合 MSSQL中创建索引、在线创建索引、索引并行、创建索引内存分配
Tags: MSSQLSQL Server整理自网络整理自官网索引并行内存MAXDOPonline在线
- 索引基本操作
- 查看某个表/视图中存在的索引
- 创建索引
- 删除索引
- 示例
- 索引并行
- 限制和局限
- 错误解决
- 创建索引占用内存设置
- 联机执行索引操作
- 限制和局限
- 安全性
- 权限
- 使用 SQL Server Management Studio
- 联机重新生成索引
- 联机创建、重新生成或删除索引
- CREATE INDEX (Transact-SQL)
- 语法
- 适用于 SQL Server、Azure SQL 数据库和 Azure SQL 托管实例的语法
- 后向兼容的关系索引
- Azure Synapse Analytics 和并行数据仓库的语法
- 自变量
- UNIQUE
- CLUSTERED
- NONCLUSTERED
- index_name
- column
- [ ASC | DESC ]
- INCLUDE (column [ ,... n ] )
- WHERE
- ON partition_scheme_name ( column_name )
- ON filegroup_name
- ON "default"
- [ FILESTREAM_ON { filestream_filegroup_name | partition_scheme_name | "NULL" } ]
- ::=
- database_name
- schema_name
- table_or_view_name
- ::=
- PAD_INDEX = { ON | OFF }
- FILLFACTOR = fillfactor
- SORT_IN_TEMPDB = { ON | OFF }
- IGNORE_DUP_KEY = { ON | OFF }
- STATISTICS_NORECOMPUTE = { ON | OFF}
- STATISTICS_INCREMENTAL = { ON | OFF }
- DROP_EXISTING = { ON | OFF }
- ONLINE = { ON | OFF }
- RESUMABLE = { ON | OFF }
- 将 MAX_DURATION = time [MINUTES] 与 RESUMABLE = ON 一起使用(要求 ONLINE = ON)
- ALLOW_ROW_LOCKS = { ON | OFF }
- ALLOW_PAGE_LOCKS = { ON | OFF }
- OPTIMIZE_FOR_SEQUENTIAL_KEY = { ON | OFF }
- MAXDOP = max_degree_of_parallelism
- DATA_COMPRESSION
- XML_COMPRESSION
- ON PARTITIONS ( { | } [ ,...n ] )
- 备注
- 聚集索引
- “非聚集索引”
- 唯一索引
- 已分区索引
- 筛选索引
- 筛选索引所需的 SET 选项
- 空间索引
- XML 索引
- 索引键大小
- 计算列
- 索引中的包含列
- 指定索引选项
- DROP_EXISTING 子句
- ONLINE 选项
- 资源
- 当前功能限制
- 可恢复索引操作
- 具有联机索引操作的 WAIT_AT_LOW_PRIORITY
- 行锁和页锁选项
- 顺序键
- 查看索引信息
- 数据压缩
- XML 压缩
- 权限
- 限制和局限
- 元数据
- 版本说明
- 示例:所有版本。 使用 AdventureWorks 数据库
- A. 创建简单的非聚集行存储索引
- B. 创建简单的非聚集行存储组合索引
- C. 为其他数据库中的表创建索引
- D. 将列添加到索引
- 示例:SQL Server、Azure SQL 数据库
- E. 创建唯一非聚集索引
- F. 使用 IGNORE_DUP_KEY 选项
- G. 使用 DROP_EXISTING 删除和重新创建索引
- H. 为视图创建索引
- I. 创建具有包含列(非键列)的索引
- J. 创建已分区索引
- K. 创建筛选索引
- L. 创建压缩索引
- M. 使用 XML 压缩创建索引
- N. 创建、恢复、暂停和中止可恢复索引操作
- O. 具有不同低优先级锁选项的 CREATE INDEX
- 示例:Azure Synapse Analytics 和 Analytics Platform System (PDW)
- P. 基本语法
- Q. 为当前数据库中的表创建非聚集索引
- R. 为其他数据库中的表创建聚集索引
- S. 在表上创建有序的聚集索引
- T. 在表上将 CCI 转换为有序的聚集索引
- SQL使用总结
- 参考
索引基本操作
查看某个表/视图中存在的索引
1、语法:
exec sp_helpindex 表名/视图名
2、返回代码值:0(成功)或 1(失败)
3、结果值:
列名称 数据类型 说明
index_name sysname 索引名。
index_description varchar (210) 索引说明,其中包括索引所在的文件组。
index_keys nvarchar (2078) 对其生成索引的表或视图列。
创建索引
语法:
CREATE [索引类型] INDEX 索引名称
ON 表名(列名)
创建索引实例:
聚簇索引
create clustered index index_name on table_name (cloumn_name);
非聚簇索引
create nonclustered index index_name on table_name (cloumn_name);
唯一索引
create unique index index_name on table_name(cloumn_name);
删除索引
可利用ALTER TABLE或DROP INDEX语句来删除索引。类似于CREATE INDEX语句,DROP INDEX可以在ALTER TABLE内部作为一条语句处理,语法如下。
DROP INDEX index_name ON talbe_name
ALTER TABLE table_name DROP INDEX index_name
ALTER TABLE table_name DROP PRIMARY KEY
其中,前两条语句是等价的,删除掉table_name中的索引index_name。
第3条语句只在删除PRIMARY KEY索引时使用,因为一个表只可能有一个PRIMARY KEY索引,因此不需要指定索引名。如果没有创建PRIMARY KEY索引,但表具有一个或多个UNIQUE索引,则MySQL将删除第一个UNIQUE索引。
示例
1 2 3 4 5 | exec sp_helpindex Fly_ERP_Materia_old --查看索引 create nonclustered index Coding on Fly_ERP_Materia_old (Coding) --创建索引 DROP INDEX Specifications_copy1 ON Fly_ERP_Materia_old --删除索引 |
索引并行
在运行 SQL Server Enterprise 或更高版本的多处理器系统上,索引语句可能会像其他查询那样,使用多个处理器 (CPU) 来执行与索引语句关联的扫描、排序和索引操作。 用于运行单个索引语句的 CPU 数由最大并行度服务器配置选项、当前工作负荷以及索引统计信息决定。 max degree of parallelism (MAXDOP)选项决定了执行并行计划时使用的最大处理器数。 如果 SQL Server 数据库引擎 检测到系统忙,索引操作的并行度将自动降低,然后再开始执行语句。 如果非分区索引的第一个键列包含有限数量的非重复值,或者每个非重复值的出现频率变化较大, 数据库引擎 也可能会降低并行度。
限制和局限
查询优化器使用的处理器数量通常能够提供最佳的性能。 但是,有些操作(如创建、重新生成或删除很大的索引)占用大量资源,在索引操作期间会造成没有足够的资源供其他应用程序和数据库操作使用。 出现此问题时,您可以通过限制用于索引操作的处理器数,手动配置用于运行索引语句的最大处理器数。
MAXDOP 索引选项只为指定此选项的查询覆盖 max degree of parallelism 配置选项。 下表列出了可为 max degree of parallelism 配置选项和 MAXDOP 索引选项指定的有效整数值。
值 说明 0 指定服务器根据当前系统工作负荷确定所使用的 CPU 数目。 这是默认值,还是推荐设置。 1 取消生成并行计划。 操作将以串行方式执行。 2-64 将处理器的数量限制为指定的值。 根据当前工作负荷,可能使用较少的处理器。 如果指定的值大于可用的 CPU 数量,将使用实际可用的 CPU 数量。 并行索引执行和 MAXDOP 索引选项适用于以下 Transact-SQL 语句:
不能在
ALTER INDEX (...) REORGANIZE语句中指定 MAXDOP 索引选项。如果查询优化器将并行度应用于生成操作,则需要排序的已分区索引操作的内存需求可能会很大。 并行度越高,内存需求就越大。 有关详细信息,请参阅 Partitioned Tables and Indexes。
错误解决
当你创建索引时,你可能会遇到如下错误:

消息 8606,级别 17,状态 1,第 7 行
此索引操作要求每个 DOP 有 8192 KB 的内存。16 的 DOP 总共要求 131336 KB 的内存,这大于为高级服务器配置选项 "index create memory (KB)" 设置的 sp_configure 值 1024 KB。请增大此设置的值或减少 DOP,然后重新运行该查询。
这个错误是什么意思呢,我们如何解决这个错误?
一旦你遇到上面的错误,你首先想到的是设置“index create memory(KB)”或者设置dop值来解决问题。但是在哪里设置这些值,并且当你做了这些调整后,会发生什么呢。在我们做任何改变之前,让我们先理解这些服务级别的设置,进而避免影响SQL Server实例上任何其他操作,因为这个改变是实例级别的改变。
创建索引占用内存设置
设置为0时,SQL Server动态分配内存,指定其他值时,为创建索引允许使用的最大内存,默认为0,表示动态分配内存。
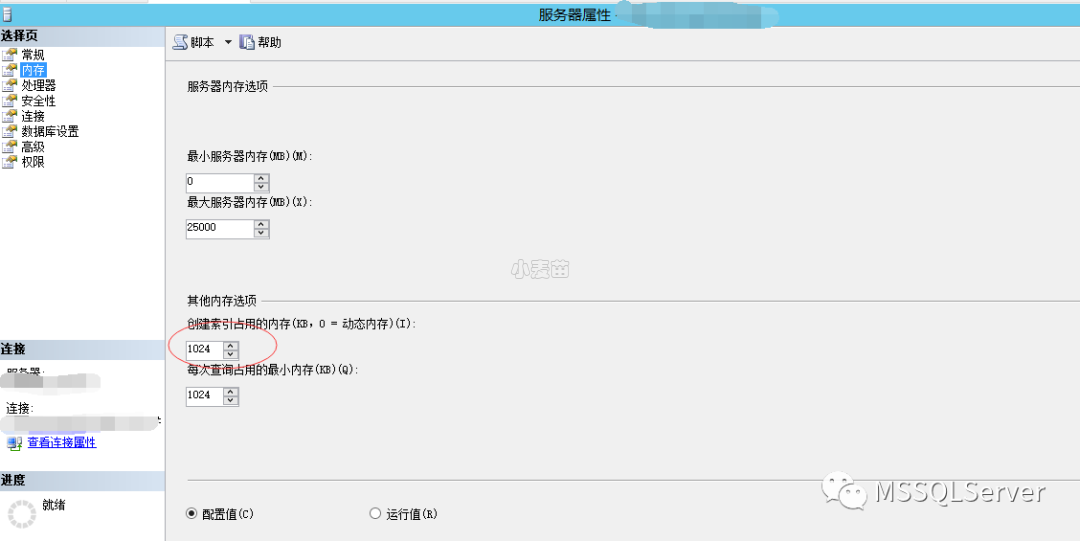
除图形化界面设置外,我们可以使用如下脚本设置
1 2 3 4 5 6 7 8 9 | EXEC sp_configure 'show advanced options', 1; GO RECONFIGURE; GO EXEC sys.sp_configure N'index create memory (KB)', N'1024' GO RECONFIGURE WITH OVERRIDE GO |
最佳实践是不改变“index create memory(KB)”默认值0,因为SQL Server默认的会动态分配索引创建需要的内存。如果创建索引需要额外的内存,可用内存取决于服务的内存配置,创建索引将使用已经分配的内存进行索引创建。
创建索引的maxdop值不超过服务器的逻辑处理器个数的一半,防止影响其他业务正常运行。
联机执行索引操作
本主题说明如何使用 SQL Server Management Studio 或 Transact-SQL 在 SQL Server 中在线创建、重新生成或删除索引。 ONLINE 选项允许并发用户在执行这些索引操作期间访问基础表或聚集索引数据和任何关联非聚集索引。 例如,一个用户正在重新生成聚集索引时,该用户和其他用户可以继续更新和查询基础数据。 当脱机执行数据定义语言 (DDL) 操作(例如,生成或重新生成聚集索引)时,这些操作对基础数据和关联索引持有排他锁。 这样可以防止在索引操作未完成时对基础数据进行修改和查询。
备注
在 SQL Server 的各版本中均不提供联机索引操作。 有关详细信息,请参阅 SQL Server 2022 的版本及其支持的功能。
联机索引操作可用于 Azure SQL 数据库和 Azure SQL 托管实例。
限制和局限
- 建议对于全天候运行的业务环境执行联机索引操作,在这些环境中,在执行索引操作期间必须有并发用户活动。
- 以下 Transact-SQL 语句中可以使用 ONLINE 选项。
- CREATE INDEX
- ALTER INDEX
- DROP INDEX
- ALTER TABLE (使用 CLUSTERED 索引选项添加或删除 UNIQUE 约束或 PRIMARY KEY 约束)
- 有关联机创建、重新生成或删除索引的更多限制和局限性,请参阅 联机索引操作指南。
安全性
权限
要求对表或视图具有 ALTER 权限。
使用 SQL Server Management Studio
联机重新生成索引
- 在“对象资源管理器”中,单击加号以便展开包含您要联机重新生成索引的表的数据库。
- 展开 “表” 文件夹。
- 单击加号以展开您要联机重新生成索引的表。
- 展开 “索引” 文件夹。
- 右键单击要联机重新生成的索引,然后选择“属性”。
- 在 “选择页”下,选择 “选项”。
- 选择 “允许联机 DML 处理”,然后从列表中选择 True 。
- 单击“确定”。
- 右键单击要联机重新生成的索引,然后选择“重新生成”。
- 在 “重新生成索引” 对话框中,确认正确的索引位于 “要重新生成的索引” 网格中,然后单击 “确定”。
联机创建、重新生成或删除索引
下面的示例在 AdventureWorks 数据库中重新生成现有联机索引。
SQL
1 2 3 | ALTER INDEX AK_Employee_NationalIDNumber ON HumanResources.Employee REBUILD WITH (ONLINE = ON); |
以下示例使用 NewGroup 子句联机删除一个聚集索引并将生成表(堆)移动到文件组 MOVE TO 。 在移动之前和之后,将查询 sys.indexes、 sys.tables和 sys.filegroups 目录视图,以验证索引和表在文件组中的位置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | -- Create a clustered index on the PRIMARY filegroup if the index does not exist. IF NOT EXISTS (SELECT name FROM sys.indexes WHERE name = N'AK_BillOfMaterials_ProductAssemblyID_ComponentID_StartDate') CREATE UNIQUE CLUSTERED INDEX AK_BillOfMaterials_ProductAssemblyID_ComponentID_StartDate ON Production.BillOfMaterials (ProductAssemblyID, ComponentID, StartDate) ON 'PRIMARY'; GO -- Verify filegroup location of the clustered index. SELECT t.name AS [Table Name], i.name AS [Index Name], i.type_desc, i.data_space_id, f.name AS [Filegroup Name] FROM sys.indexes AS i JOIN sys.filegroups AS f ON i.data_space_id = f.data_space_id JOIN sys.tables as t ON i.object_id = t.object_id AND i.object_id = OBJECT_ID(N'Production.BillOfMaterials','U') GO -- Create filegroup NewGroup if it does not exist. IF NOT EXISTS (SELECT name FROM sys.filegroups WHERE name = N'NewGroup') BEGIN ALTER DATABASE AdventureWorks2022 ADD FILEGROUP NewGroup; ALTER DATABASE AdventureWorks2022 ADD FILE (NAME = File1, FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\File1.ndf') TO FILEGROUP NewGroup; END GO -- Verify new filegroup SELECT * from sys.filegroups; GO -- Drop the clustered index and move the BillOfMaterials table to -- the Newgroup filegroup. -- Set ONLINE = OFF to execute this example on editions other than Enterprise Edition. DROP INDEX AK_BillOfMaterials_ProductAssemblyID_ComponentID_StartDate ON Production.BillOfMaterials WITH (ONLINE = ON, MOVE TO NewGroup); GO -- Verify filegroup location of the moved table. SELECT t.name AS [Table Name], i.name AS [Index Name], i.type_desc, i.data_space_id, f.name AS [Filegroup Name] FROM sys.indexes AS i JOIN sys.filegroups AS f ON i.data_space_id = f.data_space_id JOIN sys.tables as t ON i.object_id = t.object_id AND i.object_id = OBJECT_ID(N'Production.BillOfMaterials','U'); |
有关详细信息,请参阅 ALTER INDEX (Transact-SQL)。
CREATE INDEX (Transact-SQL)
为表或视图创建相关索引。 也称为行存储索引,因为它可能是聚集或非聚集的 B 树索引。 可以在表中不存在数据时创建行存储索引。 使用行存储索引提高查询性能,尤其是在查询从特定列中进行选择或需要按特定顺序对值进行排序时。
备注
SQL Server 文档在提到索引时一般使用 B 树这个术语。 在行存储索引中,SQL Server 实现了 B+ 树。 这不适用于列存储索引或内存中数据存储。 有关详细信息,请参阅 SQL Server 以及 Azure SQL 索引体系结构和设计指南。
Azure Synapse Analytics 和 Analytics Platform System (PDW) 目前不支持唯一约束。 任何引用唯一约束的示例仅适用于 SQL Server 和 SQL 数据库。
有关索引设计指南的信息,请参阅 SQL Server 索引设计指南。
示例:
对表或视图创建非聚集索引
SQL
1CREATE INDEX index1 ON schema1.table1 (column1);在表上创建聚集索引,并为表使用由 3 个部分组成的名称
SQL
1CREATE CLUSTERED INDEX index1 ON database1.schema1.table1 (column1);使用唯一约束创建非聚集索引并指定排序顺序
SQL
1CREATE UNIQUE INDEX index1 ON schema1.table1 (column1 DESC, column2 ASC, column3 DESC);
主要方案:
从 SQL Server 2016 (13.x) 和 SQL 数据库开始,可针对列存储索引使用非聚集索引来提高数据仓库查询性能。 有关详细信息,请参阅列存储索引 - 数据仓库。
有关其他类型的索引,请参阅:
语法
适用于 SQL Server、Azure SQL 数据库和 Azure SQL 托管实例的语法
syntaxsql
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON <object> ( column [ ASC | DESC ] [ ,...n ] ) [ INCLUDE ( column_name [ ,...n ] ) ] [ WHERE <filter_predicate> ] [ WITH ( <relational_index_option> [ ,...n ] ) ] [ ON { partition_scheme_name ( column_name ) | filegroup_name | default } ] [ FILESTREAM_ON { filestream_filegroup_name | partition_scheme_name | "NULL" } ] [ ; ] <object> ::= { database_name.schema_name.table_or_view_name | schema_name.table_or_view_name | table_or_view_name } <relational_index_option> ::= { PAD_INDEX = { ON | OFF } | FILLFACTOR = fillfactor | SORT_IN_TEMPDB = { ON | OFF } | IGNORE_DUP_KEY = { ON | OFF } | STATISTICS_NORECOMPUTE = { ON | OFF } | STATISTICS_INCREMENTAL = { ON | OFF } | DROP_EXISTING = { ON | OFF } | ONLINE = { ON [ ( <low_priority_lock_wait> ) ] | OFF } | RESUMABLE = { ON | OFF } | MAX_DURATION = <time> [MINUTES] | ALLOW_ROW_LOCKS = { ON | OFF } | ALLOW_PAGE_LOCKS = { ON | OFF } | OPTIMIZE_FOR_SEQUENTIAL_KEY = { ON | OFF } | MAXDOP = max_degree_of_parallelism | DATA_COMPRESSION = { NONE | ROW | PAGE } [ ON PARTITIONS ( { <partition_number_expression> | <range> } [ , ...n ] ) ] | XML_COMPRESSION = { ON | OFF } [ ON PARTITIONS ( { <partition_number_expression> | <range> } [ , ...n ] ) ] } <filter_predicate> ::= <conjunct> [ AND ] [ ...n ] <conjunct> ::= <disjunct> | <comparison> <disjunct> ::= column_name IN (constant ,...n) <comparison> ::= column_name <comparison_op> constant <comparison_op> ::= { IS | IS NOT | = | <> | != | > | >= | !> | < | <= | !< } <low_priority_lock_wait>::= { WAIT_AT_LOW_PRIORITY ( MAX_DURATION = <time> [ MINUTES ] , ABORT_AFTER_WAIT = { NONE | SELF | BLOCKERS } ) } <range> ::= <partition_number_expression> TO <partition_number_expression> |
后向兼容的关系索引
重要
在 SQL Server 的未来版本中,将删除此后向兼容的关系索引语法结构。 请避免在新的开发工作中使用此语法结构,并计划修改当前使用此功能的应用程序。 改用
syntaxsql
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON <object> ( column_name [ ASC | DESC ] [ ,...n ] ) [ WITH <backward_compatible_index_option> [ ,...n ] ] [ ON { filegroup_name | "default" } ] <object> ::= { [ database_name. [ owner_name ] . | owner_name. ] table_or_view_name } <backward_compatible_index_option> ::= { PAD_INDEX | FILLFACTOR = fillfactor | SORT_IN_TEMPDB | IGNORE_DUP_KEY | STATISTICS_NORECOMPUTE | DROP_EXISTING } |
Azure Synapse Analytics 和并行数据仓库的语法
syntaxsql
1 2 3 4 5 6 7 8 9 10 11 | CREATE CLUSTERED COLUMNSTORE INDEX index_name ON [ database_name . [ schema ] . | schema . ] table_name [ORDER (column[,...n])] [WITH ( DROP_EXISTING = { ON | OFF } )] [;] CREATE [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON [ database_name . [ schema ] . | schema . ] table_name ( { column [ ASC | DESC ] } [ ,...n ] ) WITH ( DROP_EXISTING = { ON | OFF } ) [;] |
备注
若要查看 SQL Server 2014 (12.x) 及更早版本的 Transact-SQL 语法,请参阅早期版本文档。
自变量
UNIQUE
为表或视图创建唯一索引。 唯一索引不允许两行具有相同的索引键值。 视图的聚集索引必须唯一。
无论 IGNORE_DUP_KEY 是否设置为 ON,数据库引擎都不允许为已包含重复值的列创建唯一索引。 否则,数据库引擎会显示错误消息。 必须先删除重复值,然后才能为一列或多列创建唯一索引。 唯一索引中使用的列应设置为 NOT NULL,因为在创建唯一索引时,会将多个 Null 值视为重复值。
CLUSTERED
创建索引时,键值的逻辑顺序决定表中对应行的物理顺序。 聚集索引的底层(或称叶级别)包含该表的实际数据行。 一个表或视图只允许同时有一个聚集索引。
具有唯一聚集索引的视图称为索引视图。 为一个视图创建唯一聚集索引会在物理上具体化该视图。 必须先为视图创建唯一聚集索引,然后才能为该视图定义其他索引。 有关详细信息,请参阅 创建索引视图。
在创建任何非聚集索引之前创建聚集索引。 创建聚集索引时会重新生成表中现有的非聚集索引。
如果没有指定 CLUSTERED,则创建非聚集索引。
备注
因为按照定义,聚集索引的叶级别与其数据页相同,所以创建聚集索引和使用 ON partition_scheme_name 或 ON filegroup_name 子句实际上会将表从创建该表时所在的文件组移到新的分区方案或文件组中。 对特定的文件组创建表或索引之前,应确认哪些文件组可用并且有足够的空间供索引使用。
在某些情况下,创建聚集索引可以启用以前禁用的索引。 有关详细信息,请参阅启用索引和约束和禁用索引和约束。
NONCLUSTERED
创建一个指定表的逻辑排序的索引。 对于非聚集索引,数据行的物理排序独立于索引排序。
无论是使用 PRIMARY KEY 和 UNIQUE 约束隐式创建索引,还是使用 CREATE INDEX 显式创建索引,每个表都最多可包含 999 个非聚集索引。
对于索引视图,只能为已定义唯一聚集索引的视图创建非聚集索引。
如果未另行指定,默认索引类型则为非聚集。
index_name
索引的名称。 索引名称在表或视图中必须唯一,但在数据库中不必唯一。 索引名称必须符合标识符的规则。
column
索引所基于的一列或多列。 指定两个或多个列名,可为指定列的组合值创建组合索引。 在 table_or_view_name 后的括号中,按排序优先级列出组合索引中要包括的列。
一个组合索引键中最多可组合 32 列。 组合索引键中的所有列必须在同一个表或视图中。 对于聚集索引,组合索引值允许的最大大小为 900 字节,对于非聚集索引则为 1,700 字节。 对于 SQL 数据库 和 SQL Server 2016 (13.x) 以前的版本,此限制为 16 列和 900 字节。
无法将 ntext、text、varchar(max)、nvarchar(max)、varbinary(max)、xml 或 image 大型对象 (LOB) 数据类型的列指定为索引的键列。 另外,即使 CREATE INDEX 语句中并未引用 ntext、text 或 image 列,视图定义中也不能包含这些列。
如果 CLR 用户定义类型支持二进制排序,则可以为该类型的列创建索引。 另外,对于已定义为用户定义类型列的方法调用的计算列,只要这些方法标记为确定性方法且不执行数据访问操作,便可为该计算列创建索引。 有关为 CLR 用户定义类型的列创建索引的详细信息,请参阅 CLR 用户定义类型。
[ ASC | DESC ]
确定特定索引列的升序或降序排序方向。 默认值为 ASC。
INCLUDE (column [ ,... n ] )
指定要添加到非聚集索引的叶级别的非键列。 非聚集索引可以唯一,也可以不唯一。
在 INCLUDE 列表中列名不能重复,且不能同时用于键列和非键列。 如果对表定义了聚集索引,则非聚集索引始终包含聚集索引列。 有关详细信息,请参阅 Create Indexes with Included Columns。
允许除 text、 ntext和 image之外的所有数据类型。 从 SQL Server 2012 (11.x) 和 Azure SQL 数据库开始,如果任何一个指定的非键列是 varchar(max)、nvarchar(max) 或 varbinary(max) 数据类型,可使用 ONLINE 选项生成或重新生成索引。
精确或不精确的确定性计算列都可以是包含列。 只要计算列的数据类型可以作为包含列,从 image、ntext、text、varchar(max)、nvarchar(max)、varbinary(max) 和 xml 数据类型派生的计算列就可以包含在非键列中 。 有关详细信息,请参阅 计算列上的索引。
有关创建 XML 索引的信息,请参阅 CREATE XML INDEX。
WHERE
通过指定索引中要包含哪些行来创建筛选索引。 筛选索引必须是对表的非聚集索引。 为筛选索引中的数据行创建筛选统计信息。
筛选谓词使用简单比较逻辑且不能引用计算列、UDT 列、空间数据类型列或 hierarchyID 数据类型列。 比较运算符不允许使用 NULL 文本的比较, 而改用 IS NULL 和 IS NOT NULL 运算符。
下面是一些 Production.BillOfMaterials 表筛选谓词示例:
SQL
1 2 3 4 5 | WHERE StartDate > '20000101' AND EndDate <= '20000630' WHERE ComponentID IN (533, 324, 753) WHERE StartDate IN ('20000404', '20000905') AND EndDate IS NOT NULL |
筛选索引不适用于 XML 索引和全文检索。 对于 UNIQUE 索引,仅选定的行必须具有唯一的索引值。 筛选索引不允许有 IGNORE_DUP_KEY 选项。
ON partition_scheme_name ( column_name )
指定分区方案,该方案定义要将分区索引的分区映射到的文件组。 须通过执行 CREATE PARTITION SCHEME 或 ALTER PARTITION SCHEME,使数据库中存在该分区方案。 column_name 指定对已分区索引进行分区所依据的列。 该列必须与 partition_scheme_name 使用的分区函数参数的数据类型、长度和精度相匹配。 column_name 不限于索引定义中的列。 除了在对 UNIQUE 索引分区时,必须从用作唯一键的列中选择 column_name 外,还可以指定基表中的任何列。 通过此限制,数据库引擎可验证单个分区中的键值唯一性。
备注
在对非唯一的聚集索引进行分区时,如果尚未指定分区依据列,则默认情况下数据库引擎将在聚集索引键列表中添加分区依据列。 在对非唯一的非聚集索引进行分区时,如果尚未指定分区依据列,则数据库引擎会添加分区依据列作为索引的非键(包含)列。
如果未指定 partition_scheme_name 或 filegroup 且该表已分区,则索引会与基础表使用相同分区依据列并被放入同一分区方案中。
备注
您不能对 XML 索引指定分区方案。 如果基表已分区,则 XML 索引与该表使用相同的分区方案。
有关分区索引的详细信息,请参阅已分区表和已分区索引。
ON filegroup_name
为指定文件组创建指定索引。 如果未指定位置且表或视图尚未分区,则索引将与基础表或视图使用相同的文件组。 该文件组必须已存在。
ON "default"
在表或视图所在的文件组或分区方案上创建指定索引。
在此上下文中,“default”一词不是关键字。 它是默认文件组的标识符,并且必须进行分隔(类似于 ON "default" 或 ON [default])。 如果指定了 "default",则当前会话的 QUOTED_IDENTIFIER 选项必须为 ON。 这是默认设置。 有关详细信息,请参阅 SET QUOTED_IDENTIFIER。
备注
“default”不表示 CREATE INDEX 上下文中的数据库默认文件组。 这与 CREATE TABLE 不同,在 CREATE TABLE 中,“default”会在数据库默认文件组上找到表。
[ FILESTREAM_ON { filestream_filegroup_name | partition_scheme_name | "NULL" } ]
在创建聚集索引时,指定表的 FILESTREAM 数据的位置。 FILESTREAM_ON 子句用于将 FILESTREAM 数据移动到不同的 FILESTREAM 文件组或分区方案。
filestream_filegroup_name 是 FILESTREAM 文件组的名称。 该文件组须包含一个使用 CREATE DATABASE 或 ALTER DATABASE 语句为该文件组定义的文件;否则,会引发错误。
如果表已分区,则必须包含 FILESTREAM_ON 子句并且必须指定 FILESTREAM 文件组的分区方案,此分区方案需使用与此表分区方案相同的分区功能和分区列。 否则将引发错误。
如果该表未分区,则无法对 FILESTREAM 列分区。 此表的 FILESTREAM 数据必须存储在一个由 FILESTREAM_ON 子句指定的文件组中。
如果正在创建一个聚集索引并且此表不包含 FILESTREAM 列,则可以在 CREATE INDEX 语句中指定 FILESTREAM_ON NULL。
有关详细信息,请参阅 FILESTREAM (SQL Server)。
要为其建立索引的完全限定对象或非完全限定对象。
database_name
数据库的名称。
schema_name
表或视图所属架构的名称。
table_or_view_name
要为其建立索引的表或视图的名称。
必须使用 SCHEMABINDING 定义视图,才能为视图创建索引。 必须先为视图创建唯一的聚集索引,才能为该视图创建非聚集索引。 有关索引视图的详细信息,请参阅“备注”部分。
从 SQL Server 2016 (13.x) 开始,该对象可以是聚集列存储索引存储的表。
Azure SQL 数据库 支持由三部分组成的名称格式 database_name.[schema_name].object_name,其中 database_name 为当前数据库,或 database_name 为 tempdb,object_name 以 # 开头。
::=
指定创建索引时要使用的选项。
PAD_INDEX = { ON | OFF }
指定索引填充。 默认为 OFF。
ON
fillfactor 指定的可用空间百分比应用于索引的中间级页。
OFF 或未指定 fillfactor
考虑到中间级页上的键集,将中间级页填充到接近其容量的程度,以留出足够的空间,使之至少能够容纳索引的最大的一行。
PAD_INDEX 选项只有在指定了 FILLFACTOR 时才有用,因为 PAD_INDEX 使用由 FILLFACTOR 指定的百分比。 如果为 FILLFACTOR 指定的百分比不够大,无法容纳一行,数据库引擎将在内部覆盖该百分比以允许最小值。 无论 fillfactor 的值有多小,中间级索引页上的行数永远都不会小于两行。
在后向兼容语法中,WITH PAD_INDEX 等同于 WITH PAD_INDEX = ON。
FILLFACTOR = fillfactor
指定一个百分比,指示在数据库引擎创建或重新生成索引的过程中,应将每个索引页面的叶级填充到什么程度。 fillfactor 的值必须是 1 到 100 之间的整数。 填充因子的值 0 和 100 在所有方面都是相同的。 如果 fillfactor 为 100,数据库引擎会创建完全填充叶级页的索引。
FILLFACTOR 设置仅在创建或重新生成索引时应用。 数据库引擎并不会在页中动态保持指定的可用空间百分比。
若要查看填充因子设置,请使用 sys.indexes 中的 fill_factor。
重要
使用低于 100 的 FILLFACTOR 值创建聚集索引会影响数据占用的存储空间量,因为在创建聚集索引时 数据库引擎 会重新分布数据。
有关详细信息,请参阅 为索引指定填充因子。
SORT_IN_TEMPDB = { ON | OFF }
指定是否在 tempdb 中存储临时排序结果。 默认设置为 OFF,但“超大规模 Azure SQL 数据库”除外。 对于“超大规模”中的所有索引生成操作,无论指定什么选项,SORT_IN_TEMPDB 始终为 ON,除非使用可恢复索引重新生成。
ON
在 tempdb 中存储用于生成索引的中间排序结果。 如果 tempdb 与用户数据库不在同一组磁盘上,就可缩短创建索引所需的时间。 但是,这会增加索引生成期间所使用的磁盘空间量。
OFF
中间排序结果与索引存储在同一数据库中。
除在用户数据库中创建索引所需的空间外,tempdb 还必须有大约相同的额外空间来存储中间排序结果。 有关详细信息,请参阅用于索引的 SORT_IN_TEMPDB 选项。
在后向兼容语法中,WITH SORT_IN_TEMPDB 等同于 WITH SORT_IN_TEMPDB = ON。
IGNORE_DUP_KEY = { ON | OFF }
指定在插入操作尝试向唯一索引插入重复键值时的错误响应。 IGNORE_DUP_KEY 选项仅适用于创建或重新生成索引后发生的插入操作。 当执行 CREATE INDEX、ALTER INDEX 或 UPDATE 时,该选项无效。 默认为 OFF。
ON
向唯一索引插入重复键值时将出现警告消息。 只有违反唯一性约束的行才会失败。
OFF
向唯一索引插入重复键值时将出现错误消息。 整个 INSERT 操作将被回滚。
对于针对视图创建的索引、非唯一索引、XML 索引、空间索引以及筛选的索引,IGNORE_DUP_KEY 不能设置为 ON。
若要查看 IGNORE_DUP_KEY,请使用 sys.indexes。
在后向兼容语法中,WITH IGNORE_DUP_KEY 等同于 WITH IGNORE_DUP_KEY = ON。
STATISTICS_NORECOMPUTE = { ON | OFF}
指定是否重新计算分布统计信息。 默认为 OFF。
ON
不会自动重新计算过时的统计信息。
OFF
启用统计信息自动更新功能。
若要还原自动统计信息更新,请将 STATISTICS_NORECOMPUTE 设置为 OFF,或在没有 UPDATE STATISTICS 子句的情况下执行 NORECOMPUTE。
重要
如果禁用分布统计的自动重新计算,可能会妨碍查询优化器为涉及该表的查询选取最佳执行计划。
在后向兼容语法中,WITH STATISTICS_NORECOMPUTE 等同于 WITH STATISTICS_NORECOMPUTE = ON。
STATISTICS_INCREMENTAL = { ON | OFF }
适用对象:SQL Server(从 SQL Server 2014 (12.x) 开始)和 Azure SQL 数据库
为 ON 时,根据分区统计信息创建统计信息。 为 OFF 时,删除统计信息树并且 SQL Server 重新计算统计信息。 默认为 OFF。
如果不支持每个分区统计信息,将忽略该选项并生成警告。 对于以下统计信息类型,不支持增量统计信息:
- 使用未与基表的分区对齐的索引创建的统计信息。
- 对 Always On 可读辅助数据库创建的统计信息。
- 对只读数据库创建的统计信息。
- 对筛选的索引创建的统计信息。
- 对视图创建的统计信息。
- 对内部表创建的统计信息。
- 使用空间索引或 XML 索引创建的统计信息。
DROP_EXISTING = { ON | OFF }
一个选项,用于删除并重新生成具有已修改列规范的现有聚集或非聚集索引,同时为该索引设置相同的名称。 默认为 OFF。
ON
指定删除并重新生成现有索引,该索引必须与 index_name 参数具有相同名称。
OFF
指定不删除和重新生成现有索引。 如果指定的索引名称已存在,SQL Server 将显示错误。
使用 DROP_EXISTING,可更改以下内容:
- 将非聚集行存储索引更改为聚集行存储索引。
使用 DROP_EXISTING 时,无法更改:
- 将聚集行存储索引更改为非聚集行存储索引。
- 将聚集列存储索引更改为任何类型的行存储索引。
在后向兼容语法中,WITH DROP_EXISTING 等同于 WITH DROP_EXISTING = ON。
ONLINE = { ON | OFF }
指定在索引操作期间基础表和关联的索引是否可用于查询和数据修改操作。 默认为 OFF。
重要
在 Microsoft SQL Server 的各版本中均不提供联机索引操作。 有关 SQL Server 各个版次支持的功能列表,请参阅 SQL Server 2022 的各个版次及其支持的功能。
ON
在索引操作期间不持有长期表锁。 在索引操作的主要阶段,源表上只使用意向共享 (IS) 锁。 这使得能够继续对基础表和索引进行查询或更新。 操作开始时,在很短的时间内对源对象持有共享 (S) 锁。 在操作结束时,若要创建非聚集索引,则在短时间内会对源获取 S(共享)锁。 如果联机创建或删除聚集索引,且重新生成聚集索引或非聚集索引,便会获取 SCH-M(架构修改)锁。 对本地临时表创建索引时,无法将 ONLINE 设置为 ON。
备注
联机索引创建可以设置 low_priority_lock_wait 选项,请参阅具有联机索引操作的 WAIT_AT_LOW_PRIORITY。
OFF
在索引操作期间应用表锁。 创建、重新生成或删除聚集索引或者重新生成或删除非聚集索引的脱机索引操作将对表获取架构修改 (Sch-M) 锁。 这样可以防止所有用户在操作期间访问基础表。 创建非聚集索引的脱机索引操作将对表获取共享 (S) 锁。 这样可以防止更新基础表,但允许读操作(如 SELECT 语句)。
有关详细信息,请参阅 Perform Index Operations Online。
可以联机创建索引(包括全局临时表中的索引),但以下情况除外:
- XML 索引
- 对本地临时表的索引
- 视图的初始唯一聚集索引
- 已禁用的聚集索引
- 列存储索引
- 聚集索引,前提是基础表包含 LOB 数据类型(image、ntext、text)和空间数据类型
- varchar(max) 和 varbinary(max) 列不能是索引键的一部分。 在 SQL Server(自 SQL Server 2012 (11.x) 起)和 Azure SQL 数据库 中,当表包含 varchar(max) 或 varbinary(max) 列时,可以使用
ONLINE选项生成或重新生成包含其他列的聚集索引。
有关详细信息,请参阅联机索引操作的工作方式。
RESUMABLE = { ON | OFF }
适用对象:SQL Server(从 SQL Server 2019 (15.x) 开始)和 Azure SQL 数据库
指定联机索引操作是否可恢复。
ON
索引操作可恢复。
OFF
索引操作不可恢复。
将 MAX_DURATION = time [MINUTES] 与 RESUMABLE = ON 一起使用(要求 ONLINE = ON)
适用对象:SQL Server(从 SQL Server 2019 (15.x) 开始)和 Azure SQL 数据库
指示可恢复联机索引操作在暂停之前执行的时间(以分钟为单位指定的整数值)。
重要
有关可以联机执行的索引操作的更详细信息,请参阅联机索引操作准则。
备注
列存储索引或禁用索引不支持可恢复联机索引重新生成。
ALLOW_ROW_LOCKS = { ON | OFF }
指定是否允许行锁。 默认值为 ON。
ON
在访问索引时允许使用行锁。 数据库引擎确定何时使用行锁。
OFF
不使用行锁。