
合 MSSQL索引碎片和usp_AdaptiveIndexDefrag的使用
Tags: MSSQLSQL Server索引性能调优重建索引usp_AdaptiveIndexDefrag索引碎片重组索引
简介
在SQL Server中,索引碎片指的是索引存储结构中的空隙和未被充分利用的空间,这可能会导致数据库性能下降。索引是用于加速数据库查询操作的数据结构,它们可以按照特定的列对数据库表进行排序和组织,从而提高检索效率。当数据库中的数据发生变化(例如插入、更新、删除操作)时,索引可能会出现碎片化。
当索引包含的页中,索引中的逻辑排序(基于索引中的键值)与索引页中的物理排序不匹配时,就存在碎片。
无论何时对基础数据执行插入、更新或删除操作,数据库引擎 都会自动修改索引。例如,在表中添加行可能会导致拆分行存储索引中的现有页,以腾出空间来插入新键值。随着时间的推移,这些修改可能会导致索引中的信息分散在数据库中(含有碎片)。当索引包含的页中的逻辑排序(基于键值)与数据文件中的物理排序不匹配时,就存在碎片。
大量碎片式索引可能会降低查询性能,因为需要额外 I/O 来查找索引指向的数据。较多的 I/O 会导致应用程序响应缓慢,特别是在涉及扫描操作时。
索引是数据库引擎中针对表(有时候也针对视图)建立的特别数据结构,用来帮助查找和整理数据,它的重要性体现在能够使数据库引擎快速返回查询结果。当对索引所在的基础数据表进行增删改时,若存储的数据进行了不适当的跨页(SQL Server中存储的最小单位是页,页是不可再分的),就会导致索引碎片的产生。随着索引碎片的不断增多,查询响应时间就会变慢,性能也因此而下降。要解决这个问题,可以通过重新生成或重新组织索引来解决。
索引碎片分类
一般我们可以把碎片分为外部碎片和内部碎片。外部碎片,可分为逻辑碎片(索引)和区碎片(堆)。内部碎片主要有页填充密度衡量。
逻辑碎片,这是索引的叶级页中出错页所占的百分比。对于出错页,分配给索引的下一个物理页不是当前叶级页中的下一页 指针所指向的页。 这种碎片发生在索引的逻辑结构上,即索引中的页顺序与相应表中的实际行顺序不匹配。这可能是由于数据的插入、更新和删除操作导致的。逻辑碎片可以导致查询性能下降,因为数据库引擎需要更多的I/O操作来读取和处理这些碎片。
物理碎片: 这种碎片发生在索引所在的物理存储结构上,即索引的页不是顺序存储的,而是分散在磁盘上。物理碎片通常是由于数据页的分配和释放操作引起的。物理碎片同样会导致磁盘I/O的增加,从而影响性能。
区碎片,这是堆的叶级页中出错区所占的百分比。出错区是指:包含堆当前页的区在物理上不是包含前一页的区后的下一个区。
内部碎片,指示索引页的平均填充率(以百分比表示)。100% 表示索引页完全填充,没有碎片。不过这种理想状态很难存在。
内部碎片
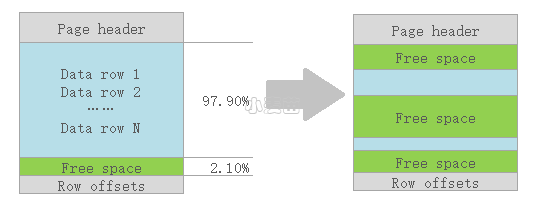
先说说内部碎片,右键索引属性下可以查看其页填充度。

该索引的页填充度为 97.90%,说明还有一部分空间未使用,有点浪费了。当经过多次DML操作后(如下图),页内有较多的空间空闲出来了,而实际存储的数据只是很少一部分。所以当我们查询部分数据时,需要查询更多的数据页才能获取完整数据,这样增加了IO。
外部碎片
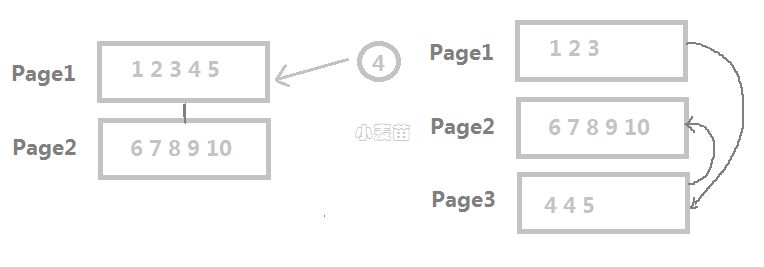
那外部碎片又是什么样子呢?什么样的数据页是物理不连续呢?
我们创建一个数据文件,数据文件将划分成数据页来存储数据。假设我们预先给数据文件分配一定的空间,数据页分配理应是按顺序在磁盘文件上分配空间(如下图)。当新的数据插入表后,页内空间不足以填充新的行数据,因此产生了页拆分。由于索引键的顺序性,逻辑上要保证其页是顺序的,但是物理上已经出现了跨多个页的情况。这种就是外部碎片。同理,堆表的区碎片也类似。
如何查看索引碎片,可通过系统函数sys.dm_db_index_physical_stats 查看。
| 列 | 说明 |
|---|---|
| avg_fragmentation_in_percent | 堆的区碎片/逻辑碎片(索引中的无序页)的百分比 |
| avg_page_space_used_in_percent | 平均页密度 |
既然索引碎片产生了更多的空间和磁盘IO,定期清理仍是有必要的。参考以上的字段 avg_fragmentation_in_percent ,进行索引重组或者索引重建。
| avg_fragmentation_in_percent | 处理方法 |
|---|---|
| > 5% 且 < = 30% | ALTER INDEX REORGANIZE |
| > 30% | ALTER INDEX REBUILD WITH (ONLINE = ON) |
查看碎片也可以通过SSMS工具来查看:
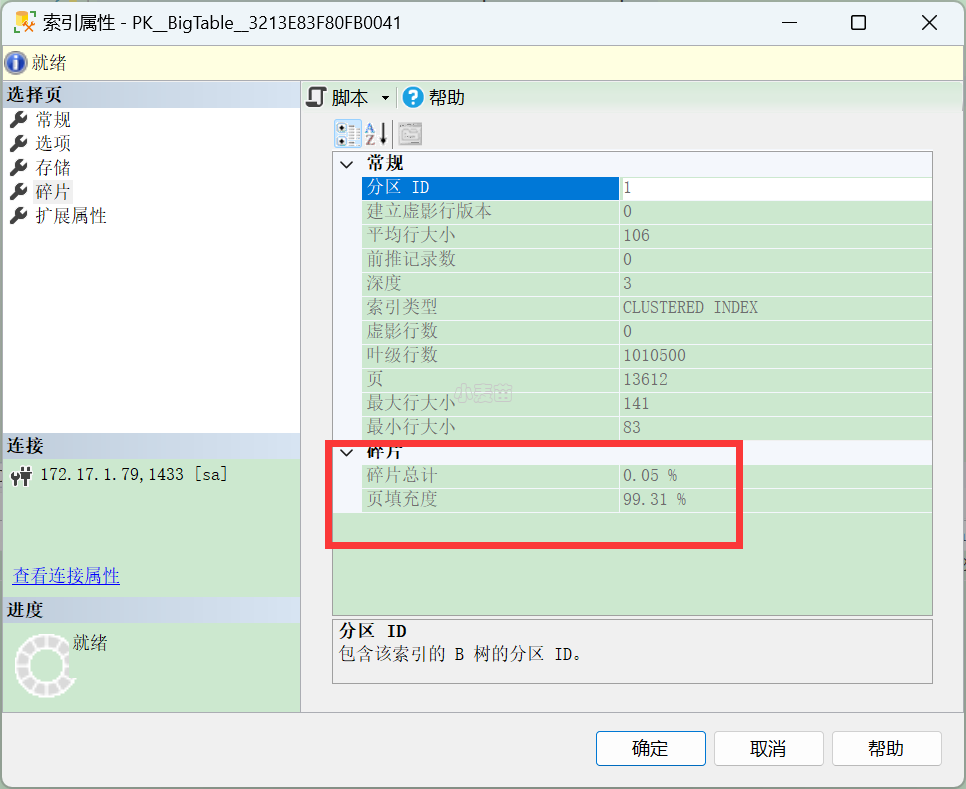
碎片总计要越小越好,而页填充度要越高越好!!!
重新组织索引(重组索引)使用的系统资源最少,并且是联机操作。也就是说,不保留长期阻塞性表锁,且对基础表的查询或更新可以在 ALTER INDEX REORGANIZE 事务处理期间继续进行。数据库引擎 通过以物理方式重新排序叶级别页,以匹配叶节点逻辑顺序(从左到右),从而对表和视图中的聚集索引和非聚集索引的叶级别进行碎片整理。重新组织还会根据索引的填充因子值压缩索引页。
重新生成索引(重建索引)将会删除并重新创建索引。重新生成操作可以联机或脱机执行,具体取决于索引类型和 数据库引擎 版本。对于行存储索引,重新生成操作会:删除碎片;根据指定或现有的填充因子设置来压缩页,从而回收磁盘空间;还会在连续页中重新排序索引行。如果指定 ALL,将删除表中的所有索引,然后在一个事务中重新生成。不必预先删除外键约束。重新生成具有 128 个区或更多区的索引时,数据库引擎延迟实际的页释放及其关联的锁,直到事务提交。
不过也有注意以下事项:
- 如果删除并重建了聚集索引,那么非聚集索引也将重建。
- 对于堆表的产生的碎片,可以创建并删除聚集索引,必要可保留聚集索引。
- 当索引重新生成发生时,物理介质必须有足够的空间来存储索引的两个副本。
以下场景强制自动在表上重新生成所有行存储非聚集索引:
- 在表上创建聚集索引
- 删除聚集索引,从而使表存储为堆
- 更改聚集键以包括或排除列
以下场景不需要在表上自动重新生成所有行存储非聚集索引:
- 重新生成唯一聚集索引
- 重新生成非唯一聚集索引
- 更改索引架构,例如将分区方案应用于聚集索引或将聚集索引移到其他文件组
如何知道是否发生了索引碎片?
方法1 查询sys.dm_db_index_physical_stats函数
相关SQL查看最后的总结部分。
方法2:使用SHOWCONTIG
在SQL Server数据库中,可以通过DBCC SHOWCONTIG WITH ALL_INDEXES或DBCC SHOWCONTIG(表ID或者表名) WITH ALL_INDEXES来检查索引碎片情况。
1 2 3 4 5 | -- 全库 DBCC SHOWCONTIG WITH ALL_INDEXES; -- 单个表 DBCC SHOWCONTIG(表ID或者表名) WITH ALL_INDEXES; |

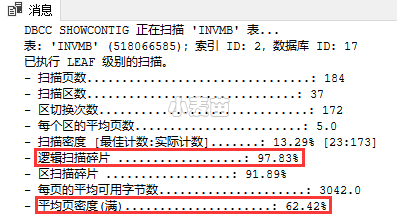
通过对逻辑扫描碎片(过高)、平均页密度(满)(过低)的结果分析,判定是否需要进行索引处理,如下所示:
逻辑扫描碎片 ..................:97.83% 该百分比应该在0%到10%之间,高了则说明有外部碎片。
平均页密度(满) ..................:62.42% 该百分比应该尽可能靠近100%,低了则说明有外部碎片。
Page Scanned-扫描页数:如果你知道行的近似尺寸和表或索引里的行数,那么你可以估计出索引里的页数。看看扫描页数,如果明显比你估计的页数要高,说明存在内部碎片。
Extents Scanned-扫描扩展盘区数:用扫描页数除以8,四舍五入到下一个最高值。该值应该和DBCC SHOWCONTIG返回的扫描扩展盘区数一致。如果DBCC SHOWCONTIG返回的数高,说明存在外部碎片。碎片的严重程度依赖于刚才显示的值比估计值高多少。
Extent Switches-扩展盘区开关数:该数应该等于扫描扩展盘区数减1。高了则说明有外部碎片。
Avg. Pages per Extent-每个扩展盘区上的平均页数:该数是扫描页数除以扫描扩展盘区数,一般是8。小于8说明有外部碎片。
Scan Density [Best Count:Actual Count]-扫描密度[最佳值:实际值]:DBCC SHOWCONTIG返回最有用的一个百分比。这是扩展盘区的最佳值和实际值的比率。该百分比应该尽可能靠近100%。低了则说明有外部碎片。
Logical Scan Fragmentation-逻辑扫描碎片:无序页的百分比。该百分比应该在0%到10%之间,高了则说明有外部碎片。
Extent Scan Fragmentation-扩展盘区扫描碎片:无序扩展盘区在扫描索引叶级页中所占的百分比。该百分比应该是0%,高了则说明有外部碎片。
Avg. Bytes Free per Page-每页上的平均可用字节数:所扫描的页上的平均可用字节数。越高说明有内部碎片,不过在你用这个数字决定是否有内部碎片之前,应该考虑fill factor(填充因子)。
Avg. Page Density (full)-平均页密度(完整):每页上的平均可用字节数的百分比的相反数。低的百分比说明有内部碎片
函数sys.dm_db_index_physical_stats查询碎片
返回SQL Server中指定表或视图的数据和索引的大小和碎片信息。 对于索引,针对每个分区中的 B 树的每个级别,返回与其对应的一行。 对于堆,针对每个分区的 IN_ROW_DATA 分配单元,返回与其对应的一行。 对于大型对象 (LOB) 数据,针对每个分区的 LOB_DATA 分配单元返回与其对应的一行。 如果表中存在行溢出数据,则针对每个分区中的 ROW_OVERFLOW_DATA 分配单元,返回与其对应的一行。 不返回有关 xVelocity 内存优化的列存储索引的信息。
在对表进而对表中定义的索引进行数据修改(INSERT、UPDATE 和 DELETE 语句)的整个过程中都会出现碎片。 由于这些修改通常并不在表和索引的行中平均分布,所以每页的填充度会随时间而改变。 对于扫描表的部分或全部索引的查询,这种碎片会导致额外的页读取。 这会妨碍数据的并行扫描。
索引或堆的碎片级别显示在 avg_fragmentation_in_percent 列中。 对于堆,此值表示堆的区碎片。 对于索引,此值表示索引的逻辑碎片。 与 DBCC SHOWCONTIG 不同,这两种情况下的碎片计算算法都会考虑跨越多个文件的存储,因而结果是精确的。
为了获得最佳性能,avg_fragmentation_in_percent 的值应尽可能接近零。 但是,从 0 到 10% 范围内的值都可以接受。 所有减少碎片的方法(例如重新生成、重新组织或重新创建)都可用于降低这些值。 有关如何分析索引中碎片程度的详细信息,请参阅 重新组织和重新生成索引。
语法
1 2 3 4 5 6 7 | sys.dm_db_index_physical_stats ( { database_id | NULL | 0 | DEFAULT } , { object_id | NULL | 0 | DEFAULT } , { index_id | NULL | 0 | -1 | DEFAULT } , { partition_number | NULL | 0 | DEFAULT } , { mode | NULL | DEFAULT } ) |
参数
database_id |NULL |0 |默认
数据库的 ID。 database_id 为 smallint。 有效的输入包括数据库的 ID 号、NULL、0 或 DEFAULT。 默认值为 0。 在此上下文中,NULL、0 和 DEFAULT 是等效值。
指定 NULL 可返回 SQL Server 实例中所有数据库的信息。 如果为 database_id指定 NULL,则还必须为 object_id、 index_id和 partition_number指定 NULL。
可以指定内置函数 DB_ID。 如果在不指定数据库名称的情况下使用 DB_ID,则当前数据库的兼容级别必须是 90 或更高。
object_id |NULL |0 |默认
索引所针对的表或视图的对象 ID。 object_id 为 int。
有效的输入包括表和视图的 ID 号、NULL、0 或 DEFAULT。 默认值为 0。 在此上下文中,NULL、0 和 DEFAULT 是等效值。 从 2016 (13.x) SQL Server 起,有效输入还包括 Service Broker 队列名称或队列内部表名称。 当 (所有对象、所有索引等) 应用默认参数时,所有队列的碎片信息将包含在结果集中。
指定 NULL 可返回指定数据库中的所有表和视图的信息。 如果为 object_id指定 NULL,则还必须为 index_id 和 partition_number指定 NULL。
index_id |0 |NULL |-1 |默认
索引的 ID。 index_id 为 int。有效输入是索引的 ID 号;如果 object_id 为堆、NULL、-1 或 DEFAULT,则为 0。 默认值为 -1。 NULL、-1 和 DEFAULT 是此上下文中的等效值。
指定 NULL 可返回基表或视图的所有索引的信息。 如果为 index_id指定 NULL,则还必须为 partition_number指定 NULL。
partition_number |NULL |0 |默认
对象中的分区号。 partition_number 为 int。有效输入是索引或堆 的partion_number 、NULL、0 或 DEFAULT。 默认值为 0。 在此上下文中,NULL、0 和 DEFAULT 是等效值。
指定 NULL,以返回有关所属对象的所有分区的信息。
partition_number 从 1 开始。 非分区索引或堆 partition_number 设置为 1。
模式 |NULL |默认
模式的名称。 mode 指定用于获取统计信息的扫描级别。 mode 为 sysname。 有效输入为 DEFAULT、NULL、LIMITED、SAMPLED 或 DETAILED。 默认值 (NULL) 为 LIMITED。
返回的表
| 列名 | 数据类型 | 说明 |
|---|---|---|
| database_id | smallint | 表或视图的数据库 ID。 |
| object_id | int | 索引所在的表或视图的对象 ID。 |
| index_id | int | 索引的索引 ID。0 = 堆。 |
| partition_number | int | 所属对象内从 1 开始的分区号;表、视图或索引。1 = 未分区的索引或堆。 |
| index_type_desc | nvarchar(60) | 索引类型的说明:HEAPCLUSTERED INDEXNONCLUSTERED INDEXPRIMARY XML INDEXSPATIAL INDEXXML INDEX |
| alloc_unit_type_desc | nvarchar(60) | 对分配单元类型的说明:IN_ROW_DATALOB_DATAROW_OVERFLOW_DATALOB_DATA 分配单元包含类型为 text、ntext、image、varchar(max)、nvarchar(max)、varbinary(max) 和 xml 的列中所存储的数据。有关详细信息,请参阅数据类型 (Transact-SQL)。ROW_OVERFLOW_DATA 分配单元包含类型为 varchar(n)、nvarchar(n)、varbinary(n) 和 sql_variant 的列(已推送到行外)中所存储的数据。有关详细信息,请参阅行溢出数据超过 8 KB。 |
| index_depth | tinyint | 索引级别数。1 = 堆,或 LOB_DATA 或 ROW_OVERFLOW_DATA 分配单元。 |
| index_level | tinyint | 索引的当前级别。0 表示索引叶级别、堆以及 LOB_DATA 或 ROW_OVERFLOW_DATA 分配单元。大于 0 的值表示非叶索引级别。index_level 在索引的根级别中属于最高级别。仅当 mode = DETAILED 时才处理非叶级别的索引。 |
| avg_fragmentation_in_percent | float | 索引的逻辑碎片,或 IN_ROW_DATA 分配单元中堆的区碎片。此值按百分比计算,并将考虑多个文件。有关逻辑碎片和区碎片的定义,请参阅“备注”。0 表示 LOB_DATA 和 ROW_OVERFLOW_DATA 分配单元。对于堆,当 mode 为 SAMPLED 时,为 NULL。 |
| fragment_count | bigint | IN_ROW_DATA 分配单元的叶级别中的碎片数。有关碎片的详细信息,请参阅“备注”。对于索引的非叶级别,以及 LOB_DATA 或 ROW_OVERFLOW_DATA 分配单元,为 NULL。对于堆,当 mode 为 SAMPLED 时,为 NULL。 |
| avg_fragment_size_in_pages | float | IN_ROW_DATA 分配单元的叶级别中的一个碎片的平均页数。对于索引的非叶级别,以及 LOB_DATA 或 ROW_OVERFLOW_DATA 分配单元,为 NULL。对于堆,当 mode 为 SAMPLED 时,为 NULL。 |
| page_count | bigint | 索引或数据页的总数。对于索引,表示 IN_ROW_DATA 分配单元中 b 树的当前级别中的索引页总数。对于堆,表示 IN_ROW_DATA 分配单元中的数据页总数。对于 LOB_DATA 或 ROW_OVERFLOW_DATA 分配单元,表示该分配单元中的总页数。 |
| avg_page_space_used_in_percent | float | 所有页中使用的可用数据存储空间的平均百分比。对于索引,平均百分比应用于 IN_ROW_DATA 分配单元中 b 树的当前级别。对于堆,表示 IN_ROW_DATA 分配单元中所有数据页的平均百分比。对于 LOB_DATA 或 ROW_OVERFLOW DATA 分配单元,表示该分配单元中所有页的平均百分比。当 mode 为 LIMITED 时,为 NULL。 |
| record_count | bigint | 总记录数。对于索引,记录的总数应用于 IN_ROW_DATA 分配单元中 b 树的当前级别。对于堆,表示 IN_ROW_DATA 分配单元中的总记录数。 注意对于堆,此函数返回的记录数可能与通过对堆运行 SELECT COUNT(*) 返回的行数不匹配。这是因为一行可能包含多个记录。例如,在某些更新情况下,单个堆行可能由于更新操作而包含一条前推记录和一条被前推记录。此外,多数大型 LOB 行在 LOB_DATA 存储中拆分为多个记录。对于 LOB_DATA 或 ROW_OVERFLOW_DATA 分配单元,表示整个分配单元中总记录数。当 mode 为 LIMITED 时,为 NULL。 注意对于堆,此函数返回的记录数可能与通过对堆运行 SELECT COUNT(*) 返回的行数不匹配。这是因为一行可能包含多个记录。例如,在某些更新情况下,单个堆行可能由于更新操作而包含一条前推记录和一条被前推记录。此外,多数大型 LOB 行在 LOB_DATA 存储中拆分为多个记录。对于 LOB_DATA 或 ROW_OVERFLOW_DATA 分配单元,表示整个分配单元中总记录数。当 mode 为 LIMITED 时,为 NULL。 |
| ghost_record_count | bigint | 分配单元中将被虚影清除任务删除的虚影记录数。对于 IN_ROW_DATA 分配单元中索引的非叶级别,为 0。当 mode 为 LIMITED 时,为 NULL。 |
| version_ghost_record_count | bigint | 由分配单元中未完成的快照隔离事务保留的虚影记录数。对于 IN_ROW_DATA 分配单元中索引的非叶级别,为 0。当 mode 为 LIMITED 时,为 NULL。 |
| min_record_size_in_bytes | int | 最小记录大小(字节)。对于索引,最小记录大小应用于 IN_ROW_DATA 分配单元中 b 树的当前级别。对于堆,表示 IN_ROW_DATA 分配单元中的最小记录大小。对于 LOB_DATA 或 ROW_OVERFLOW_DATA 分配单元,表示整个分配单元中的最小记录大小。当 mode 为 LIMITED 时,为 NULL。 |
| max_record_size_in_bytes | int | 最大记录大小(字节)。对于索引,最大记录的大小应用于 IN_ROW_DATA 分配单元中 b 树的当前级别。对于堆,表示 IN_ROW_DATA 分配单元中的最大记录大小。对于 LOB_DATA 或 ROW_OVERFLOW_DATA 分配单元,表示整个分配单元中的最大记录大小。当 mode 为 LIMITED 时,为 NULL。 |
| avg_record_size_in_bytes | float | 平均记录大小(字节)。对于索引,平均记录大小应用于 IN_ROW_DATA 分配单元中 b 树的当前级别。对于堆,表示 IN_ROW_DATA 分配单元中的平均记录大小。对于 LOB_DATA 或 ROW_OVERFLOW_DATA 分配单元,表示整个分配单元中的平均记录大小。当 mode 为 LIMITED 时,为 NULL。 |
| forwarded_record_count | bigint | 堆中具有指向另一个数据位置的转向指针的记录数。(在更新过程中,如果在原始位置存储新行的空间不足,将会出现此状态。)除 IN_ROW_DATA 分配单元外,对于堆的其他所有分配单元都为 NULL。当 mode = LIMITED 时,对于堆为 NULL。 |
| compressed_page_count | bigint | 压缩页的数目。对于堆,新分配的页未进行 PAGE 压缩。堆在以下两种特殊情况下进行 PAGE 压缩:大量导入数据时和重新生成堆时。导致页分配的典型 DML 操作不会进行 PAGE 压缩。当 compressed_page_count 值增长到超过您所需的阈值时,将重新生成堆。对于具有聚集索引的表,compressed_page_count 值表示 PAGE 压缩的效率。 |
如何减少索引中的碎片
当索引分段的方式导致碎片影响查询性能时,有三种方法可减少碎片:
删除并重新创建聚集索引。
重新创建聚集索引将对数据进行重新分布,从而使数据页填满。 填充度可以使用 CREATE INDEX 中的 FILLFACTOR 选项进行配置。 这种方法的缺点是索引在删除和重新创建周期内为脱机状态,并且操作属原子级。 如果中断索引创建,则不能重新创建索引。 有关详细信息,请参阅 CREATE INDEX (Transact-SQL)。
使用 ALTER INDEX REORGANIZE(代替 DBCC INDEXDEFRAG)按逻辑顺序重新排序索引的叶级页。 由于这是联机操作,因此在语句运行时仍可使用索引。 中断此操作时不会丢失已经完成的任务。 此方法的缺点是在重新组织数据方面不如索引重新生成操作的效果好,而且不更新统计信息。
使用 ALTER INDEX REBUILD(代替 DBCC DBREINDEX)联机或脱机重新生成索引。 有关详细信息,请参阅 ALTER INDEX (Transact-SQL)。
不需要仅因为碎片的原因而重新组织或重新生成索引。 碎片的主要影响是,在索引扫描过程中会降低页的预读吞吐量。 这将导致响应时间变长。 如果含有碎片的表或索引中的查询工作负荷不涉及扫描(因为工作负荷主要是单独查找),则删除碎片可能不起作用。
备注
如果在收缩操作中对索引进行部分或完全移动,则运行 DBCC SHRINKFILE 或 DBCC SHRINKDATABASE 可能产生碎片。 因此,如果必须执行收缩操作,则应在删除碎片之前进行。
1 2 3 4 | dbcc dbreindex ([customer],'',90) 第一个参数是要重建索引的表名,必选,第二个参数指定索引名称,空着就表示所有,第三个参数叫填充因子,是指索引页的数据填充程度,0表示使用先前的值,100表示每个索引页都填满,这时查询效率最高,但插入索引时会移动其它索引,可根据实际情况来设置。 |
SQL Server表和索引信息查询
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | -- 表信息 exec sp_spaceused N'BigTable'; exec sp_helpindex N'bigtable'; exec sp_help N'bigtable'; -- 表大小 SELECT TOP 10 t.NAME AS TableName, s.Name AS SchemaName, p.rows AS RowCounts, CAST(ROUND(((SUM(a.total_pages) * 8) / 1024.00), 2) AS NUMERIC(36, 2)) AS TotalSpaceMB, CAST(ROUND(((SUM(a.used_pages) * 8) / 1024.00), 2) AS NUMERIC(36, 2)) AS UsedSpaceMB, CAST(ROUND(((SUM(a.total_pages) - SUM(a.used_pages)) * 8) / 1024.00, 2) AS NUMERIC(36, 2)) AS UnusedSpaceMB FROM sys.tables t INNER JOIN sys.indexes i ON t.OBJECT_ID = i.object_id INNER JOIN sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id INNER JOIN sys.allocation_units a ON p.partition_id = a.container_id LEFT OUTER JOIN sys.schemas s ON t.schema_id = s.schema_id GROUP BY t.Name, s.Name, p.Rows ORDER BY SUM(a.total_pages) desc; -- 表行数 SELECT a.name,b.rows FROM sysobjects a WITH (NOLOCK) JOIN sysindexes b WITH (NOLOCK) ON b.id = a.id WHERE a.xtype = 'U' AND b.indid IN ( 0, 1 ) ORDER BY b.rows DESC; -- 索引大小 SELECT t.name AS TableName, i.name AS IndexName, SUM(s.used_page_count) * 8 AS IndexSizeKB FROM sys.indexes AS i INNER JOIN sys.tables AS t ON i.[object_id] = t.[object_id] INNER JOIN sys.dm_db_partition_stats AS s ON i.[object_id] = s.[object_id] AND i.index_id = s.index_id WHERE i.name IS NOT NULL AND t.is_ms_shipped = 0 AND s.used_page_count > 0 and t.name='BigTable' -- and i.name='idx1' GROUP BY t.name, i.name ORDER BY t.name, i.name; |
索引碎片相关SQL总结
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 | -- 返回所有数据库的信息 SELECT * FROM sys.dm_db_index_physical_stats (NULL, NULL, NULL, NULL, NULL); -- 返回当前数据库的信息 SELECT * FROM sys.dm_db_index_physical_stats (db_id(), NULL, NULL, NULL, NULL); -- 返回当前数据库的T表的信息 SELECT * FROM sys.dm_db_index_physical_stats (db_id(), object_id('T'), NULL, NULL, NULL) AS ips; -- 数据库中碎片率大于30%的所有索引 SELECT db_name() dbname, OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name, OBJECT_NAME(ips.object_id) AS tb_name, i.name AS index_name, i.type_desc AS index_type, CAST(ips.avg_fragmentation_in_percent AS DECIMAL(5, 2)) avg_fragmentation_in_percent, -- 索引碎片总计百分比,大于30%就得重建 CAST(ips.avg_page_space_used_in_percent AS DECIMAL(5, 2)) avg_page_space_used_in_percent, -- 索引页填充度,小于70%就得重建 ips.index_depth, ips.page_count, ips.fragment_count, ips.alloc_unit_type_desc, 'ALTER INDEX '+ i.name +' ON '+ OBJECT_NAME(ips.object_id) +' REBUILD WITH (MAXDOP=16);' index_rebuild, 'ALTER INDEX ALL ON '+ OBJECT_NAME(ips.object_id) +' REBUILD WITH (MAXDOP=16);' all_index_rebuild FROM ( select * from sys.dm_db_index_physical_stats(db_id(), null, NULL, NULL, NULL ) a where a.index_level=0 and alloc_unit_type_desc='IN_ROW_DATA' )AS ips LEFT JOIN sys.indexes AS i ON (ips.object_id = i.object_id AND ips.index_id = i.index_id and ips.index_level=0) where i.name is not null and ips.avg_fragmentation_in_percent > 30 ORDER BY page_count DESC; -- 查看某个具体索引的信息 SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name, OBJECT_NAME(ips.object_id) AS object_name, i.name AS index_name, i.type_desc AS index_type, ips.avg_fragmentation_in_percent, ips.avg_page_space_used_in_percent, ips.page_count, ips.alloc_unit_type_desc FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips INNER JOIN sys.indexes AS i ON ips.object_id = i.object_id AND ips.index_id = i.index_id and i.name='idx' ORDER BY page_count DESC; -- 检查行存储索引的碎片和页面密度 SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name, OBJECT_NAME(ips.object_id) AS object_name, i.name AS index_name, i.type_desc AS index_type, ips.avg_fragmentation_in_percent, ips.avg_page_space_used_in_percent, ips.page_count, ips.alloc_unit_type_desc FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips INNER JOIN sys.indexes AS i ON ips.object_id = i.object_id AND ips.index_id = i.index_id ORDER BY page_count DESC; -- 检查列存储索引的碎片的具体步骤 SELECT OBJECT_SCHEMA_NAME(i.object_id) AS schema_name, OBJECT_NAME(i.object_id) AS object_name, i.name AS index_name, i.type_desc AS index_type, 100.0 * (ISNULL(SUM(rgs.deleted_rows), 0)) / NULLIF(SUM(rgs.total_rows), 0) AS avg_fragmentation_in_percent FROM sys.indexes AS i INNER JOIN sys.dm_db_column_store_row_group_physical_stats AS rgs ON i.object_id = rgs.object_id AND i.index_id = rgs.index_id WHERE rgs.state_desc = 'COMPRESSED' GROUP BY i.object_id, i.index_id, i.name, i.type_desc ORDER BY schema_name, object_name, index_name, index_type; -- 重新组织 ALTER INDEX IX_Employee_OrganizationalLevel_OrganizationalNode ON hr.Employee REORGANIZE; ALTER INDEX ALL ON HumanResources.Employee REORGANIZE; -- 重建索引 ALTER INDEX PK_Employee_BusinessEntityID ON hr.Employee REBUILD WITH (MAXDOP=16); ALTER INDEX ALL ON hr.Product REBUILD ; -- 生成索引重建sql SELECT distinct concat('ALTER INDEX ALL ON ', OBJECT_NAME(ind.OBJECT_ID),' REORGANIZE - GO-') AS ReIndex FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) indexstats INNER JOIN sys.indexes ind ON ind.object_id = indexstats.object_id AND ind.index_id = indexstats.index_id WHERE indexstats.avg_fragmentation_in_percent > 30 ; |
SQL Server自动索引和统计信息管理(usp_AdaptiveIndexDefrag)
https://github.com/microsoft/tigertoolbox/tree/master/AdaptiveIndexDefrag


