合 pg_restore导入数据报警告 pg_restore: WARNING: column "foobar" has type "unknown" DETAIL: Proceeding with relation creation anyway.
Tags: PG故障处理GreenPlumPostgreSQLpg_restore
逻辑备份恢复总结
pg_dump支持指定所要备份的对象:可以单独备份表、schema或者database;pg_dumpall仅支持导出全库数据。pg_dump可以将数据备份为SQL文本文件格式,也支持备份为用户自定义的压缩格式或者TAR包格式。在恢复数据时,对压缩格式和TAR包格式的备份文件可以实现并行恢复,该特性是从8.4版开始支持的。
pg_dumpall仅可以将当前PostgreSQL服务实例中所有database的数据导出为SQL文本(pg_dumpall不支持导出SQL文本以外的其他格式),也可以同时导出表空间和角色的全局对象。 在pg12中,pg_dumpall新增了--exclude-database选项可以排除不想导出的数据库。
PostgreSQL支持以下两种数据恢复方法:
1、使用psql恢复pg_dump或pg_dumpall工具生成的SQL文本格式的数据备份。
2、使用pg_restore工具来恢复由pg_dump工具生成的自定义压缩格式、TAR包格式或者目录格式备份。
生成测试数据:
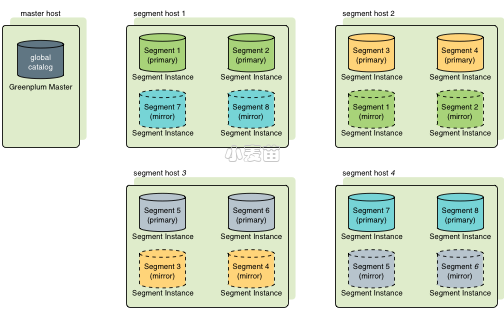
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | postgres=# create database sbtest owner lhr; CREATE DATABASE sysbench /usr/share/sysbench/oltp_common.lua --db-driver=pgsql --pgsql-host=192.168.66.35 --pgsql-port=15433 \ --pgsql-user=postgres --pgsql-password=lhr --pgsql-db=sbtest \ --time=300 --table-size=1000 --tables=10 --threads=16 \ --events=999999999 prepare postgres=# \l+ sbtest List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description --------+-------+----------+------------+------------+-------------------+---------+------------+------------- sbtest | lhr | UTF8 | en_US.utf8 | en_US.utf8 | | 9389 kB | pg_default | (1 row) |
pg_dump:客户端工具
导出sbtest数据库:
1 2 3 4 5 6 7 8 9 10 11 | -- 备份 pg_dump sbtest > /bk/sbtest.sql pg_dump sbtest --file=/bk/sbtest.sql pg_dump --username=postgres --host=192.168.66.35 --port=15433 --dbname=sbtest --format=plain --file=/bk/sbtest.sql -- 恢复 drop database sbtest; create database sbtest; psql --username=postgres --host=192.168.66.35 --port=15433 --dbname=sbtest --file=/bk/sbtest.sql |
导出大文件(并行+压缩)
在不指定文件格式时,默认导出的文件为SQL文本文件,不会压缩,生成的文件较大,但导出较快。
若数据库较大,可通过 -Fc 或--format=custom指定为custom文件,会默认进行5级压缩( --compress=5),生成的文件较小,可以按照缩8倍进行计算,但导出稍慢。在还原二进制文件,需要用 pg_restore 还原。
注意:
1、虽然是custom格式,但是,仍然是文本格式的,可以用vi或txt打开查看。
2、custom格式的文件本身就是压缩文件,若再进行OS基本的压缩(
tar -zcvf aa.tar.gz lhrdb.dmp)作用不大,文件不会变化太大。3、某生产环境备份(350GB,备份后41G,用时2个半小时,平均每小时130GB,每秒15MB);
某生产环境备份(350GB,备份后41G,开32个并行,用时15分钟,每秒50MB)
4、导出和导入的库名可以不一样
5、串行备份,也可以并行恢复
1 2 3 4 5 6 7 8 9 10 11 12 | -- 串行备份并压缩 pg_dump --username=postgres --host=192.168.66.35 --port=15433 --dbname=sbtest --format=custom --file=/bk/sbtest.dmp -- 恢复(导出不是并行,但导入依然可以并行) drop database sbtest; create database sbtest; pg_restore --username=postgres --host=192.168.66.35 --port=15433 --dbname=sbtest /bk/sbtest.dmp -j 32 -- 并行导出导入(推荐,只打包不压缩:tar -cvf sbtest.tar /bk/ --remove-files 解压: tar -xvf bb.tar ) pg_dump --dbname=sbtest --format=directory --jobs=16 --file=/bk/ pg_restore -d db4 /bk/ -j 32 |
pg_dumpall:客户端工具
1 2 3 | pg_dumpall > /bk/pg_all.sql pg_dumpall --username=postgres --host=192.168.66.35 --port=15433 --file=/bk/pg_all.sql |
👉 注意:
1、若是远程导出,则需要多次输入密码,若不想多次输入密码,则可以配置环境变量PGPASSWORD
如下三种写法均可以将testdb和testdc排除:
1 2 3 | pg_dumpall --exclude-database='testd[bc]' -f alldump.sql pg_dumpall --exclude-database='testdb' --exclude-database='testdc' -f alldump_3.sql pg_dumpall --exclude-database=testdb --exclude-database=testdc -f alldump_4.sql |
特别注意:两个--exclude-database选项之间不能用逗号分隔!!!
pg_dump
pg_dump — 把PostgreSQL数据库抽取为一个脚本文件或其他归档文件
大纲
pg_dump [connection-option...] [option...] [dbname]
描述
pg_dump是用于备份一种PostgreSQL数据库的工具。即使数据库正在被并发使用,它也能创建一致的备份。pg_dump不阻塞其他用户访问数据库(读取或写入)。
pg_dump只转储单个数据库。要备份一个集簇或者集簇中 对于所有数据库公共的全局对象(例如角色和表空间),应使用 pg_dumpall。
转储可以被输出到脚本或归档文件格式。脚本转储是包含 SQL 命令的纯文本文件,它们可以用来重构数据库到它被转储时的状态。要从这样一个脚本恢复,将它喂给psql。脚本文件甚至可以被用来在其他机器和其他架构上重构数据库。在经过一些修改后,甚至可以在其他 SQL 数据库产品上重构数据库。
另一种可选的归档文件格式必须与pg_restore配合使用来重建数据库。它们允许pg_restore能选择恢复什么,或者甚至在恢复之前对条目重排序。归档文件格式被设计为在架构之间可移植。
当使用归档文件格式之一并与pg_restore组合时,pg_dump提供了一种灵活的归档和传输机制。pg_dump可以被用来备份整个数据库,然后pg_restore可以被用来检查归档并/或选择数据库的哪些部分要被恢复。最灵活的输出文件格式是“自定义”格式(-Fc)和“目录”格式(-Fd)。它们允许选择和重排序所有已归档项、支持并行恢复并且默认是压缩的。“目录”格式是唯一一种支持并行转储的格式。
当运行pg_dump时,我们应该检查输出中有没有任何警告(打印在标准错误上),特别是考虑到下面列出的限制。
选项
下列命令选项控制输出的内容和格式。
dbname指定要被转储的数据库名。如果没有指定,将使用环境变量
PGDATABASE。如果环境变量也没有设置,则使用指定给该连接的用户名。-a--data-only只转储数据,而不转储模式(数据定义)。表数据、大对象和序列值都会被转储。这个选项类似于指定
--section=data,但是由于历史原因又不完全相同。-b--blobs在转储中包括大对象。这是当
--schema、--table或--schema-only被指定时的默认行为。因此,只有在请求转储一个特定方案或者表的情况中,-b开关才对向转储中加入大对象有用。注意blobs是被考虑的数据,因此在使用--data-only时将被包括在内,但在使用--schema-only时则不会包括。-B--no-blobs在转储中排除大对象。当同时给定
-b和-B时,行为是在数据被转储时输出大对象,请参考-b文档。-c--clean在输出创建数据库对象的命令之前输出清除(删除)它们的命令 (除非也指定了
--if-exists,如果任何对象不存在于 目的数据库中,恢复可能会产生一些伤害性的错误消息)。这个选项只对纯文本格式有意义。对于归档格式,你可以在调用pg_restore时指定该选项。-C--create使得在输出的开始是一个创建数据库本身并且重新连接到被创建的数据库的命令(通过这种形式的一个脚本,在运行脚本之前你连接的是目标安装中的哪个数据库都没有关系)。如果也指定了
--clean,脚本会在重新连接到目标数据库之前先删除它然后再重建。通过--create,输出还会包括数据库的注释(如果有)以及与这个数据库相关的任何配置变量设置,也就是任何提到了这个数据库的ALTER DATABASE ... SET ...命令和ALTER ROLE ... IN DATABASE ... SET ...命令。该数据库本身的访问特权也会被转储,除非指定有--no-acl。这个选项只对纯文本格式有意义。对于归档格式,你可以在你调用pg_restore时指定这个选项。-E *encoding*--encoding=*encoding*以指定的字符集编码创建转储。在默认情况下,该转储会以该数据库的编码创建(另一种得到相同结果的方式是将
PGCLIENTENCODING环境变量设置成想要的转储编码)。-f *file*--file=*file*将输出发送到指定文件。对于基于输出格式的文件这个参数可以被忽略,在那种情况下将使用标准输出。不过对于目录输出格式必须给定这个参数,在目录输出格式中指定的是一个目录而不是一个文件。在这种情况中,该目录会由
pg_dump创建并且不需要以前就存在。-F *format*--format=*format*选择输出的格式。
format可以是下列之一:pplain输出一个纯文本形式的SQL脚本文件(默认值)。ccustom输出一个适合于作为pg_restore输入的自定义格式归档。和目录输出格式一起,这是最灵活的输出格式,它允许在恢复时手动选择和排序已归档的项。这种格式在默认情况还会被压缩。ddirectory输出一个适合作为pg_restore输入的目录格式归档。这将创建一个目录,其中每个被转储的表和大对象都有一个文件,外加一个所谓的目录文件,该文件以一种pg_restore能读取的机器可读格式描述被转储的对象。一个目录格式归档能用标准 Unix 工具操纵,例如一个未压缩归档中的文件可以使用gzip工具压缩。这种格式默认情况下是被压缩的并且也支持并行转储。ttar输出一个适合于输入到pg_restore中的tar-格式归档。tar 格式可以兼容目录格式,抽取一个 tar 格式的归档会产生一个合法的目录格式归档。不过,tar 格式不支持压缩。还有,在使用 tar 格式时,表数据项的相对顺序不能在恢复过程中被更改。-j *njobs*--jobs=*njobs*通过同时归档
njobs个表来运行并行转储。这个选项可能会减少执行转储所需的时间,但也会增加数据库服务器上的负载。你只能和目录输出格式一起使用这个选项,因为这是唯一一种让多个进程能在同一时间写其数据的输出格式。pg_dump将打开njobs+ 1 个到该数据库的连接,因此确保你的max_connections设置足够高以容纳所有的连接。在运行一次并行转储时请求数据库对象上的排他锁可能导致转储失败。其原因是,pg_dump主控进程会在工作者进程将要稍后转储的对象上请求共享锁,以便确保在转储运行时不会有人删除它们并让它们出错。如果另一个客户端接着请求一个表上的排他锁,那个锁将不会被授予但是会被排入队列等待主控进程的共享锁被释放。因此,任何其他对该表的访问将不会被授予或者将排在排他锁请求之后。这包括尝试转储该表的工作者进程。如果没有任何防范措施,这可能会是一种经典的死锁情况。要检测这种冲突,pg_dump工作者进程使用NOWAIT选项请求另一个共享锁。 如果该工作者进程没有被授予这个共享锁,其他某人必定已经在同时请求了一个排他锁并且没有办法继续转储,因此pg_dump除了中止转储之外别无选择。对于一个一致的备份,数据库服务器需要支持同步的快照,在PostgreSQL 9.2的主服务器和10的后备服务器中引入了一种特性。有了这种特性,即便数据库客户端使用不同的连接,也可以保证他们看到相同的数据集。pg_dump -j使用多个数据库连接,它用主控进程连接到数据一次,并且为每一个工作者任务再一次连接数据库。如果没有同步快照特征,在每一个连接中不同的工作者任务将不能被保证看到相同的数据,这可能导致一个不一致的备份。如果你希望运行一个 9.2 之前服务器的并行转储,你需要确保数据库内容从主控进程连接到数据库一直到最后一个工作者任务连接到数据库之间不会改变。做这些最简单的方法是在开始备份之前停止任何访问数据库的数据修改进程(DDL 以及 DML)。当对一个 9.2 之前的PostgreSQL服务器运行pg_dump -j时,你还需要指定--no-synchronized-snapshots参数。-n *pattern*--schema=*pattern*只转储匹配
pattern的模式,这会选择模式本身以及它所包含的所有对象。当没有指定这个选项时,目标数据库中所有非系统模式都将被转储。多个模式可以通过书写多个-n开关来选择。另外,pattern参数可以被解释为一种根据psql's\d命令所用的相同规则(请参见下面的Patterns)编写的模式,这样多个模式也可以通过在该模式中书写通配字符来选择。在使用通配符时,如果需要阻止 shell 展开通配符需要小心引用该模式,请参见下面的Examples。注意当-n被指定时,pg_dump不会尝试转储所选模式可能依赖的任何其他数据库对象。因此,无法保证一次指定模式转储的结果能够仅凭其本身被成功地恢复到一个干净的数据库中。注意当-n被指定时,非模式对象(如二进制大对象)不会被转储。你可以使用--blobs开关将二进制大对象加回到该转储中。-N *pattern*--exclude-schema=*pattern*不转储匹配
pattern模式的任何模式。该模式被根据-n所用的相同规则被解释。-N可以被给定多次来排除匹配几个模式中任意一个的模式。当-n和-N都被给定时,该行为是只转储匹配至少一个-n开关但是不匹配-N开关的模式。如果只有-N而没有-n,那么匹配-N的模式会被从一个正常转储中排除。-O--no-owner不输出设置对象拥有关系来匹配原始数据库的命令。默认情况下,pg_dump会发出
ALTER OWNER或SET SESSION AUTHORIZATION语句来设置被创建的数据库对象的拥有关系。除非该脚本被一个超级用户(或是拥有脚本中所有对象的同一个用户)启动,这些语句都将会失败。要使一个脚本能够被任意用户恢复,但把所有对象的拥有关系都给这个用户,可指定-O。这个选项只对纯文本格式有意义。对于归档格式,你可以在调用pg_restore时指定该选项。-R--no-reconnect这个选项已经废弃,但是为了向后兼容仍然能被接受。
-s--schema-only只转储对象定义(模式),而非数据。这个选项是
--data-only的逆选项。它和指定--section=pre-data --section=post-data相似,但是由于历史原因又不完全相同。(不要把这个选项和--schema选项混淆,后者在“schema”的使用上有不同的含义)。要为数据库中表的一个子集排除表数据,见--exclude-table-data。-S *username*--superuser=*username*指定要在禁用触发器时使用的超级用户的用户名。只有使用
--disable-triggers时,这个选项才相关(通常,最好省去这个选项,而作为超级用户来启动结果脚本来取而代之)。-t *pattern*--table=*pattern*只转储名字匹配
pattern的表。通过写多个-t开关可以选择多个表。另外,pattern参数可以被解释为一种根据psql's\d命令所用的相同规则(请参见下面的Patterns)编写的模式,这样多个表也可以通过在该模式中书写通配字符来选择。在使用通配符时,如果需要阻止 shell 展开通配符需要小心引用该模式,请参见下面的Examples。当-t被使用时,-n和-N开关不会有效果,因为被-t选择的表将被转储而无视那些开关,并且非表对象将不会被转储。注意当-t被指定时,pg_dump不会尝试转储所选表可能依赖的任何其他数据库对象。因此,无法保证一次指定表转储的结果能够仅凭其本身被成功地恢复到一个干净的数据库中。注意-t开关的行为不完全向前兼容 8.2 之前的PostgreSQL版本。以前,写-t tab将转储所有命名为tab的表,但现在它仅仅转储在你默认搜索路径中可见的那一个。要得到旧的行为,你可以写成-t '*.tab'。还有,你必须写类似-t sch.tab的东西来选择一个特定模式中的一个表,而不是用老的惯用语-n sch -t tab。-T *pattern*--exclude-table=*pattern*不转储匹配
pattern模式的任何表。该模式被根据-t所用的相同规则被解释。-T可以被给定多次来排除匹配几个模式中任意一个的模式。当-t和-T都被给定时,该行为是只转储匹配至少一个-t开关但是不匹配-T开关的表。如果只有-T而没有-t,那么匹配-T的表会被从一个正常转储中排除。-v--verbose指定冗长模式。这将导致pg_dump向标准错误输出详细的对象注释以及转储文件的开始/停止时间,还有进度消息。
-V--versionpg_dump版本并退出。
-x--no-privileges--no-acl防止转储访问特权(授予/收回命令)。
-Z *0..9*--compress=*0..9*指定要使用的压缩级别。零意味着不压缩。对于自定义归档格式,这会指定个体表数据段的压缩,并且默认是进行中等级别的压缩。对于纯文本输出,设置一个非零压缩级别会导致整个输出文件被压缩,就好像它被gzip处理过一样,但是默认是不压缩。tar 归档格式当前完全不支持压缩。
--binary-upgrade这个选项用于就地升级功能。我们不推荐也不支持把它用于其他目的。这个选项在未来的发行中可能被改变而不做通知。
--column-inserts--attribute-inserts将数据转储为带有显式列名的
INSERT命令(INSERT INTO *table* (*column*, ...) VALUES ...)。这将使得恢复过程非常慢,这主要用于使转储能够被载入到非PostgreSQL数据库中。重新加载期间的任何错误都将导致有问题的INSERT相关的行将丢失,而不是整个表内容。--disable-dollar-quoting这个选项禁止在函数体中使用美元符号引用,并且强制它们使用 SQL 标准字符串语法被引用。
--disable-triggers只有在创建一个只转储数据的转储时,这个选项才相关。它指示pg_dump包括在数据被重新载入时能够临时禁用目标表上的触发器的命令。如果你在表上有引用完整性检查或其他触发器,并且你在数据重新载入期间不想调用它们,请使用这个选项。当前,为
--disable-triggers发出的命令必须作为超级用户来执行。因此,你还应当使用-S指定一个超级用户名,或者宁可作为一个超级用户启动结果脚本。这个选项只对纯文本格式有意义。对于归档格式,你可以在调用pg_restore时指定这个选项。--enable-row-security只有在转储具有行安全性的表的内容时,这个选项才相关。默认情况下, pg_dump将把 row_security设置为 off 来确保从该表中转储 出所有的数据。如果用户不具有足够能绕过行安全性的特权,那么会抛出 一个错误这个参数指示pg_dump将 row_security设置为 on,允许用户只转储该表中 它们能够访问到的部分内容。注意如果当前你使用了这个选项,你可能还想得到
INSERT格式的转储,因为恢复期间的COPY FROM不支持行安全性。--exclude-table-data=*pattern*不转储匹配
pattern模式的任何表中的数据。该模式根据-t的相同规则被解释。--exclude-table-data可以被给定多次来排除匹配多个模式的表。当你需要一个特定表的定义但不想要其中的数据时,这个选项就有用了。要排除数据库中所有表的数据,见--schema-only。--extra-float-digits=*ndigits*在转储浮点数据时使用规定的
extra_float_digits值,而不是最大可用精度。以备份目的生成的常规转储不使用此选项。--if-exists时间条件性命令(即增加一个
IF EXISTS子句)来清除数据库和其他对象。 只有同时指定了--clean时,这个选项才可用。--include-foreign-data=*foreignserver*使用与
foreignserver模式匹配的外部服务器转储任何外部表的数据。可以通过编写 多个--include-foreign-data开关来选择多个外部服务器。 同样,根据psql's\d命令使用的相同规则, 将foreignserver参数解释为模式。 (请参见下面的Patterns),因此也可以通过在模式中写入通配符来选择多个外部服务器。使用通配符时, 如果需要,请小心引用该模式,以防止Shell扩展通配符。请参见下面的Examples。 唯一的例外是不允许使用空模式。注意指定--include-foreign-data时,pg_dump不会检查外部表是否可写。因此,不能保证可以成功还原外部表转储的结果。--inserts将数据转储为
INSERT命令(而不是COPY)。这将使得恢复非常慢,这主要用于使转储能够被载入到非PostgreSQL数据库中。重新加载期间的任何错误都将导致有问题的INSERT相关的行将丢失,而不是整个表内容。注意如果你已经重新安排了列序,该恢复可能会一起失败。--column-inserts选项对于列序改变是安全的,但是会更慢。--load-via-partition-root在为一个分区表转储数据时,让
COPY语句或者INSERT语句把包含它的分区层次的根而不是分区自身作为目标。这导致在数据被装载时,会为每一个行重新确定合适的分区。如果在一台服务器上重新装载数据时会出现行并不是总是落入到和原始服务器上相同的分区中的情况,这个选项就很有用。例如,如果分区列是文本类型并且两个系统中用于排序分区列的排序规则有着不同的定义,就会发生这种情况。在从用这个选项制作的归档恢复时,最好不要使用并行,因为pg_restore将不能准确地知道一个给定的归档数据项将把数据装载到哪个分区中。这会导致效率不高,因为在并行任务见会有锁冲突,或者甚至可能由于在所有的相关数据被装载前建立了外键约束而导致重新装载失败。--lock-wait-timeout=*timeout*在转储的开始从不等待共享表锁的获得。而是在指定的
timeout内不能锁定一个表时失败。超时时长可以用SET statement_timeout接受的任何格式指定(允许的值根据你从其转出的服务器版本变化,但是从 7.3 以来的所有版本都接受一个整数表示的毫秒数。如果从 7.3 以前的服务器转出,这个选项会被忽略。)。--no-comments不转储注释。
--no-publications不转储publication。
--no-security-labels不转储安全标签。
--no-subscriptions不转储订阅。
--no-sync默认情况下,
pg_dump将等待所有文件被安全地写入磁盘。这个选项会让pg_dump不等待直接返回,这样会更快,但是也意味着后续的一次操作系统崩溃会让该转储损坏。通常这个选项对测试有用,但是不应该在从生产安装中转储数据时使用。--no-synchronized-snapshots这个选项允许对 9.2 以前的服务器运行
pg_dump -j,详见-j参数的文档。--no-tablespaces不要输出选择表空间的命令。通过这个选项,在恢复期间所有的对象都会被创建在任何作为默认的表空间中。这个选项只对纯文本格式有意义。对于归档格式,你可以在调用
pg_restore时指定该选项。--no-unlogged-table-data不转储非日志记录表的内容。这个选项对于表定义(模式)是否被转储没有影响,它只会限制转储表数据。当从一个后备服务器转储时,在非日志记录表中的数据总是会被排除。
--on-conflict-do-nothing增加
ON CONFLICT DO NOTHING到INSERTcommands。 除非规定了--inserts,--column-inserts或--rows-per-insert,否则此选项是无效的,.--quote-all-identifiers强制引用所有标识符。当从PostgreSQL主版本与pg_dump不同的服务器上转储一个数据库时或者当输出准备载入到一个具有不同主版本的服务器时,推荐使用这个选项。默认情况下,pg_dump只对在其主版本中是被保留词的标识符加上引号。在转储其他版本服务器时,这种默认行为有时会导致兼容性问题,因为那些版本可能具有些许不同的被保留词集合。使用
--quote-all-identifiers能阻止这种问题,但代价是转储脚本更难阅读。--rows-per-insert=*nrows*数据转储为
INSERT命令(而不是COPY)。 控制每个INSERT命令的最大行数。 指定的值必须大于零。重新加载期间的任何错误都将导致有问题的INSERT相关的行将丢失,而不是整个表内容。--section=*sectionname*只转储命名节。节的名称可以是
pre-data、data或post-data。这个选项可以被指定多次来选择多个节。默认是转储所有节。数据节包含真正的表数据、大对象内容和序列值。数据后项包括索引、触发器、规则和除了已验证检查约束之外的约束的定义。数据前项包括所有其他数据定义项。--serializable-deferrable为转储使用一个
可序列化事务,以保证所使用的快照与后来的数据库状态是一致的。但是这样做是在事务流中等待一个点,在该点上不能存在异常,这样就不会有转储失败或者导致其他事务带着serialization_failure回滚的风险。关于事务隔离和并发控制详见第 13 章。对于一个只为灾难恢复存在的转储,这个选项没什么益处。如果一个转储被用来在原始数据库持续被更新期间载入一份用于报表或其他只读负载的数据库拷贝时,这个选项就有所帮助。如果没有这个选项,转储可能会反映一个与最终提交事务的任何执行序列都不一致的状态。例如,如果使用了批处理技术,一个批处理在转储中可以显示为关闭,而其中的所有项都不出现。如果 pg_dump 被启动时没有读写事务在活动,则这个选项没有什么不同。如果有读写事务在活动,该转储的启动可能会被延迟一段不确定的时间。一旦开始运行,有没有这个开关的表现是相同的。--snapshot=*snapshotname*在做一个数据库的转储时指定一个同步的快照(详见 表 9.88)。在需要把转储和一个逻辑复制槽(见第 48 章) 或者一个并发会话同步时可以用上这个选项。在并行转储的情况下,将使用这个选项指定的快照名而不是取一个新快照。
--strict-names要求每一个模式(
-n/--schema)和表(-t/--table)限定符匹配要转储的数据库中至少一个模式/表。注意,如果没有找到有这样的模式/表限定符匹配,即便没有--strict-names,pg_dump也将生成一个错误。这个选项对-N/--exclude-schema、-T/--exclude-table或者--exclude-table-data没有效果。无法匹配任何对象的排除模式不会被当作错误。--use-set-session-authorization输出 SQL-标准的
SET SESSION AUTHORIZATION命令取代ALTER OWNER命令来确定对象的所有关系。这让该转储更加兼容标准,但是取决于该转储中对象的历史,该转储可能无法正常恢复。而且,一个使用SET SESSION AUTHORIZATION的转储将一定会要求超级用户特权来正确地恢复,而ALTER OWNER要求更少的特权。-?--help显示有关pg_dump命令行参数的帮助并退出。
下列命令行选项控制数据库连接参数。
-d *dbname*--dbname=*dbname*指定要连接的数据库的名称。 这等效于在命令行上将
dbname指定为 第一个非选项参数。dbname可以是连接字符串。 如果是这样,连接字符串参数将覆盖所有冲突的命令行选项。-h *host*--host=*host*指定服务器正在运行的机器的主机名。如果该值开始于一个斜线,它被用作一个 Unix 域套接字的目录。默认是从
PGHOST环境变量中取得(如果被设置),否则将尝试一次 Unix 域套接字连接。-p *port*--port=*port*指定服务器正在监听连接的 TCP 端口或本地 Unix 域套接字文件扩展名。默认是放在
PGPORT环境变量中(如果被设置),否则使用编译在程序中的默认值。-U *username*--username=*username*要作为哪个用户连接。
-w--no-password从不发出一个口令提示。如果服务器要求口令认证并且没有其他方式提供口令(例如一个
.pgpass文件),那么连接尝试将失败。这个选项对于批处理任务和脚本有用,因为在其中没有一个用户来输入口令。-W--password强制pg_dump在连接到一个数据库之前提示要求一个口令。这个选项从来不是必须的,因为如果服务器要求口令认证,pg_dump将自动提示要求一个口令。但是,pg_dump将浪费一次连接尝试来发现服务器想要一个口令。在某些情况下,值得键入
-W来避免额外的连接尝试。--role=*rolename*指定一个用来创建该转储的角色名。这个选项导致pg_dump在连接到数据库后发出一个
SET ROLErolename命令。当已认证用户(由-U指定)缺少pg_dump所需的特权但是能够切换到一个具有所需权利的角色时,这个选项很有用。一些安装有针对直接作为超级用户登录的策略,使用这个选项可以让转储在不违反该策略的前提下完成。
环境
PGDATABASEPGHOSTPGOPTIONSPGPORTPGUSER默认连接参数
PG_COLOR规定在诊断消息中是否使用颜色。可能的值为
always、auto、never。.
和大部分其他PostgreSQL工具相似,这个工具也使用libpq(见第 33.14 节)支持的环境变量。
诊断
pg_dump在内部执行SELECT语句。如果你运行pg_dump时出现问题,确定你能够从正在使用的数据库中选择信息,例如psql。此外,libpq前端-后端库所使用的任何默认连接设置和环境变量都将适用。
pg_dump的数据库活动会被统计收集器正常地收集。如果不想这样,你可以通过PGOPTIONS或ALTER USER命令设置参数track_counts为假。
注解
如果你的数据库集簇对于template1数据库有任何本地添加,要注意将pg_dump的输出恢复到一个真正的空数据库。否则你很可能由于以增加对象的重复定义而得到错误。要创建一个不带任何本地添加的空数据库,从template0而不是template1复制它,例如:
1 | CREATE DATABASE foo WITH TEMPLATE template0; |
当一个只含数据的转储被选中并且使用了选项--disable-triggers时,pg_dump在开始插入数据之前会发出命令禁用用户表上的触发器,并且接着在数据被插入之后发出命令重新启用它们。如果恢复中途被停止,系统目录可能会停留在一种错误状态。
pg_dump产生的转储文件不包含优化器用来做出查询计划决定的统计信息。因此,在从一个转储文件恢复后运行ANALYZE来确保最优性能是明智的,详见第 24.1.3 节和第 24.1.6 节。
因为pg_dump被用来传输数据到更新版本的PostgreSQL,pg_dump的输出被认为可以载入到比pg_dump版本更新的PostgreSQL服务器中。pg_dump也能够从比其版本更旧的PostgreSQL服务器中转储(当前支持回退到版本 7.0)。不过,pg_dump无法从比起主版本号更新的PostgreSQL服务器中转储,它甚至将拒绝冒着创建一个非法转储的风险尝试。还有,不保证pg_dump的输出能被载入到一个更旧主版本的服务器 — 即使该转储是从该版本的服务器中被取得也不行。将一个转储文件载入到一个更旧的服务器可能需要手工编辑该转储文件来移除旧服务器无法理解的语法。在跨版本的情况下,推荐使用--quote-all-identifiers选项,因为它可以避免因为不同PostgreSQL版本间的保留词列表变化而发生问题。
在转储逻辑复制订阅时,pg_dump将生成使用connect = false选项的CREATE SUBSCRIPTION命令,这样恢复订阅时不会建立远程连接来创建复制槽或者进行初始的表拷贝。通过这种方式,可以无需到远程服务器的网络访问就能恢复该转储。然后就需要用户以一种合适的方式重新激活订阅。如果涉及到的主机已经改变,连接信息可能也必须被改变。在开启一次新的全表拷贝之前,截断目标表也可能是合适的。
实例
要把一个数据库mydb转储到一个 SQL 脚本文件:
1 | $ pg_dump mydb > db.sql |
要把这样一个脚本重新载入到一个(新创建的)名为newdb的数据库中:
1 | $ psql -d newdb -f db.sql |
要转储一个数据库到一个自定义格式归档文件:
1 | $ pg_dump -Fc mydb > db.dump |
要转储一个数据库到一个目录格式的归档:
1 | $ pg_dump -Fd mydb -f dumpdir |
要用 5 个并行的工作者任务转储一个数据库到一个目录格式的归档:
1 | $ pg_dump -Fd mydb -j 5 -f dumpdir |
要把一个归档文件重新载入到一个(新创建的)名为newdb的数据库:
1 | $ pg_restore -d newdb db.dump |
把一个归档文件重新装载到同一个数据库(该归档正是从这个数据库中转储得来)中,丢掉那个数据库中的当前内容:
1 | $ pg_restore -d postgres --clean --create db.dump |
要转储一个名为mytab的表:
1 | $ pg_dump -t mytab mydb > db.sql |
要转储detroit模式中名称以emp开始的所有表,排除名为employee_log的表:
1 | $ pg_dump -t 'detroit.emp*' -T detroit.employee_log mydb > db.sql |
要转储名称以east或者west开始并且以gsm结束的所有模式,排除名称包含词test的任何模式:
1 | $ pg_dump -n 'east*gsm' -n 'west*gsm' -N '*test*' mydb > db.sql |
同样,用正则表达式记号法来合并开关:
1 | $ pg_dump -n '(east|west)*gsm' -N '*test*' mydb > db.sql |
要转储除了名称以ts_开头的表之外的所有数据库对象:
1 | $ pg_dump -T 'ts_*' mydb > db.sql |
要在-t和相关开关中指定一个大写形式或混合大小写形式的名称,你需要双引用该名称,否则它会被折叠到小写形式 (请参见下面的Patterns)。但是双引号对于 shell 是特殊的,所以反过来它们必须被引用。因此, 要转储一个有混合大小写名称的表,你需要类似这样的东西:
1 | $ pg_dump -t "\"MixedCaseName\"" mydb > mytab.sql |
pg_dumpall
pg_dumpall — 将一个PostgreSQL数据库集簇抽取到一个脚本文件中
大纲
pg_dumpall [connection-option...] [option...]
描述
pg_dumpall工具可以一个集簇中所有的PostgreSQL数据库写出到(“转储”)一个脚本文件。该脚本文件包含可以用作psql的输入SQL命令来恢复数据库。它会对集簇中的每个数据库调用pg_dump来完成该工作。pg_dumpall还转储对所有数据库公用的全局对象(pg_dump不保存这些对象),也就是说数据库角色和表空间都会被转储。 目前这包括适数据库用户和组、表空间以及适合所有数据库的访问权限等属性。
因为pg_dumpall从所有数据库中读取表,所以你很可能需要以一个数据库超级用户的身份连接以便生成完整的转储。同样,你也需要超级用户特权执行保存下来的脚本,这样才能增加角色和组以及创建数据库。
SQL 脚本将被写出到标准输出。使用 -f/--file 选项或者 shell 操作符可以把它重定向到一个文件。
pg_dumpall需要多次连接到PostgreSQL服务器(每个数据库一次)。如果你使用口令认证,可能每次都会要求口令。这种情况下使用一个~/.pgpass会比较方便。详见第 33.15 节。
选项
下列命令行选项用于控制输出的内容和格式。
-a--data-only只转储数据,不转储模式(数据定义)。
-c--clean包括在重建数据库之前清除(移除)它们的 SQL 命令。角色和表空间的
DROP命令也会被加入进来。-E *encoding*--encoding=*encoding*用指定的字符集编码创建转储。默认情况下,转储使用数据库的编码创建(另一种得到相同结果的方法是设置
PGCLIENTENCODING环境变量为想要的转储编码)。-f *filename*--file=*filename*将输出发送到指定的文件中。如果省略,将使用标准输出。
-g--globals-only只转储全局对象(角色和表空间),而不转储数据库。
-O--no-owner不输出用于设置对象所有权以符合原始数据库的命令。默认情况下,pg_dumpall发出
ALTER OWNER或SET SESSION AUTHORIZATION语句来设置被创建的模式元素的所有权。除非脚本是由一个超级用户(或者是拥有脚本中所有对象的同一个用户)所运行,这些语句在脚本运行时会失败。要使得一个脚本能被任意用户恢复,但又不想给予该用户所有对象的所有权,可以指定-O。-r--roles-only只转储角色,不转储数据库和表空间。
-s--schema-only只转储对象定义(模式),不转储数据。
-S *username*--superuser=*username*指定要在禁用触发器时使用的超级用户的用户名。只有使用
--disable-triggers时,这个选项才相关(通常,最好省去这个选项,而作为超级用户来启动结果脚本来取而代之)。-t--tablespaces-only只转储表空间,不转储数据库和角色。
本人提供Oracle(OCP、OCM)、MySQL(OCP)、PostgreSQL(PGCA、PGCE、PGCM)等数据库的培训和考证业务,私聊QQ646634621或微信dbaup66,谢谢!