA_DIRECTORY/backups/YYYYMMDD/YYYYMMDDhhmmss/` 目录下查找,数据文件会从segment主机的 `<seg_dir>/backups/YYYYMMDD/ YYYYMMDDhhmmss/`目录下查找。该选项不能与 `--plugin-config` 选项共同使用。 --copy-queue-size int `可选参数`, 自行编译最新版本gpbackup带有的参数,该参数只能配合 `--single-data-file` 参数一起使用,当定义了 `--single-data-file` 参数以后,通过执行 `--copy-queue-size` 参数的值来指定gprestore命令使用COPY命令的个数,默认值为1。 --create-db `可选参数`, 在执行数据库对象(metadata)恢复之前先创建数据库,该操作实际上通过复制标准模版数据库template0来实现;如果不指定该参数,默认不会创建数据库,此时就要求该数据库必须存在,否则恢复失败。 --data-only `可选参数`, 仅恢复数据,不恢复表结构信息,这就要求要恢复的表必须已经在数据库中存在。需要特别注意的是,该表上SEQUENCE的值会被恢复成备份时的状态。 --debug `可选参数`, 打印详细的调试信息。 --exclude-schema stringArray `可选参数`, 指定恢复操作要排除的数据库模式(schema), 如果要排除多个模式,需要多次定义,不支持 `--exclude-schema=schema1,schema2` 的方式。另外该参数与 '--exclude-schema-file, exclude-table, --exclude-table-file, --include-schema, --include-schema-file, --include-table, --include-table-file' 这几个参数不能同时使用。 --exclude-schema-file string `可选参数`, 包含恢复操作要排除的数据库模式的文件,每一行为一个模式名,该文件不能包含多余的符号,如果数据库中的模式包含除了:字母、数字和下划线以外的特殊符号,那么请在文件中用双引号进行包裹。该参数与 '--exclude-schema, --exclude-table, --exclude-table-file, --include-schema, --include-schema-file, --include-table, --include-table-file' 这几个参数不能同时使用。 --exclude-table stringArray `可选参数`, 指定恢复操作中要排除的表名,该参数与 '--exclude-schema, --exclude-schema-file, --exclude-table-file, --include-schema, --include-schema-file, --include-table, --include-table-file' 这几个参数不能同时使用。指定表名时,必须使用 `<schema-name>.<table-name>` 的格式指定匹配到具体的模式,如果数据库中的模式包含除了:字母、数字和下划线以外的特殊符号,那么请在文件中用双引号进行包裹。另外该参数也支持多次指定。 --exclude-table-file string `可选参数`, 指定文件包含恢复操作中要排除的表名,该参数与 '--exclude-schema, --exclude-schema-file, --exclude-table, --include-schema, --include-schema-file, --include-table, --include-table-file' 这几个参数不能同时使用。指定表名时,必须使用 `<schema-name>.<table-name>` 的格式指定匹配到具体的模式,如果数据库中的模式包含除了:字母、数字和下划线以外的特殊符号,那么请在文件中用双引号进行包裹。如果有多个表,需要在文件中分行多次指定。 --help 显示命令行参数帮助信息,与具体的恢复操作无关。 --include-schema stringArray `可选参数`, 指定恢复操作要包含的数据库模式(schema), 如果要包含多个模式,需要多次定义,不支持 `--include-schema=schema1,schema2` 的方式。另外该参数与 '--exclude-schema, --exclude-schema-file, exclude-table, --exclude-table-file, --include-schema-file, --include-table, --include-table-file' 这几个参数不能同时使用。 --include-schema-file string `可选参数`, 包含恢复操作要包含的数据库模式的文件,每一行为一个模式名,该文件不能包含多余的符号,如果数据库中的模式包含除了:字母、数字和下划线以外的特殊符号,那么请在文件中用双引号进行包裹。该参数与 '--exclude-schema, --exclude-schema-file, --exclude-table, --exclude-table-file, --include-schema, --include-table, --include-table-file' 这几个参数不能同时使用。 --include-table stringArray `可选参数`, 指定恢复操作中要包含的表名,该参数与 '--exclude-schema, --exclude-schema-file, --exclude-table, --exclude-table-file, --include-schema, --include-schema-file, --include-table-file' 这几个参数不能同时使用。指定表名时,必须使用 `<schema-name>.<table-name>` 的格式指定匹配到具体的模式,如果数据库中的模式包含除了:字母、数字和下划线以外的特殊符号,那么请在文件中用双引号进行包裹。另外该参数也支持多次指定。 --include-table-file string `可选参数`, 指定文件包含恢复操作中要包含的表名,该参数与 '--exclude-schema, --exclude-schema-file, --exclude-table, --exclude-table-file, --include-schema, --include-schema-file, --include-table' 这几个参数不能同时使用。指定表名时,必须使用 `<schema-name>.<table-name>` 的格式指定匹配到具体的模式,如果数据库中的模式包含除了:字母、数字和下划线以外的特殊符号,那么请在文件中用双引号进行包裹。如果有多个表,需要在文件中分行多次指定。 --incremental `可选参数`, `测试功能`: 该选项与 '--data-only' 必须一起使用,仅恢复 '--timestamp' 参数指定的时间戳备份的数据,不恢复之前的全量和增量备份。该功能只对AO表有效,恢复的数据包括Heap表全量数据、最新修改备份的AO表增量数据、最新修改备份的叶子分区增量数据。 --jobs int `可选参数`, 指定进行表恢复过程中的并行任务数,如果不指定,该值默认为1,gprestore会使用一个任务(即一个数据库连接)进行备份。可以通过增加该值来提升备份速度,如果指定了大于1的值,备份操作会以表为单位进行并发操作,每个表开启一个单独的事务。需要特别注意的是,指定该参数进行并发备份时,不要进行外部程序操作,否则无法保证多表之间的事物一致性。该参数与 `-- single-data-file` 参数共同使用时,只能设置为1。 --metadata-only `可选参数`, 只恢复数据库的模式信息,该操作假设数据库中不存在要恢复的表。可以同时配合 '--with- global' 参数恢复数据库全局对象。如果后期想恢复数据,可以配合 '--data-only' 参数一起使用。 --on-error-continue `可选参数`, 指定该参数可以在出现恢复错误时,让恢复操作继续。默认情况下出错后马上退出恢复。在该操作模式下,错误信息会记录到备份目录的对应文件下,元数据恢复错误记录到日志文件 'gprestore_<backup-timestamp>_<restore- time>_error_tables_metadata' 中,生产数据恢复错误记录到日志文件 'gprestore_<backup-timestamp>_<restore- time>_error_tables_data' 中。 --plugin-config string `可选参数`, 指定plugin配置文件位置,该文件是一个有效的YAML文件,用来指定在恢复过程中使用的plugin应用的配置信息。该参数通常对应gpbackup使用该参数的场景,从一些非本地存储设备上进行恢复。 --quiet `可选参数`, 静默模式,除了warning和error信息都不打印。 --redirect-db string `可选参数`, 将数据恢复到指定的数据库,而不是恢复到原来备份的数据库中。 --redirect-schema string `可选参数`, 恢复数据到指定模式,而不是恢复到原来备份的模式中。即使原来的数据来自多个模式的多个表,也可以同时恢复到指定的模式和表中。这个参数必须与参数 '--include-table-file, --include-schema, 或 --include-schema- file' 一起使用以指定原来的表或者模式名称,当然这也决定了我们不能将它与参数 '-- exclude-schema 或 --exclude-table' 同时使用。该参数还可以配合 '--metadata-only 或 --data-only' 来恢复元数据或生产数据。 --run-analyze `可选参数`, 在运行完表数据恢复后,执行 'ANALYZE' 操作,该参数不能与 '--with-stats' 参数同时使用;默认情况下,针对分区表,会ANALYZE根分区,如果您指定了 '--leaf-partition-data' 则只会去ANALYZE对应恢复了数据的子分区。 --timestamp string `必选参数`, 指定要恢复的备份集的时间戳,格式为:'YYYYMMDDHHMMSS'。 --truncate-table `必选参数`, 在恢复之前先把目标表清空,该参数主要为了避免数据重复问题。 --verbose `可选参数`, 打印详细日志信息。 --version 打印gpbackup的版本号并退出。 --with-globals `可选参数`, 恢复全局对象。 --with-stats `可选参数`, 恢复查询计划统计信息。 |
gpbackup_manager帮助命令
gpbackup_manager可以列出历史备份信息,这些信息存储在$MASTER_DATA_DIRECTORY/gpbackup_history.db的SQLite的数据库文件中。所以,若要清空历史备份信息,则直接删除文件rm -rf $MASTER_DATA_DIRECTORY/gpbackup_history.db即可。只有当GreenPlum数据库正常运行时,才可以使用gpbackup_manager工具。只有官方下载的工具才带有该工具。
Greenplum Database must be running to use the
gpbackup_managerutility.Backup history is saved on the Greenplum Database coordinator host in the database
$MASTER_DATA_DIRECTORY/gpbackup_history.db.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | [gpadmin@mdw ~]$ gpbackup_manager -h gpbackup_manager helps manage Greenplum Database backup sets Usage: gpbackup_manager [command] Available Commands: completion Generate the autocompletion script for the specified shell delete-backup Deletes the backup set for the specified timestamp delete-backups-before Deletes all backup sets before the specified timestamp delete-replica Deletes the backup set for the specified timestamp from the specified replica display-report Display the backup report for the specified timestamp encrypt-password Encrypts a plain-text password to use in the DDBoost plugin configuration file find-table Searches the backup history database for backups with specified table help Help about any command list-backups Displays information in list form specific to backups which have been taken migrate-history Migrate backup history from legacy file format into database replicate-backup Replicates the backup set for the specified timestamp Flags: -h, --help help for gpbackup_manager -v, --version version for gpbackup_manager Use "gpbackup_manager [command] --help" for more information about a command. [gpadmin@mdw ~]$ [gpadmin@mdw tmp]$ gpbackup_manager delete-backup 20230822123045 20231103:09:37:38 gpbackup_manager:gpadmin:mdw:490650-[ERROR]:-Missing local backup directory: /home/gpadmin/bk/backups/20230822/20230822123045 [gpadmin@mdw ~]$ gpbackup_manager list-backups timestamp date status database type object filtering plugin duration 20230822123045 Tue Aug 22 2023 12:30:45 Success tpchdb full 00:00:06 20230822123042 Tue Aug 22 2023 12:30:42 Success testdb full 00:00:03 20230822123035 Tue Aug 22 2023 12:30:35 Success test1 full 00:00:07 20230822123032 Tue Aug 22 2023 12:30:32 Success test full 00:00:02 20230822123030 Tue Aug 22 2023 12:30:30 Success template1 metadata-only 00:00:01 20230822123027 Tue Aug 22 2023 12:30:27 Success sbtest full 00:00:03 20230822123024 Tue Aug 22 2023 12:30:24 Success postgres full 00:00:03 20230822123022 Tue Aug 22 2023 12:30:22 Success lhrgpdb metadata-only 00:00:02 20230822123017 Tue Aug 22 2023 12:30:17 Success lhrdb full 00:00:05 20230822123009 Tue Aug 22 2023 12:30:09 Success gpperfmon full 00:00:08 20230822123002 Tue Aug 22 2023 12:30:02 Success db3 full 00:00:07 20230822122956 Tue Aug 22 2023 12:29:56 Success db2 full 00:00:05 20230822122918 Tue Aug 22 2023 12:29:18 Success db1 full 00:00:38 [gpadmin@mdw ~]$ rm -rf $MASTER_DATA_DIRECTORY/gpbackup_history.db [gpadmin@mdw ~]$ gpbackup_manager list-backups 20231103:10:01:00 gpbackup_manager:gpadmin:mdw:801518-[ERROR]:-Cannot find any history of backups. Please create a backup before using this utility. |
使用示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | docker rm -f gpdbbk docker run -itd --name gpdbbk -h gpdbbk --privileged=true lhrbest/greenplum:gpdball_6.25.3 /usr/sbin/init docker cp greenplum_backup_restore-1.30.5-rhel7.tar.gz gpdbbk:/soft/ -q docker exec -it gpdbbk bash docker cp greenplum_backup_restore-1.30.5-rhel7.tar.gz mdw:/soft/ -q docker exec -it mdw su - gpadmin gpstart -a -- 拷贝 gpscp -v -f ~/conf/all_hosts greenplum_backup_restore-1.30.5-rhel7.tar.gz =:/soft/ -- 安装 gpssh -f ~/conf/all_hosts -v -e 'tar -xzvf /soft/greenplum_backup_restore-1.30.5-rhel7.tar.gz -C $GPHOME/bin' -- 测试 gpssh -f ~/conf/all_hosts -v -e 'gpbackup --version' -- 备份 gpssh -f ~/conf/all_hosts -v -e 'mkdir -p /home/gpadmin/bk/' gpbackup --dbname=db1 --backup-dir=/home/gpadmin/bk/ --jobs=8 -- 每个segment主实例单个备份文件(例如,某个sdw1上有4个p实例,则备份会生成4个压缩文件) gpbackup --dbname=db1 --backup-dir=/home/gpadmin/bk/ --single-data-file -- 恢复 gprestore --backup-dir=/home/gpadmin/bk/ --timestamp=20230724123806 --jobs 8 --create-db --redirect-db db1 |
gpbackup
常规备份,只指定--dbname参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | [gpadmin@mdw1 ~]$ gpbackup --dbname db1 20230303:12:16:16 gpbackup:gpadmin:mdw1:655602-[INFO]:-gpbackup version = 1.30.5 20230303:12:16:16 gpbackup:gpadmin:mdw1:655602-[INFO]:-Greenplum Database Version = 6.23.1 build commit:2731a45ecb364317207c560730cf9e2cbf17d7e4 Open Source 20230303:12:16:16 gpbackup:gpadmin:mdw1:655602-[INFO]:-Starting backup of database db1 20230303:12:16:17 gpbackup:gpadmin:mdw1:655602-[INFO]:-Backup Timestamp = 20230303121616 20230303:12:16:17 gpbackup:gpadmin:mdw1:655602-[INFO]:-Backup Database = db1 20230303:12:16:17 gpbackup:gpadmin:mdw1:655602-[INFO]:-Gathering table state information 20230303:12:16:17 gpbackup:gpadmin:mdw1:655602-[INFO]:-Acquiring ACCESS SHARE locks on tables Locks acquired: 5 / 5 [================================================================] 100.00% 0s 20230303:12:16:17 gpbackup:gpadmin:mdw1:655602-[INFO]:-Gathering additional table metadata 20230303:12:16:17 gpbackup:gpadmin:mdw1:655602-[INFO]:-Getting partition definitions 20230303:12:16:17 gpbackup:gpadmin:mdw1:655602-[INFO]:-Getting storage information 20230303:12:16:17 gpbackup:gpadmin:mdw1:655602-[INFO]:-Getting child partitions with altered schema 20230303:12:16:17 gpbackup:gpadmin:mdw1:655602-[INFO]:-Metadata will be written to /opt/greenplum/data/master/gpseg-1/backups/20230303/20230303121616/gpbackup_20230303121616_metadata.sql 20230303:12:16:17 gpbackup:gpadmin:mdw1:655602-[INFO]:-Writing global database metadata 20230303:12:16:17 gpbackup:gpadmin:mdw1:655602-[INFO]:-Global database metadata backup complete 20230303:12:16:17 gpbackup:gpadmin:mdw1:655602-[INFO]:-Writing pre-data metadata 20230303:12:16:18 gpbackup:gpadmin:mdw1:655602-[INFO]:-Pre-data metadata metadata backup complete 20230303:12:16:18 gpbackup:gpadmin:mdw1:655602-[INFO]:-Writing post-data metadata 20230303:12:16:18 gpbackup:gpadmin:mdw1:655602-[INFO]:-Post-data metadata backup complete 20230303:12:16:18 gpbackup:gpadmin:mdw1:655602-[INFO]:-Writing data to file Tables backed up: 5 / 5 [==============================================================] 100.00% 0s 20230303:12:16:18 gpbackup:gpadmin:mdw1:655602-[INFO]:-Data backup complete 20230303:12:16:19 gpbackup:gpadmin:mdw1:655602-[INFO]:-Found neither /usr/local/greenplum-db-6.23.1/bin/gp_email_contacts.yaml nor /home/gpadmin/gp_email_contacts.yaml 20230303:12:16:19 gpbackup:gpadmin:mdw1:655602-[INFO]:-Email containing gpbackup report /opt/greenplum/data/master/gpseg-1/backups/20230303/20230303121616/gpbackup_20230303121616_report will not be sent 20230303:12:16:19 gpbackup:gpadmin:mdw1:655602-[INFO]:-Backup completed successfully [gpadmin@mdw1 ~]$ |
实验总结:
如果只指定数据库名称,会将这个数据库的所有对象都进行备份,例如:元数据、表数据、资源队列、资源组、角色等。
元数据存储在Master节点的$MASTER_DATA_DIRECTORY/backups/YYYYMMDD/YYYYMMDDhhmmss/目录下,会生成4个文件,其中:config.yaml 记录gpbackup 运行时的参数配置项;report记录备份下来的数据库对象信息,主要是对象数量;toc.yaml 记录元数据之间的依赖关系;metadata.sql 记录表结构DDL的详细信息。
Master节点生成的四个文件(standby master无数据):
1 2 3 4 5 6 7 8 | [gpadmin@mdw1 ~]$ ll /opt/greenplum/data/master/gpseg-1/backups/20230303/20230303121616/ total 24 -r--r--r-- 1 gpadmin gpadmin 819 Mar 3 12:16 gpbackup_20230303121616_config.yaml -r--r--r-- 1 gpadmin gpadmin 4279 Mar 3 12:16 gpbackup_20230303121616_metadata.sql -r--r--r-- 1 gpadmin gpadmin 1810 Mar 3 12:16 gpbackup_20230303121616_report -r--r--r-- 1 gpadmin gpadmin 5778 Mar 3 12:16 gpbackup_20230303121616_toc.yaml [gpadmin@mdw1 ~]$ |
生产表数据存储在segment实例的backups目录下,比如我这边/opt/greenplum/data/primary/gpseg0/backups/20230303/20230303121616
默认情况下,每个表生成一个单独的gzip压缩文件,通过pg_class中的oid作为后缀来做表关联对应。segment节点不存储任何生产表数据之外的数据。
1 2 3 4 5 | [root@sdw1 /]# find /opt -name 20230303121616 /opt/greenplum/data/primary/gpseg0/backups/20230303/20230303121616 /opt/greenplum/data/primary/gpseg1/backups/20230303/20230303121616 /opt/greenplum/data/primary/gpseg3/backups/20230303/20230303121616 /opt/greenplum/data/primary/gpseg2/backups/20230303/20230303121616 |
解压打开其中一个表文件看一下,里面是csv内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | [root@sdw1 /]# gunzip /opt/greenplum/data/primary/gpseg0/backups/20230303/20230303121616/gpbackup_0_20230303121616_50799.gz < [root@sdw1 /]# ll /opt/greenplum/data/primary/gpseg0/backups/20230303/20230303121616 total 136 -rw------- 1 gpadmin gpadmin 20 Mar 3 12:16 gpbackup_0_20230303121616_105166.gz -rw------- 1 gpadmin gpadmin 123352 Mar 3 12:16 gpbackup_0_20230303121616_50799 -rw------- 1 gpadmin gpadmin 123352 Mar 3 12:16 gpbackup_0_20230303121616_50799.gz -rw------- 1 gpadmin gpadmin 20 Mar 3 12:16 gpbackup_0_20230303121616_50895.gz -rw------- 1 gpadmin gpadmin 20 Mar 3 12:16 gpbackup_0_20230303121616_50901.gz [root@sdw1 /]# more /opt/greenplum/data/primary/gpseg0/backups/20230303/20230303121616/gpbackup_0_20230303121616_50799 55,b53b3a3d6ab90ce0268229151c9bde11 91,54229abfcfa5649e7003b83dd4755294 98,ed3d2c21991e3bef5e069713af9fa6ca 116,c45147dee729311ef5b5c3003946c48f .... |
如果你想解压x.txt.gz到x.txt,同时保留x.txt.gz,你可以输入:gunzip -c x.txt.gz > x.txt
指定--backup-dir参数进行备份
实验语句:
1 2 3 4 | gpssh -f ~/conf/all_hosts -v -e 'mkdir -p /home/gpadmin/bk/' gpbackup --dbname=db1 --backup-dir=/home/gpadmin/bk/ |
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | [gpadmin@mdw1 ~]$ gpssh -f ~/conf/all_hosts -v -e 'mkdir /home/gpadmin/bk/' Using delaybeforesend 0.05 and prompt_validation_timeout 1.0 [Reset ...] [INFO] login mdw2 [INFO] login sdw3 [INFO] login sdw4 [INFO] login sdw1 [INFO] login mdw1 [INFO] login sdw2 [mdw2] mkdir /home/gpadmin/bk/ [sdw3] mkdir /home/gpadmin/bk/ [sdw4] mkdir /home/gpadmin/bk/ [sdw1] mkdir /home/gpadmin/bk/ [mdw1] mkdir /home/gpadmin/bk/ [sdw2] mkdir /home/gpadmin/bk/ [INFO] completed successfully [Cleanup...] [gpadmin@mdw1 ~]$ [gpadmin@mdw1 ~]$ [gpadmin@mdw1 ~]$ [gpadmin@mdw1 ~]$ gpbackup --dbname=db1 --backup-dir=/home/gpadmin/bk/ 20230303:12:45:08 gpbackup:gpadmin:mdw1:661395-[INFO]:-gpbackup version = 1.30.5 20230303:12:45:08 gpbackup:gpadmin:mdw1:661395-[INFO]:-Greenplum Database Version = 6.23.1 build commit:2731a45ecb364317207c560730cf9e2cbf17d7e4 Open Source 20230303:12:45:08 gpbackup:gpadmin:mdw1:661395-[INFO]:-Starting backup of database db1 20230303:12:45:09 gpbackup:gpadmin:mdw1:661395-[INFO]:-Backup Timestamp = 20230303124508 20230303:12:45:09 gpbackup:gpadmin:mdw1:661395-[INFO]:-Backup Database = db1 20230303:12:45:09 gpbackup:gpadmin:mdw1:661395-[INFO]:-Gathering table state information 20230303:12:45:09 gpbackup:gpadmin:mdw1:661395-[INFO]:-Acquiring ACCESS SHARE locks on tables Locks acquired: 5 / 5 [================================================================] 100.00% 0s 20230303:12:45:09 gpbackup:gpadmin:mdw1:661395-[INFO]:-Gathering additional table metadata 20230303:12:45:09 gpbackup:gpadmin:mdw1:661395-[INFO]:-Getting partition definitions 20230303:12:45:09 gpbackup:gpadmin:mdw1:661395-[INFO]:-Getting storage information 20230303:12:45:09 gpbackup:gpadmin:mdw1:661395-[INFO]:-Getting child partitions with altered schema 20230303:12:45:09 gpbackup:gpadmin:mdw1:661395-[INFO]:-Metadata will be written to /home/gpadmin/bk/gpseg-1/backups/20230303/20230303124508/gpbackup_20230303124508_metadata.sql 20230303:12:45:09 gpbackup:gpadmin:mdw1:661395-[INFO]:-Writing global database metadata 20230303:12:45:09 gpbackup:gpadmin:mdw1:661395-[INFO]:-Global database metadata backup complete 20230303:12:45:09 gpbackup:gpadmin:mdw1:661395-[INFO]:-Writing pre-data metadata 20230303:12:45:09 gpbackup:gpadmin:mdw1:661395-[INFO]:-Pre-data metadata metadata backup complete 20230303:12:45:09 gpbackup:gpadmin:mdw1:661395-[INFO]:-Writing post-data metadata 20230303:12:45:09 gpbackup:gpadmin:mdw1:661395-[INFO]:-Post-data metadata backup complete 20230303:12:45:09 gpbackup:gpadmin:mdw1:661395-[INFO]:-Writing data to file Tables backed up: 5 / 5 [==============================================================] 100.00% 0s 20230303:12:45:10 gpbackup:gpadmin:mdw1:661395-[INFO]:-Data backup complete 20230303:12:45:11 gpbackup:gpadmin:mdw1:661395-[INFO]:-Found neither /usr/local/greenplum-db-6.23.1/bin/gp_email_contacts.yaml nor /home/gpadmin/gp_email_contacts.yaml 20230303:12:45:11 gpbackup:gpadmin:mdw1:661395-[INFO]:-Email containing gpbackup report /home/gpadmin/bk/gpseg-1/backups/20230303/20230303124508/gpbackup_20230303124508_report will not be sent 20230303:12:45:11 gpbackup:gpadmin:mdw1:661395-[INFO]:-Backup completed successfully [gpadmin@mdw1 ~]$ |
实验总结:
指定--backup-dir的操作可以将备份统一到一个固定的目录,这就要求所有服务器上必须都存在--backup-dir后面指定的这个目录,比如我这里的目录是/home/gpadmin/bk。这个适合公司对备份目录有固定要求,或者必须放置到共享存储中的场景,通过定义统一的目录,就可以把所有的备份数据都放在我们可以获知的任意位置(当然管理员用户必须具有目录的访问权限)。
Master节点上的信息展示如下,文件还是那些文件,只不过目录不同了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | [gpadmin@mdw1 bk]$ ll total 0 drwxrwxr-x 3 gpadmin gpadmin 21 Mar 3 12:45 gpseg-1 [gpadmin@mdw1 bk]$ tree . └── gpseg-1 └── backups └── 20230303 └── 20230303124508 ├── gpbackup_20230303124508_config.yaml ├── gpbackup_20230303124508_metadata.sql ├── gpbackup_20230303124508_report └── gpbackup_20230303124508_toc.yaml 4 directories, 4 files [gpadmin@mdw1 bk]$ |
Segment节点上的信息展示如下,可以看到是通过segment名字进行区别,所以不要担心在共享存储中会出现覆盖的问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | [gpadmin@sdw1 bk]$ ll total 0 drwxrwxr-x 3 gpadmin gpadmin 21 Mar 3 12:45 gpseg0 drwxrwxr-x 3 gpadmin gpadmin 21 Mar 3 12:45 gpseg1 drwxrwxr-x 3 gpadmin gpadmin 21 Mar 3 12:45 gpseg2 drwxrwxr-x 3 gpadmin gpadmin 21 Mar 3 12:45 gpseg3 [gpadmin@sdw1 bk]$ du -sh . 348K . [gpadmin@sdw1 bk]$ tree . ├── gpseg0 │ └── backups │ └── 20230303 │ └── 20230303124508 │ ├── gpbackup_0_20230303124508_105166.gz │ ├── gpbackup_0_20230303124508_105176.gz │ ├── gpbackup_0_20230303124508_50799.gz │ ├── gpbackup_0_20230303124508_50895.gz │ └── gpbackup_0_20230303124508_50901.gz ├── gpseg1 │ └── backups │ └── 20230303 │ └── 20230303124508 │ ├── gpbackup_1_20230303124508_105166.gz │ ├── gpbackup_1_20230303124508_105176.gz │ ├── gpbackup_1_20230303124508_50799.gz │ ├── gpbackup_1_20230303124508_50895.gz │ └── gpbackup_1_20230303124508_50901.gz ├── gpseg2 │ └── backups │ └── 20230303 │ └── 20230303124508 │ ├── gpbackup_2_20230303124508_105166.gz │ ├── gpbackup_2_20230303124508_105176.gz │ ├── gpbackup_2_20230303124508_50799.gz │ ├── gpbackup_2_20230303124508_50895.gz │ └── gpbackup_2_20230303124508_50901.gz └── gpseg3 └── backups └── 20230303 └── 20230303124508 ├── gpbackup_3_20230303124508_105166.gz ├── gpbackup_3_20230303124508_105176.gz ├── gpbackup_3_20230303124508_50799.gz ├── gpbackup_3_20230303124508_50895.gz └── gpbackup_3_20230303124508_50901.gz 16 directories, 20 files [gpadmin@sdw1 bk]$ |
指定--data-only参数只备份数据
实验语句:
1 | gpbackup --dbname=db1 --backup-dir=/data/backups/ --data-only |
实验总结:
如果指定了--data-only,Master节点将不会导出创建数据库对象的DDL语句,这个场景只适合于数据临时导出操作,没有表结构,如果恢复的时候数据库中没有表,也无法实现恢复。个人感觉这种场景不太多,毕竟备份一下DDL也不浪费多少时间。
Master节点中查看metadata.sql文件,没有信息,*Segment节点,显然只有表数据
指定--jobs参数进行并行备份
实验语句:
1 | gpbackup --dbname=db1 --backup-dir=/home/gpadmin/bk/ --jobs=8 |
实验总结:
指定了--jobs=2参数以后,理论上在各个节点上备份时,会同时启动两个事务分别备份2个表,我们可以通过数据库的日志进行甄别,如下可以看到,四条日志中,前两条是上一次备份的日志,没开并行,可以看出时间是顺序的;后两条是本次开启2个并行的备份操作,可以看到基本是同一时间发起的:
1 2 3 4 | 2022-04-01 18:49:22.440657 CST,"chris","db3",p23834,th397211776,"10.211.55.65","57566",2022-04-01 18:49:22 CST,0,con119,cmd5,seg0,,dx48,,sx1,"LOG","00000","serializable isolation requested, falling back to repeatable read until serializable is supported in Greenplum",,,,,,"SET transaction_isolation TO 'serializable'",0,,"variable.c",604, 2022-04-01 18:58:33.484600 CST,"chris","db3",p25688,th397211776,"10.211.55.65","57660",2022-04-01 18:58:33 CST,0,con122,cmd5,seg0,,dx49,,sx1,"LOG","00000","serializable isolation requested, falling back to repeatable read until serializable is supported in Greenplum",,,,,,"SET transaction_isolation TO 'serializable'",0,,"variable.c",604, 2022-04-01 19:11:01.668405 CST,"chris","db3",p28223,th397211776,"10.211.55.65","57788",2022-04-01 19:11:01 CST,0,con127,cmd5,seg0,,dx50,,sx1,"LOG","00000","serializable isolation requested, falling back to repeatable read until serializable is supported in Greenplum",,,,,,"SET transaction_isolation TO 'serializable'",0,,"variable.c",604, 2022-04-01 19:11:01.680513 CST,"chris","db3",p28227,th397211776,"10.211.55.65","57796",2022-04-01 19:11:01 CST,0,con128,cmd4,seg0,,dx51,,sx1,"LOG","00000","serializable isolation requested, falling back to repeatable read until serializable is supported in Greenplum",,,,,,"SET transaction_isolation TO 'serializable'",0,,"variable.c",604, |
指定--single-data-file参数将segment数据备份成单个文件
实验语句:
1 2 3 4 | [chris@gpt1 ~]$ gpbackup --dbname=db3 --backup-dir=/data/backups/ --jobs=2 --single-data-file 20220401:20:40:04 gpbackup:chris:gpt1:006190-[CRITICAL]:-The following flags may not be specified together: jobs, metadata-only, single-data-file [chris@gpt1 ~]$ gpbackup --dbname=db3 --backup-dir=/data/backups/ --single-data-file |
实验总结:
在上面的实验中,我首先把--jobs=2和--single-data-file参数同时使用,大家可以发现已经出现报错了,因为不支持这两个参数同时使用。下面第二个命令将并发参数去掉后,可以正常备份,这个参数会影响到segment节点把所有的表数据都备份到同一个文件中,如下查看单个segment备份目录下的文件可以看出:
1 2 3 4 5 6 | [chris@gpt2 20220401204015]$ pwd /data/backups/gp1/backups/20220401/20220401204015 [chris@gpt2 20220401204015]$ ll 总用量 8 -rw-rw-r--. 1 chris chris 247 4月 1 20:40 gpbackup_1_20220401204015.gz -r--r--r--. 1 chris chris 101 4月 1 20:40 gpbackup_1_20220401204015_toc.yaml |
指定--incremental参数进行增量备份
增量备份只对AO表起作用
1 2 | create table tao(id int) with (appendoptimized=true); insert into tao values(1),(2),(3),(4); |
实验总结:
增量备份参数--incremental,需要与--leaf-partition-data参数同时使用,并且在创建基础全量备份时,也必须带有该参数,否则增量备份找不到基础备份会报错退出。另外增量备份只对AO表有效,Heap表每次都会进行全量备份。
gprestore
如果要使用 gprestore 进行数据库恢复,那就要求您必须已经使用 gpbackup 进行了数据库备份,恢复时通过指定 --timestamp 参数把备份集传给 gprestore。如果您指定的是一个增量备份的时间戳,那这个增量备份的 base 全量备份及其他增量文件必须均存在,恢复时会校验备份集合的完整性,防止恢复出错。
在恢复数据时,默认情况下会将数据恢复到 gpbackup 备份的数据库中,如果该数据库已经不存在了,需要通过指定 --create-db 参数来自动创建数据库;如果数据库存在但是模式不存在,也会自动创建模式,如果模式已经存在,则会告警提示并继续恢复数据;如果数据库中同名的表已经存在,则恢复会失败并立刻停止。
常规恢复,只指定 --timestamp 参数
1 | gprestore --backup-dir=/data/backups/ --timestamp=20220402190737 |
如果要进行 数据恢复,请指定备份数据集的时间戳,这些时间戳可以从备份目录的文件夹目录名称获取,只指定一个时间戳时,如果无论您指定的是全量备份还是增量备份的时间戳,都能正常恢复,指定全量备份时,只恢复全量部分; 指定增量备份时间戳时,会恢复改增量及其以前的增量和全量数据。
指定 --create-db 参数,自动创建数据库
实验总结:
--create-db 参数可以帮助我们自动创建数据库,所以我们如果想做全库恢复并且担心数据重复,最好把数据库整个删掉然后直接用该参数执行恢复,这样最省事了。
指定 --truncate-table 参数,恢复前把表清空
由于 --truncate-table 参数是用来清空表的,也就是说表必须是存在的,如果表必须存在,那我们就不需要再恢复 metadata 表结构,此时也就要求我们在使用 --truncate-table 时必须配合 --data-only 一起使用,否则会报错,下面的实验语句,我做了三次,分别实验了:
- 只带有 --truncate-table 参数;
- --truncate-table 参数和 --data-only 参数配合使用;
- --truncate-table 参数和第一个小实验中提示的 --include-table or --include-table-file 参数配合使用(实验报错),因为使用了 --include-table or --include-table-file 参数时,必须配合 --data-only 参数一起使用。
实验总结:
--truncate-table 参数只有和 --data-only 参数一起使用时才会有效,主要是为了防止数据恢复时存在重复的问题。
指定 --redirect-schema 参数,恢复到指定的模式
实验总结:
该实验展示了如何将 public 模式下的所有表恢复到 s1 模式下。您也可以将不同模式下的两个表的数据恢复到另外一个模式下的同一个表,但是这要求我们配合如下参数一起使用:--redirect-schema=s2 --include-table=public.tao --include-table=s1.tao --data-only 。
指定 --on-error-continue 参数,遇到问题并继续
慎用!!!
指定 --redirect-db 参数,恢复到特定数据库
--redirect-db 参数可以将 gpbackup 原来备份的数据库数据恢复到新的数据库中,该参数指定的数据库可以存在也可以不存在,如果数据库不存在,就必须配合 --create-db 参数一起使用。
实验总结:
在一些实验环境下,可以通过该参数从备份快速创建测试数据库,而不必担心对原来的数据库产生什么影响。如果目标数据库不存在,可以配合 --create-db 参数自动创建数据库。
备份恢复操作的状态码
为了方便大家在程序中调用 gpbackup/gprestore 命令后进行成功与否的判断,两个命令执行完成后,均会返回状态码,状态码几其代表的意义如下:
0 - 备份 / 恢复成功,没有错误
1 - 备份 / 恢复成功,没有 fatal 错误
2 - 备份 / 恢复失败,带有 fatal 错误
邮件告警配置
gpbackup 和 gprestore 操作完成后,可以进行邮件告警,如果您想使用该功能,那就需要提前在 $HOME 目录或 $GPHOME/bin/ 目录下创建好发送邮件用的服务器信息配置,如果二者都做了配置,那会以 $HOME 目录下的文件为准。
编写配置文件 gp_email_contacts.yaml
文件格式如下,在创建 YAML 的时候,要保证 YAML 的格式正确:
1 2 3 4 5 6 7 8 9 10 11 12 13 | contacts: gpbackup: - address: yuanzefuwater@126.com status: success: true success_with_errors: true failure: true gprestore: - address: yuanzefuwater@126.com status: success: true success_with_errors: true failure: true |
gpbackup
创建一个可以给gprestore工具使用的Greenplum数据库备份。
概要
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | gpbackup --dbname database_name [--backup-dir directory] [--compression-level level] [--data-only] [--debug] [--exclude-schema schema_name] [--exclude-table schema.table] [--exclude-table-file file_name] [--include-schema schema_name] [--include-table schema.table] [--include-table-file file_name] [--incremental [--from-timestamp backup-timestamp]] [--jobs int] [--leaf-partition-data] [--metadata-only] [--no-compression] [--plugin-config config_file_location] [--quiet] [--single-data-file] [--verbose] [--version] [--with-stats] gpbackup --help |
描述
gpbackup工具用来备份数据库的内容到元数据文件集合和数据文件集合,这些文件可以被 gprestore工具用来恢复数据库。当备份数据库时,可以通过指定表级别和模式级别选项来 备份某些特定的表。例如,可以通过组合模式级别和表级别选项来备份模式下的所有表,并排除某一张单独的表。
默认情况下,gpbackup备份指定数据库的对象和Greenplum数据库系统全局对象。可以通过 gprestore工具指定可选参数--with-globals来恢复全局对象。更多 信息请见备份或还原中包含的对象 。
gpbackup默认将Greenplum数据库备份对象元数据文件和DDL文件存储在Master数据目录下。 Greenplum Segment使用COPY … ON SEGMENT命令将数据备份为压缩CSV数据文件,并 存储在每个Segment的数据目录下。更多信息请见理解备份文件。
可以通过指定--backup-dir选项将Master和Segment主机上的数据备份到一个绝对 路径下。可以通过指定其他选项来过滤备份集合来排除或包含指定的表。
可以通过指定 --incremental选项来启动增量备份。增量备份在追加优化表或 表分区上的变化数据小于未发生变化的数据时有效。有关增量备份的详细信息,请见使用gpbackup和gprestore创建增量备份。
指定--jobs选项(1 job),Greenplum数据库Master主机上的每个 gpbackup操作都会启动一个单独的事务。COPY … ON SEGMENT命令在每个Segment主机上并行执行备份任务。备份进程会在备份的每张表 上唤起ACCESS SHARE锁。在表锁处理过程中,数据库处于静止状态。
当备份操作完成后,gpbackup会返回状态码。详情请见 返回码。
gpexpand正在初始化新segments时,gpbackup工具不能 运行。集群扩展完成后,在扩展之前创建的备份不能被gprestore使用。
gpbackup可以在备份操作完成后发送Email状态通知。客户可以在配置文件中 创建工具发送和接收服务器信息。详情请见配置邮件通知。
Note: 该工具在系统内部采用SSH连接执行各项操作任务。在大型Greenplum集群、云部署或每台主机部署了大量的 segment实例时,可能会遇到超过主机最大授权连接数限制的情况。此时需要考虑更新SSH配置参数MaxStartups 以提高该限制。更多关于SSH配置的选项,请参考您的Linux分发版的SSH文档。
选项
--dbname database_name
必须。指定要备份的数据库。
--backup-dir directory
可选。复制所有备份文件(元数据文件和数据文件)到指定路径。必须指定directory 为绝对路径(不能是相对路径)。如果不提供该选项,元数据文件会保存在Greenplum Master主机的 $MASTER_DATA_DIRECTORY/backups/YYYYMMDD/YYYYMMDDhhmmss/ 路径下。Segment主机的CSV数据文件保存在/backups/YYYYMMDD/YYYYMMDDhhmmss/ 路径下。当指定该选项时,文件会被复制到备份目录的子路径下。
该选项不能和--plugin-config一起使用。
--compression-level level
可选。指定用来压缩数据文件的gzip压缩级别(从1到9)。默认为1。注意,gpbackup 默认使用压缩。
--data-only
可选。仅将表数据备份到CSV文件,不备份用来重建表和其他数据库对象的元数据文件。
--debug
可选。显示操作期间的调试信息。
--exclude-schema schema_name
可选。指定要被排除备份的模式名。该参数可以指定多次以排除多个模式。该选项不能与 --include-schema一起使用,也不能与表过滤选项例如: --include-table一起使用。更多信息请见过滤备份或恢复的内容。
--exclude-table schema.table
可选。指定要排除在备份中的表。被排除的表必须为格式. 。如果表或模式名使用了任何非小写字母、数字或下划线,必须用双引号包裹名字。该选项可以指定多次。 该选项不能与--exclude-schema或--include-table同时使用。
该选项不能和--leaf-partition-data组合使用。虽然您可以指定子分区名字,但是 gpbackup会忽略分区名称。
更多信息详见过滤备份或恢复的内容 。
--exclude-table-file file_name
可选。指定一个包含需要排除在备份之外的列表文件。每行必须指定一个单独的表,格式为 .。文件不能包含多余的行。 如果表或模式名使用了任何非小写字母、数字或下划线,必须用双引号包裹名字。该选项可以指定多次。 该选项不能与--exclude-schema或--include-table同时使用。
该选项不能和--leaf-partition-data组合使用。虽然您可以在--exclude-table-file 中指定子分区名字,但是gpbackup会忽略分区名称。
更多信息请见过滤备份或恢复的内容 。
--include-schema schema_name
可选。指定要包含在备份中的数据库模式名。可以多次指定该参数来包含多个备份模式。如果指定该选项, 任何不包含在--include-schema中的模式都不会放在备份集中。该选项不能与选项 --exclude-schema、--include-table或 --include-table-file一起使用。更多详情请见过滤备份或恢复的内容。
--include-table schema.table
可选。指定一个要包含在备份中的表。该表的格式必须为.。 如果表或模式名使用了任何非小写字母、数字或下划线,必须用双引号包裹名字。有关模式和表名中支持的 字符信息详情,请见模式和表名中的模式和表名部分。
该选项可以指定多次。该选项不能和模式筛选选项--include-schema或--exclude-table-file等 一起使用。
客户也可以指定序列或视图的名字。
如果指定该选项,该工具不会自动备份依赖对象。客户必须指定相关依赖对象。例如,如果备份了视图, 客户必须备份试图所用的表。如果备份表用到了一个序列,客户必须也备份相关的序列。
可以在表名处通过指定--leaf-partition-data选项来指定表子分区名字, 仅备份指定的分区。当指定子分区备份时,子分区数据和分区表的元数据信息都会被备份。
更多信息请见过滤备份或恢复的内容 。
--include-table-file file_name
可选。指定一个备份时需要的表名列表文件。文件中的每行必须定义为单独的表名,格式为: .。该文件不能包含多余的列。 有关模式和表名中支持的 字符信息详情,请见模式和表名中的模式和表名部分。
任何没有列在文件中的表都会被排除在备份集以外。该选项不能与模式过滤选项--include-schema 或--exclude-table-file等一起使用。
该选项也可以指定序列和视图名称。
如果指定该选项,该工具不会自动备份依赖对象。客户必须指定相关依赖对象。例如,如果备份了视图, 客户必须备份试图所用的表。如果备份表用到了一个序列,客户必须也备份相关的序列。
可以在表名处通过指定--leaf-partition-data选项来指定表子分区名字, 仅备份指定的分区。当指定子分区备份时,子分区数据和分区表的元数据信息都会被备份。
更多信息请见过滤备份或恢复的内容 。
--incremental
指定该选项可以增加一个增量备份到增量备份集中。一个备份集包括一个全量备份和一个或多个增量备份。 该备份集合必须是连续性的,以保证在恢复时是可用的。
默认情况下,gpbackup会找出最近的备份。如果该备份是全备份,工具会创建一个 备份集合。如果备份为增量备份,工具会将备份增加到已经存在的备份集。增量备份被增加到备份集的最后 。可以通过指定--from-timestamp来覆盖默认的行为。
--from-timestamp backup-timestamp
可选。指定备份时间戳。指定的备份必须已经有增量备份存在。如果指定的备份只有全量备份,该工具 会创建一个备份集。如果指定的备份是增量备份,工具会将增量备份直接备份到该备份集合。
本人提供Oracle(OCP、OCM)、MySQL(OCP)、PostgreSQL(PGCA、PGCE、PGCM)等数据库的培训和考证业务,私聊QQ646634621或微信dbaup66,谢谢!