合 Oracle中的统计信息介绍
简介
Oracle数据库里的统计信息是一组存储在数据字典里,且从多个维度描述了数据库里对象的详细信息的一组数据。当Oracle数据库工作在CBO(Cost Based Optimization,基于代价的优化器)模式下时,优化器会根据数据字典中记录的对象的统计信息来评估SQL语句的不同执行计划的成本,从而找到最优或者是相对最优的执行计划。所以,可以说,SQL语句的执行计划由统计信息来决定,若没有统计信息则会采取动态采样的方式来生成执行计划。统计信息决定着SQL的执行计划的正确性,属于SQL执行的指导思想。若统计信息不准确,则会导致表的访问方式(例如应该使用索引,但是选择了全表扫描)、表与表的连接方式出现问题(例如应该使用HJ,但是使用了NL连接),从而导致CBO选择错误的执行计划。
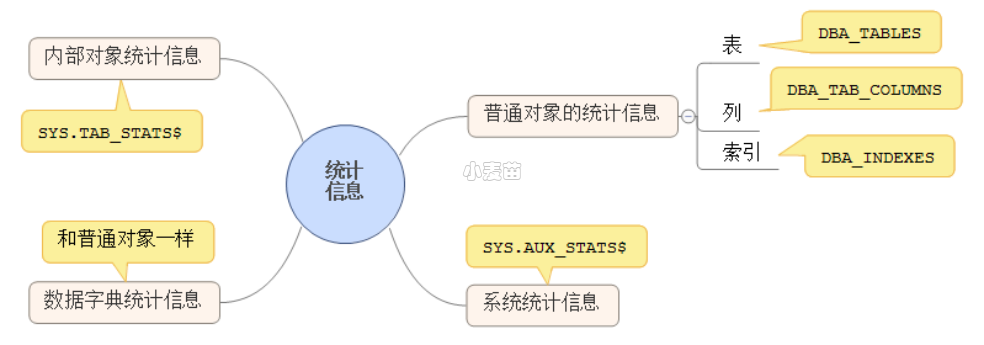
统计信息主要包括6种类型,其中表、列和索引的统计信息也可以统称为普通对象的统计信息,如下所示:
查询表统计信息的SQL如下所示:
1 2 3 4 5 6 7 8 9 10 | SELECT D.NUM_ROWS, --表中的记录数 D.BLOCKS, --表中数据所占的数据块数 D.EMPTY_BLOCKS, --表中的空块数 D.AVG_SPACE, --数据块中平均的使用空间 D.CHAIN_CNT, --表中行连接和行迁移的数量 D.AVG_ROW_LEN, --每条记录的平均长度 D.STALE_STATS, --统计信息是否过期 D.LAST_ANALYZED --最近一次搜集统计信息的时间 FROM DBA_TAB_STATISTICS D --DBA_TAB_STATISTICS DBA_TABLES WHERE D.TABLE_NAME = 'CUSTOMERS'; |
查询表上列的统计信息的SQL如下所示:
1 2 3 4 5 6 7 8 9 10 | SELECT D.COLUMN_NAME, D.NUM_DISTINCT, --唯一值的个数 D.LOW_VALUE, --列上的最小值 D.HIGH_VALUE, --列上的最大值 D.DENSITY, --若不存在柱状图的话,则表示选择率因子(密度)=1/(NDV) D.NUM_NULLS, --空值的个数 D.NUM_BUCKETS, --直方图的BUCKETS个数 D.HISTOGRAM --直方图的类型 FROM DBA_TAB_COLUMNS D --DBA_TAB_COL_STATISTICS WHERE TABLE_NAME = 'CUSTOMERS'; |

索引统计信息
BLEVEL存储的就是目标索引的层级,它表示的是从根节点到叶子块的深度,BLEVEL被CBO用于计算访问索引叶子块的成本。BLEVEL的值越大,则从根节点到叶子块所需要访问的数据块的数量就会越多,耗费的I/O就会越多,访问索引的成本就会越大。BLEVEL的值从0开始算起,当BLEVEL的值为0时,表示该B树索引只有一层,且根节点和叶子块就是同一个块。在Oracle数据库里,如果要降低目标B树索引的层级,那么只能通过REBUILD该索引的方式来实现。
列的统计信息
列的统计信息用于描述Oracle数据库里列的详细信息,包含了列的DISTINCT值的数量、列的NULL值的数量、列的最小值、列的最大值等一些典型维度。这些列统计信息实际上是存储在数据字典基表SYS.HIST_HEAD$中,可以通过数据字典DBA_TAB_COL_STATISTICS、DBA_PART_COL_STATISTICS和DBA_SUBPART_COL_STATISTICS来分别查看表、分区表的分区和分区表的子分区的列统计信息。在这些数据字典中的字段NUM_DISTINCT存储的就是目标列的DISTINCT值的数量。CBO用NUM_DISTINCT的值来评估用目标列做等值查询的可选择率(Selectivity)。CBO会用NUM_NULLS的值来调整对有NULL值的目标列做等值查询的可选择率。
数据字典中的字段DENSITY和NUM_BUCKETS分别存储的是目标列的密度和所用桶的数量,这两个维度仅和直方图有关。在没有直方图统计信息时,DENSITY的值就等于I/NUM_DISTINCT;在有频率直方图的时,DENSITY的值就等于1/(2*(NUM_ROWS-NUM_NULLS))。示例如下:
1 2 3 | CREATE TABLE T_MD_20170606_LHR AS SELECT ROWNUM ID,ROWNUM SAL FROM DUAL CONNECT BY LEVEL<=10000; UPDATE T_MD_20170606_LHR SET SAL=5000 WHERE SAL BETWEEN 6 AND 9995; --9990 UPDATE T_MD_20170606_LHR SET SAL='' WHERE SAL BETWEEN 2 AND 3; --2 |
在无直方图的情况下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | LHR@orclasm > EXEC DBMS_STATS.GATHER_TABLE_STATS(USER,'T_MD_20170606_LHR',CASCADE=>TRUE,METHOD_OPT=>'FOR ALL COLUMNS SIZE 1'); PL/SQL procedure successfully completed. LHR@orclasm > SET LINESIZE 120 LHR@orclasm > SELECT D.COLUMN_NAME,D.NUM_DISTINCT,D.NUM_NULLS,D.NUM_BUCKETS,D.HISTOGRAM,D.DENSITY FROM DBA_TAB_COLUMNS D WHERE D.TABLE_NAME = 'T_MD_20170606_LHR'; COLUMN_NAME NUM_DISTINCT NUM_NULLS NUM_BUCKETS HISTOGRAM DENSITY ------------------------------ ------------ ---------- ----------- --------------- ---------- SAL 9 2 1 NONE .111111111 ID 10000 0 1 NONE .0001 LHR@orclasm > SELECT 1/9,1/10000 FROM DUAL; 1/9 1/10000 ---------- ---------- .111111111 .0001 在有直方图的情况下: LHR@orclasm > EXEC DBMS_STATS.GATHER_TABLE_STATS(USER,'T_MD_20170606_LHR',CASCADE=>TRUE,METHOD_OPT=>'FOR COLUMNS SAL SIZE 9'); PL/SQL procedure successfully completed. LHR@orclasm > SELECT D.COLUMN_NAME,D.NUM_DISTINCT,D.NUM_NULLS,D.NUM_BUCKETS,D.HISTOGRAM,D.DENSITY FROM DBA_TAB_COLUMNS D WHERE D.TABLE_NAME = 'T_MD_20170606_LHR'; COLUMN_NAME NUM_DISTINCT NUM_NULLS NUM_BUCKETS HISTOGRAM DENSITY ------------------------------ ------------ ---------- ----------- --------------- ---------- SAL 9 2 9 FREQUENCY .00005001 ID 10000 0 1 NONE .0001 LHR@orclasm > SELECT 1/(2*(10000-2)) FROM DUAL; 1/(2*(10000-2)) --------------- .00005001 |
数据字典中的字段LOW_VALUE和HIGH_VALUE分别存储的就是目标列的最小值和最大值,CBO用LOW_VALUE和HIGH_VALUE来评估对目标列做范围查询时的可选择率。不过这两个字段的返回值是RAW类型的,需要转换后才能识别。可以使用UTL_RAW.CAST_TO_NUMBER、UTL_RAW.CAST_TO_VARCHAR2等函数来转换,也可以使用存储过程DBMS_STATS.CONVERT_RAW_VALUE来转换,下面给出示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | CREATE OR REPLACE FUNCTION FUN_DISPLAY_RAW_LHR(P_RAWVAL RAW,P_TYPE VARCHAR2) RETURN VARCHAR2 IS V_NUMBER NUMBER; V_VARCHAR2 VARCHAR2(32); V_DATE DATE; V_NVARCHAR2 NVARCHAR2(32); V_ROWID ROWID; V_CHAR CHAR(32); BEGIN IF (P_TYPE = 'NUMBER' OR P_TYPE = 'FLOAT') THEN DBMS_STATS.CONVERT_RAW_VALUE(P_RAWVAL, V_NUMBER); RETURN TO_CHAR(V_NUMBER); ELSIF (P_TYPE = 'VARCHAR2') THEN DBMS_STATS.CONVERT_RAW_VALUE(P_RAWVAL, V_VARCHAR2); RETURN TO_CHAR(V_VARCHAR2); ELSIF (P_TYPE = 'DATE' OR P_TYPE LIKE 'TIMESTAMP%') THEN DBMS_STATS.CONVERT_RAW_VALUE(P_RAWVAL, V_DATE); RETURN TO_CHAR(V_DATE); ELSIF (P_TYPE = 'NVARCHAR2') THEN DBMS_STATS.CONVERT_RAW_VALUE(P_RAWVAL, V_NVARCHAR2); RETURN TO_CHAR(V_NVARCHAR2); ELSIF (P_TYPE = 'ROWID') THEN DBMS_STATS.CONVERT_RAW_VALUE(P_RAWVAL, V_ROWID); RETURN TO_CHAR(V_ROWID); ELSIF (P_TYPE = 'CHAR') THEN DBMS_STATS.CONVERT_RAW_VALUE(P_RAWVAL, V_CHAR); RETURN TO_CHAR(V_CHAR); ELSIF (P_TYPE = 'RAW') THEN RETURN TO_CHAR(P_RAWVAL); ELSE RETURN 'UNKNOWN DATATYPE!'; END IF; EXCEPTION WHEN OTHERS THEN RETURN 'ERRORS!'; END FUN_DISPLAY_RAW_LHR; -- 使用该函数查询: CREATE TABLE T_AA_20170606_LHR AS SELECT * FROM DBA_OBJECTS; EXEC DBMS_STATS.gather_table_stats(USER,'T_AA_20170606_LHR'); SELECT D.COLUMN_NAME, D.LOW_VALUE, D.HIGH_VALUE, D.DENSITY, D.NUM_DISTINCT, D.NUM_NULLS, D.NUM_BUCKETS, D.HISTOGRAM, D.DATA_TYPE, FUN_DISPLAY_RAW_LHR(D.LOW_VALUE, D.DATA_TYPE) LOW_VALUE1, FUN_DISPLAY_RAW_LHR(D.HIGH_VALUE, D.DATA_TYPE) HIGH_VALUE1--, --UTL_RAW.CAST_TO_NUMBER(D.LOW_VALUE) LOW_VALUE2, --UTL_RAW.CAST_TO_NUMBER(D.HIGH_VALUE) HIGH_VALUE2, FROM USER_TAB_COLS D WHERE D.TABLE_NAME = 'T_AA_20170606_LHR'; |

系统统计信息
系统统计信息主要包括目标数据库服务器CPU的主频、单块读的平均耗费时间、多块读的平均耗费时间和单次多块读所能读取的数据块的平均值等。收集系统统计信息的方法主要是使用系统存储过程:
1 2 3 4 5 6 7 8 9 | EXEC DBMS_STATS.GATHER_SYSTEM_STATS('start'); -- 系统正常负载运行一段时间 EXEC DBMS_STATS.GATHER_SYSTEM_STATS('stop'); -- 或: EXEC DBMS_STATS.GATHER_SYSTEM_STATS(GATHERING_MODE => 'INTERVAL',INTERVAL =>1);--INTERVAL为间隔时长,单位为分钟 |
系统统计信息主要存储在SYS.AUX_STATS$表中,也可以使用DBMS_STATS.GET_SYSTEM_STATS获取系统统计信息的内容,修改系统统计信息可以使用DBMS_STATS.SET_SYSTEM_STATS,删除系统统计信息可以使用DBMS_STATS.DELETE_SYSTEM_STATS。
在未引入系统统计信息之前,CBO所计算的成本值全部是基于I/O来计算的;在Oracle引入了系统统计信息之后,实际上就额外地引入了CPU成本计算模型(CPU Cost model),从此以后,CBO所计算的成本值就包括I/O Cost和CPU Cost这两个部分。CBO在计算成本的时候就会分别对它们各自计算,并将算出来的I/O Cost和CPU Cost值的总和作为目标SQL新的成本值。