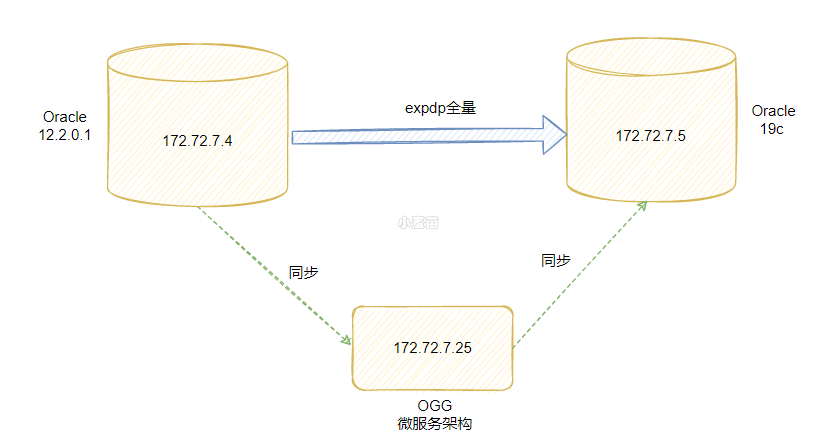
合 数据库数据迁移完成后完整性的校验
Tags: 数据迁移
- Oracle 数据库
- DBMS_COMPARISION简介:
- DBMS_COMPARISION限制:
- DBms_comparison不支持的数据类型:
- 1. PL/SQL Developer 工具使用
- SQL Server数据库
- 1.准备两个要比较的数据库
- 2.连接源数据库和目标数据库
- 3.比较源数据库和目标数据库
- 4.更新目标数据库
- 设置数据源
- 表结构对比
- 数据对比
- tablediff.exe
- tablediff.exe,这个工具就用于表内部数据比较,是MS SQL Server自带的一个工具。各位可以自行搜索自己机器上的这个文件所在的路径。
- 三、构建数据表比较SQL语句:
- 1、选择要比较的数据库,点“Compare Now”进行比较
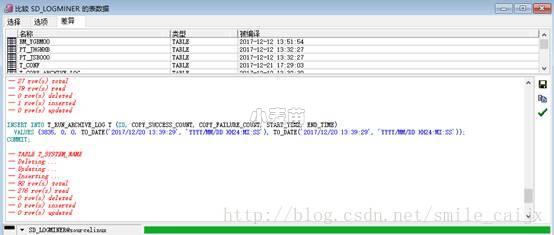
- 2、对比两个数据库之间的差异,选择要同步的东西。红框出是对比窗口,可以看到两个数据库之间的差异
- 3、同步数据库中的对象,点“Synchronization Wizard”
- 4、开始同步,因为一直按“下一步”,这里只上图,不在说明步骤。
- 第一步。打开SQL Server → 菜单栏 → 工具 → SQL Compare
- 第二步。SQL Compare → Help → Enter Serial Number
- 第三步。从Keygen获取序列号
- 第四步。输入序列号
- 第五步。点击Activate(注册),注意要先断网,等待一会会提示网络错误
- 第六步。 点击Activate Manually(离线注册)
- 第七步。把代码复制到注册机中间的文本框内生成相应的代码
- 第八步。把生成的代码复制到右边的文本框中,然后点击Finish(完成)
- 附上成功后的About截图。
- MySQL数据库
数据库数据验证是指对迁移后数据库数据的一致性进行验证。
数据库的迁移大体上可以分为物理全量迁移、物理增量迁移、逻辑全量迁移和逻辑增量迁移。其中,针对数据库物理全量迁移来说,迁移前的源库和迁移后的目标库肯定是一致的。因为物理全量迁移是基于物理文件的冷备迁移,不存在数据的变动,所以,数据库的一致性可以得到保证。
物理冷备全量迁移(例如rman全备、冷备等方式),数据肯定是一致的。
数据校验主要是针对增量迁移和逻辑迁移来说的。
增量迁移对Oracle来说,若增量点不一致,则不能恢复,所以一般也不会丢失数据。
但是,针对MSSQL从阿里云到华为云做增量恢复碰到过一次数据丢失的情况。
逻辑迁移要有严格的步骤,步骤不报错,基本数据也不丢失。
不过,客户肯定不认啥物理迁移,逻辑迁移、增量还是全量迁移的,只要数据迁移前后数据比对的一个结果。
所以,我们可以从以下几个方面来比对
1,从数据库对象方面上来判断、鉴别
- 从总数量上来进行判断,看迁移前后,表、视图、存储过程、存储函数、触发器等用户对象的 总数量 能否和源库对应上。
- 然后 , 再 对各个 表的总记录数做一个count 操作,来比对行数 。
- 最后,对于视图、存储过程、函数等内容,可以将其DDL语句导出成txt可读文件,再通过文本比对工具进行比对即可。
2,从业务上来判断,把应用程序跑起来,进应用程序界面上,跑一整套流程下来,看看是否正常
3、 对数据库表内容进行比对,一般使用工具或脚本进行比对。
- Oracle数据库:dbms_comparison包、minus相减法、dbms_utility.get_hash_value计算hash值、 PL/SQL Developer 工具等
- SQL Server数据库:Visual Studio工具即SQL Server Data Tools (SSDT)、SQLDiff或tablediff.exe工具针对单表比对、Red Gate的SQL Compare工具,需要注意: 对于 SSDT工具来说,需要对比的2个库都必须有主键或唯一键才能进行比对
- MySQL数据库:用mysqldiff+mysqldbcompare工具
Oracle 数据库
在开发过程中,遇到了需要比对两个数据库是否完全一致。通过PL/SQL可以为我们提供很好的帮助。
方式1:使用 \dbms_comparison包****
官方文档:
DBMS_COMPARISION简介:
这个软件包是oracle提供的可以再两个数据之间做object是比对。并且呢如果在比对过程中如果源端数据和目标端数据不一致,那么可以选择是从源端在将数据复制到目标端,还是从目标端在复制到源端,最终达到数据一致性的结果。该包也是通过创建dblink来实现的。这个工具的使用大体分为四步:
第一步:使用create_compare去创建一个比对动作
第二步:使用compare函数去进行数据对象之间的比对
第三步:我们在去查看比对结果,相应的record会记录到不同视图中如下:
DBA_COMPARISON_SCAN
USER_COMPARISON_SCAN
DBA_COMPARISON_SCAN_VALUES
USER_COMPARISON_SCAN_VALUES
DBA_COMPARISON_ROW_DIF
USER_COMPARISON_ROW_DIF
第四不:如果数据不一致,那么可以使用convert去将数据同步
大家可能会说,如果我进行了两次数据比对,那么如何区分呢,这就是oracle自己会给你设计一个标示了。这个函数是recheck。后续介绍:
还有一个问题,那就是这个包能做哪些数据比对?
答案是:对表、视图、物化视图、同义词等
DBMS_COMPARISION限制:
当然了任何一个工具都有自己的限制,那么这个包呢?
1、对于源端数据库版本必须是高于11.1,对于目标端数据库版本必须高于10.1
2.对于所有比对的数据库对象,必须是共享对象,也就是说每个对象的列个数和列的类型必须一致。如果列不一致,那么需要将比对的列使用column_list做个列表。
Database objects of different types can be compared and converged at different databases. For example, a table at one database and a materialized view at another database can be compared and converged with this package.
以上是说了比较容易理解的限制,下面在说一下索引列的限制:
1、在全库比对模式下,必须要有一个在 number, timestamp, interval, or DATE 数据类型的单一索引列,或是仅仅有一个包括这几种数据类型的复合索引,但是这个复合索引中设计到的列必须都是not null或是其中一列是一个主键列。
2、
For the scan modes CMP_SCAN_MODE_FULL and CMP_SCAN_MODE_CUSTOM to be supported, the database objects must have one of the following types of indexes:
- A single-column index on a number, timestamp, interval,
DATE,VARCHAR2, orCHARdata type column - A composite index that only includes number, timestamp, interval,
DATE,VARCHAR2, orCHARcolumns. Each column in the composite index must either have aNOTNULLconstraint or be part of the primary key.
如果数据库没有满足这些要求,那么这个包将无法进行数据比对。
if the database objects have only one index, and it is a composite index that includes a NUMBER column and an NCHAR column, then the DBMS_COMPARISON package does not support them.
If these constraints are not present on a table, then use the index_schema_name and index_name parameters in the CREATE_COMPARISONprocedure to specify an index whose columns satisfy this requirement.
When a single index value identifies both a local row and a remote row, the two rows must be copies of the same row in the replicated tables. In addition, each pair of copies of the same row must always have the same index value.
DBms_comparison不支持的数据类型:
LONG、LANG RAW、ROWID、urowid、clob、nclob、blob、bfile另外还有如下两种:
1、udt(user-defined types,including object types, REFs, varrays, and nested tables)
2、oracle-supplied type (including any types, XML types, spatial types, and media types)
假设你所要进行数据比对的数据库其中有一个版本为11g且该表上有相应的主键索引(primary key index)或者唯一非空索引(unique key ¬ null)的话,那么恭喜你! 你可以借助11g 新引入的专门做数据对比的PL/SQL Package dbms_comparison来实现数据校验的目的,如以下演示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | Source 源端版本为11gR2 : conn maclean/maclean SQL> select * from v$version; BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit Production PL/SQL Release 11.2.0.3.0 - Production CORE 11.2.0.3.0 Production TNS for Linux: Version 11.2.0.3.0 - Production NLSRTL Version 11.2.0.3.0 - Production SQL> select * from global_name; GLOBAL_NAME -------------------------------------------------------------------------------- drop table test1; create table test1 tablespace users as select object_id t1,object_name t2 from dba_objects where object_id is not null; alter table test1 add primary key(t1); exec dbms_stats.gather_table_stats('MACLEAN','TEST1',cascade=>TRUE); create database link maclean connect to maclean identified by maclean using 'G10R21'; Database link created. |
以上源端数据库版本为11.2.0.3 , 源表结构为test1(t1 number primary key,t2 varchar2(128),透过dblink链接到版本为10.2.0.1的目标端
1 2 3 4 5 6 7 8 9 10 11 12 13 | conn maclean/maclean SQL> select * from v$version BANNER ---------------------------------------------------------------- Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - 64bi PL/SQL Release 10.2.0.1.0 - Production CORE 10.2.0.1.0 Production TNS for Linux: Version 10.2.0.1.0 - Production NLSRTL Version 10.2.0.1.0 - Production create table test2 tablespace users as select object_id t1,object_name t2 from dba_objects where object_id is not null; alter table test2 add primary key(t1); exec dbms_stats.gather_table_stats('MACLEAN','TEST2',cascade=>TRUE); |
目标端版本为10.2.0.1 , 表结构为test2(t1 number primary key,t2 varchar2(128))。
注意这里2张表上均必须有相同的主键索引或者伪主键索引(pseudoprimary key伪主键要求是唯一键且所有的成员列均是非空NOT NULL)。
实际创建comparison对象,并实施校验:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | begin dbms_comparison.create_comparison(comparison_name => 'MACLEAN_TEST_COM', schema_name => 'MACLEAN', object_name => 'TEST1', dblink_name => 'MACLEAN', remote_schema_name => 'MACLEAN', remote_object_name => 'TEST2', scan_mode => dbms_comparison.CMP_SCAN_MODE_FULL); end; PL/SQL procedure successfully completed. SQL> set linesize 80 pagesize 1400 SQL> select * from user_comparison where comparison_name='MACLEAN_TEST_COM'; COMPARISON_NAME COMPA SCHEMA_NAME ------------------------------ ----- ------------------------------ OBJECT_NAME OBJECT_TYPE REMOTE_SCHEMA_NAME ------------------------------ ----------------- ------------------------------ REMOTE_OBJECT_NAME REMOTE_OBJECT_TYP ------------------------------ ----------------- DBLINK_NAME -------------------------------------------------------------------------------- SCAN_MODE SCAN_PERCENT --------- ------------ CYCLIC_INDEX_VALUE -------------------------------------------------------------------------------- NULL_VALUE -------------------------------------------------------------------------------- LOCAL_CONVERGE_TAG -------------------------------------------------------------------------------- REMOTE_CONVERGE_TAG -------------------------------------------------------------------------------- MAX_NUM_BUCKETS MIN_ROWS_IN_BUCKET --------------- ------------------ LAST_UPDATE_TIME --------------------------------------------------------------------------- MACLEAN_TEST_COM TABLE MACLEAN TEST1 TABLE MACLEAN TEST2 TABLE MACLEAN FULL ORA$STREAMS$NV 1000 10000 20-DEC-11 01.08.44.562092 PM |
利用dbms_comparison.create_comparison创建comparison后,新建的comparison会出现在user_comparison视图中;
以上我们完成了comparison的创建,但实际的校验仍未发生我们利用10046事件监控这个数据对比过程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 | conn maclean/maclean set timing on; alter system flush shared_pool; alter session set events '10046 trace name context forever,level 8'; set serveroutput on DECLARE retval dbms_comparison.comparison_type; BEGIN IF dbms_comparison.compare('MACLEAN_TEST_COM', retval, perform_row_dif => TRUE) THEN dbms_output.put_line('No Differences'); ELSE dbms_output.put_line('Differences Found'); END IF; END; / Differences Found =====> 返回结果为Differences Found,说明数据存在差异并不一致 PL/SQL procedure successfully completed. Elapsed: 00:00:10.87 ===========================10046 tkprof result ========================= SELECT MIN("T1"), MAX("T1") FROM "MACLEAN"."TEST1" SELECT MIN("T1"), MAX("T1") FROM "MACLEAN"."TEST2"@MACLEAN SELECT COUNT(1) FROM "MACLEAN"."TEST1" s WHERE ("T1" >= :scan_min AND "T1" <= :scan_max ) SELECT COUNT(1) FROM "MACLEAN"."TEST2"@MACLEAN s WHERE ("T1" >= :scan_min AND "T1" <= :scan_max ) SELECT q.wb1, min(q."T1") min_range1, max(q."T1") max_range1, count(*) num_rows, sum(q.s_hash) sum_range_hash FROM (SELECT /*+ FULL(s) */ width_bucket(s."T1", :scan_min1, :scan_max_inc1, :num_buckets) wb1, s."T1", ora_hash(NVL(to_char(s."T1"), 'ORA$STREAMS$NV'), 4294967295, ora_hash(NVL((s."T2"), 'ORA$STREAMS$NV'), 4294967295, 0)) s_hash FROM "MACLEAN"."TEST1" s WHERE (s."T1">=:scan_min1 AND s."T1"<= :scan_max1) ) q GROUP BY q.wb1 ORDER BY q.wb1 SELECT /*+ REMOTE_MAPPED */ q.wb1, min(q."T1") min_range1, max(q."T1") max_range1, count(*) num_rows, sum(q.s_hash) sum_range_hash FROM (SELECT /*+ FULL(s) REMOTE_MAPPED */ width_bucket(s."T1", :scan_min1, :scan_max_inc1, :num_buckets) wb1, s."T1", ora_hash(NVL(to_char(s."T1"), 'ORA$STREAMS$NV'), 4294967295, ora_hash(NVL((s."T2"), 'ORA$STREAMS$NV'), 4294967295, 0)) s_hash FROM "MACLEAN"."TEST2"@MACLEAN s WHERE (s."T1">= :scan_min1 AND s."T1"<=:scan_max1) ) q GROUP BY q.wb1 ORDER BY q.wb1 SELECT /*+ FULL(P) +*/ * FROM "MACLEAN"."TEST2" P SELECT /*+ FULL ("A1") */ WIDTH_BUCKET("A1"."T1", :SCAN_MIN1, :SCAN_MAX_INC1, :NUM_BUCKETS), MIN("A1"."T1"), MAX("A1"."T1"), COUNT(*), SUM(ORA_HASH(NVL(TO_CHAR("A1"."T1"), 'ORA$STREAMS$NV'), 4294967295, ORA_HASH(NVL("A1"."T2", 'ORA$STREAMS$NV'), 4294967295, 0))) FROM "MACLEAN"."TEST2" "A1" WHERE "A1"."T1" >= :SCAN_MIN1 AND "A1"."T1" <= :SCAN_MAX1 GROUP BY WIDTH_BUCKET("A1"."T1", :SCAN_MIN1, :SCAN_MAX_INC1, :NUM_BUCKETS) ORDER BY WIDTH_BUCKET("A1"."T1", :SCAN_MIN1, :SCAN_MAX_INC1, :NUM_BUCKETS) SELECT ROWID, "T1", "T2" FROM "MACLEAN"."TEST2" "R" WHERE "T1" >= :1 AND "T1" <= :2 -------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 126 | 3528 | 4 (0)| 00:00:01 | |* 1 | FILTER | | | | | | | 2 | TABLE ACCESS BY INDEX ROWID| TEST2 | 126 | 3528 | 4 (0)| 00:00:01 | |* 3 | INDEX RANGE SCAN | SYS_C006255 | 227 | | 2 (0)| 00:00:01 | -------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter(TO_NUMBER(:1)<=TO_NUMBER(:2)) 3 - access("T1">=TO_NUMBER(:1) AND "T1"<=TO_NUMBER(:2)) SELECT ll.l_rowid, rr.r_rowid, NVL(ll."T1", rr."T1") idx_val FROM (SELECT l.rowid l_rowid, l."T1", ora_hash(NVL(to_char(l."T1"), 'ORA$STREAMS$NV'), 4294967295, ora_hash(NVL((l."T2"), 'ORA$STREAMS$NV'), 4294967295, 0)) l_hash FROM "MACLEAN"."TEST1" l WHERE l."T1">=:scan_min1 AND l."T1"<=:scan_max1 ) ll FULL OUTER JOIN (SELECT /*+ NO_MERGE REMOTE_MAPPED */ r.rowid r_rowid, r."T1", ora_hash(NVL(to_char(r."T1"), 'ORA$STREAMS$NV'), 4294967295, ora_hash(NVL((r."T2"), 'ORA$STREAMS$NV'), 4294967295, 0)) r_hash FROM "MACLEAN"."TEST2"@MACLEAN r WHERE r."T1">= :scan_min1 AND r."T1"<=:scan_max1 ) rr ON ll."T1"=rr."T1" WHERE ll.l_hash IS NULL OR rr.r_hash IS NULL OR ll.l_hash <> rr.r_hash ---------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Inst |IN-OUT| ---------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 190 | 754K| 9 (12)| 00:00:01 | | | |* 1 | VIEW | VW_FOJ_0 | 190 | 754K| 9 (12)| 00:00:01 | | | |* 2 | HASH JOIN FULL OUTER | | 190 | 754K| 9 (12)| 00:00:01 | | | | 3 | VIEW | | 190 | 7220 | 4 (0)| 00:00:01 | | | |* 4 | FILTER | | | | | | | | | 5 | TABLE ACCESS BY INDEX ROWID| TEST1 | 190 | 5510 | 4 (0)| 00:00:01 | | | |* 6 | INDEX RANGE SCAN | SYS_C0013098 | 341 | | 2 (0)| 00:00:01 | | | | 7 | VIEW | | 126 | 495K| 4 (0)| 00:00:01 | | | | 8 | REMOTE | TEST2 | 126 | 3528 | 4 (0)| 00:00:01 | MACLE~ | R->S | ---------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("LL"."L_HASH" IS NULL OR "RR"."R_HASH" IS NULL OR "LL"."L_HASH"<>"RR"."R_HASH") 2 - access("LL"."T1"="RR"."T1") 4 - filter(TO_NUMBER(:SCAN_MIN1)<=TO_NUMBER(:SCAN_MAX1)) 6 - access("L"."T1">=TO_NUMBER(:SCAN_MIN1) AND "L"."T1"<=TO_NUMBER(:SCAN_MAX1)) Remote SQL Information (identified by operation id): ---------------------------------------------------- 8 - SELECT ROWID,"T1","T2" FROM "MACLEAN"."TEST2" "R" WHERE "T1">=:1 AND "T1"<=:2 (accessing 'MACLEAN' ) |
可以看到以上过程中虽然没有避免对TEST1、TEST2表的全表扫描(FULL TABLE SCAN), 但是好在实际参与HASH JOIN FULL OUTER 的仅是访问索引后获得的少量数据,所以效率还是挺高的。
此外可以通过user_comparison_row_dif了解实际那些row存在差异,如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | SQL> set linesize 80 pagesize 1400 SQL> select * 2 from user_comparison_row_dif 3 where comparison_name = 'MACLEAN_TEST_COM' 4 and rownum < 2; COMPARISON_NAME SCAN_ID LOCAL_ROWID REMOTE_ROWID ------------------------------ ---------- ------------------ ------------------ INDEX_VALUE -------------------------------------------------------------------------------- STA LAST_UPDATE_TIME --- --------------------------------------------------------------------------- MACLEAN_TEST_COM 42 AAATWGAAEAAANBrAAB AAANJrAAEAAB8AMAAd 46 DIF 20-DEC-11 01.18.08.917257 PM |
以上利用dbms_comparison包完成了一次简单的数据比对,该方法适用于11g以上版本且要求表上有主键索引或非空唯一索引, 且不支持以下数据类型字段的比对
- LONG
- LONG RAW
- ROWID
- UROWID
- CLOB
- NCLOB
- BLOB
- BFILE
- User-defined types (including object types, REFs, varrays, and nested tables)
- Oracle-supplied types (including any types, XML types, spatial types, and media types)
若要比对存有以上类型字段的表,那么需要在create_comparison时指定column_list参数排除掉这些类型的字段。
方法1 dbms_comparison的优势在于可以提供详细的比较信息,且在有适当索引的前提下效率较高。
缺点在于有数据库版本的要求(at least 11gR1), 且也不支持LONG 、CLOB等字段的比较。
1 | Oracle11g中引入了一个新的PL/SQL包DBMS_COMPARISON,可以比较不同数据库下或者schame``下的对象/``schema``/数据,并且可以根据规则将不同的数据进行同步。这在进行数据的分布时``将十分的有用,例如你的数据复制过程中出现问题,导致源数据和目标数据出现不一致,则``可以借用该特性进行处理。如果你的系统中该安装包,可以通过以下方法安装:``1、以sys身份登入数据库``2、执行dbmscmp.sql``可以利用DBMS_COMPARISON来执行比较的对象有:``表``基于单个表的视图``物化视图``以上三种对象的同义词``下面通过一个实验来体验这个新功能:``-----------------------------------------------------------------------------------------------``1.建立用户并授权``create` `user` `test1 identified ``by` `tiger;``create` `user` `test2 identified ``by` `tiger;``grant` `dba ``to` `test1,test2;``2.建立表并插入数据``create` `table` `stu``(`` ``stuno number ``not` `null``,`` ``stuname varchar2(20),`` ``classno varchar2(5) ``);``alter` `table` `stu ``add` `constraint` `pk_stu ``primary` `key``(stuno);`` ` `insert` `into` `stu ``values``(1,``'tom'``,``'c5'``);``insert` `into` `stu ``values``(2,``'jack'``,``'c2'``);``insert` `into` `stu ``values``(3,``'jim'``,``'c3'``);``insert` `into` `stu ``values``(4,``'lily'``,``'c1'``);``commit``;``select` `* ``from` `stu;``3.利用create_comparison建立比较任务(前提是比较对象上有指定的索引)``begin``dbms_comparison.create_comparison(comparison_name=>``'COMPTEST'``,`` ``schema_name=>``'TEST1'``,`` ``object_name=>``'stu'``,`` ``dblink_name=>``NULL``,`` ``remote_schema_name=>``'TEST2'``,`` ``remote_object_name=>``'stu'``);``end``;``/``由于比较的都是在本地库,所以dblink_name设置为``NULL``。如果另外一个对象在远程库,则``远程库的版本只要在10R1版本以上即可。当然两个库的字符集必须一致。两个要比较的表的``列数如果不相同,则必须使用column_list参数列出两个对象中都存在的列进行比较。否则``会报以下错误:``ORA-23625: TEST1.TESTCOMP1 和 TEST2.TESTCOMP2@ 的表形式不匹配。``ORA-06512: 在 “SYS.DBMS_COMPARISON”, line 4197``ORA-06512: 在 “SYS.DBMS_COMPARISON”, line 420``ORA-06512: 在 line 2``要对对象进行比较,需要对象上有以下一种索引的存在:``基于数字类型(NUMBER | ``FLOAT` `| BINARY_FLOAT | BINARY_DOUBLE),``timestamp``类型``(``TIMESTAMP` `| ``TIMESTAMP` `WITH` `TIME` `ZONE | ``and` `TIMESTAMP` `WITH` `LOCAL` `TIME` `ZONE),或``者Interval类型(INTERVAL ``YEAR` `TO` `MONTH` `| INTERVAL ``DAY` `TO` `SECOND``)或者``DATE``类型的单``列索引。``只包含上述类型列的复合索引,并且其中每个列要么有``NOT` `NULL``约束,要么是主键的一部分``。``如果比较时的扫描模式选择的是CMP_SCAN_MODE_FULL或者CMP_SCAN_MODE_CUSTOM,索引可以``放宽条件,除了上面说的列类型,也可以包含VARCHAR2或者``CHAR``列。``目前还只能支持常规列类型的比较,对于LONG | LONG RAW | ROWID | UROWID | CLOB |``NCLOB | BLOB | BFILE | TYPE(包括用户自定义和Oracle预定义的类型)类型的列都还不能``进行较。``如果违反上述条件,欲比较的对象上缺乏所需要的索引的话,则会收到以下错误:``ORA-23626: 表 TEST1.TEST 上没有符合要求的索引``ORA-06512: 在 “SYS.DBMS_COMPARISON”, line 4197``ORA-06512: 在 “SYS.DBMS_COMPARISON”, line 420``ORA-06512: 在 line 2``4.执行compare过程进行比较(得到scan_id)``set` `serveroutput ``on``declare``compare_info dbms_comparison.comparison_type;``compare_return boolean;``begin``compare_return := dbms_comparison.compare (comparison_name=>``'COMPTEST'``,``scan_info=>compare_info,``perform_row_dif=>``TRUE``);``if compare_return=``TRUE``then``dbms_output.put_line(``'the tables are equivalent.'``);``else``dbms_output.put_line(``'Bad news... there is data divergence.'``);``dbms_output.put_line(``'Check the dba_comparison and dba_comparison_scan_summary``views for locate the differences for scan_id:'``||compare_info.scan_id);``end` `if;``end``;``/``5.根据得到的scan_id查询执行的结果:``查询以下视图获得比较结果``DBA_COMPARISON``USER_COMPARISON``DBA_COMPARISON_COLUMNS``USER_COMPARISON_COLUMNS``DBA_COMPARISON_SCAN``USER_COMPARISON_SCAN``DBA_COMPARISON_SCAN_SUMMARY``USER_COMPARISON_SCAN_SUMMARY``DBA_COMPARISON_SCAN_VALUES``USER_COMPARISON_SCAN_VALUES``DBA_COMPARISON_ROW_DIF``USER_COMPARISON_ROW_DIF``我们来看看比较的结果:``select` `a.owner, a.comparison_name, a.schema_name,``a.object_name,z.current_dif_count difference``from` `dba_comparison a, dba_comparison_scan_summary z``where` `a.comparison_name=z.comparison_name``and` `a.owner=z.owner ``and` `z.scan_id=24;``OWNER COMPARISON_NAME SCHEMA_NAME OBJECT_NAME DIFFERENCE``----- --------------- ------------- ------------- ---------``TEST1 COMPTEST TEST1 STU 3``查找不同的数据``select` `local_rowid,remote_rowid,status ``from` `dba_comparison_row_dif ``where``comparison_name=``'COMPTEST'``;``LOCAL_ROWID REMOTE_ROWID STATUS``------------------ ------------------ ------``AAAS6OAAEAAAAK9AAA AAAS6IAAEAAAAKLAAB DIF``AAAS6OAAEAAAAK9AAC AAAS6IAAEAAAAKPAAC DIF``AAAS6OAAEAAAAK9AAD AAAS6IAAEAAAAKPAAD DIF``6.根据scan_id执行converge函数进行会聚``假设我们需要使用test2.stu的数据优先覆盖test1.stu的数据,也就是远程优先``declare``compare_info dbms_comparison.comparison_type;``begin``dbms_comparison.converge (comparison_name=>``'COMPTEST'``,``scan_id=>24,``scan_info=>compare_info,``converge_options=>dbms_comparison.cmp_converge_remote_wins);``dbms_output.put_line(``'--- Results ---'``);``dbms_output.put_line(``'Local rows Merged by process: '``||``compare_info.loc_rows_merged);``dbms_output.put_line(``'Remote rows Merged by process: '``||``compare_info.rmt_rows_merged);``dbms_output.put_line(``'Local rows Deleted by process: '``||``compare_info.loc_rows_deleted);``dbms_output.put_line(``'Remote rows Deleted by process: '``||``compare_info.rmt_rows_deleted);``end``;``/``执行结果:``— Results —``Local` `rows` `Merged ``by` `process: 3``Remote ``rows` `Merged ``by` `process: 0``Local` `rows` `Deleted ``by` `process: 3``Remote ``rows` `Deleted ``by` `process: 0``7.使用recheck函数重新执行比较``declare``compare_return boolean;``begin``compare_return := dbms_comparison.recheck``(comparison_name=>``'COMPTEST'``,scan_id=>24);``if compare_return=``TRUE``then``dbms_output.put_line(``'the tables are equivalent.'``);``else``dbms_output.put_line(``'Bad news... there is data divergence.'``);``end` `if;``end``;``/``由于已经同步,则比较结果是两个对象的数据是相同的,the tables are equivalent.``8.使用purge_comparison过程清除比较结果``EXEC` `dbms_comparison.purge_comparison(``'COMPTEST'``)``或者``begin``dbms_comparison.purge_comparison(comparison_name=>``'COMPTEST'``);``end``;``/``9.使用drop_comparison过程删除比较任务``EXEC` `dbms_comparison.drop_comparison(``'COMPTEST'``)``或者``begin``dbms_comparison.drop_comparison(comparison_name=>``'COMPTEST'``);``end``;``/``至此整个实验做完。 |
方式2:
利用minus Query 对比数据
这可以说是操作上最简单的一种方法,如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | select * from test1 minus select * from test2@maclean; ----------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | Inst |IN-OUT| ----------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 75816 | 3527K| | 1163 (40)| 00:00:14 | | | | 1 | MINUS | | | | | | | | | | 2 | SORT UNIQUE | | 75816 | 2147K| 2984K| 710 (1)| 00:00:09 | | | | 3 | TABLE ACCESS FULL| TEST1 | 75816 | 2147K| | 104 (1)| 00:00:02 | | | | 4 | SORT UNIQUE | | 50467 | 1379K| 1800K| 453 (1)| 00:00:06 | | | | 5 | REMOTE | TEST2 | 50467 | 1379K| | 56 (0)| 00:00:01 | MACLE~ | R->S | ----------------------------------------------------------------------------------------------------- Remote SQL Information (identified by operation id): ---------------------------------------------------- 5 - SELECT "T1","T2" FROM "TEST2" "TEST2" (accessing 'MACLEAN' ) Select * from (select 'MACLEAN.TEST1' "Row Source", a.* from (select /*+ FULL(Tbl1) */ T1, T2 from MACLEAN.TEST1 Tbl1 minus select /*+ FULL(Tbl2) */ T1, T2 from MACLEAN.TEST2@"MACLEAN" Tbl2) A union all select 'MACLEAN.TEST2@"MACLEAN"', b.* from (select /*+ FULL(Tbl2) */ T1, T2 from MACLEAN.TEST2@"MACLEAN" Tbl2 minus select /*+ FULL(Tbl1) */ T1, T2 from MACLEAN.TEST1 Tbl1) B) Order by 1; |
MINUS Clause会导致2张表均在本地被全表扫描(TABLE FULL SCAN),且要求发生SORT排序。 若所对比的表上有大量的数据,那么排序的代价将会是非常大的, 因此这种方法的效率不高。
方式2 MINUS的优点在于操作简便,特别适合于小表之间的数据检验。
缺点在于 由于SORT排序可能导致在大数据量的情况下效率很低, 且同样不支持LOB 和 LONG 这样的大对象。
查询2个表之间的不同:
1 | (``select` `* ``from` `lhrc1.stu minus ``select` `* ``from` `lhrc2.stu)``union` `all``(``select` `* ``from` `lhrc2.stu minus ``select` `* ``from` `lhrc1.stu); |
方式3:
使用not exists子句,如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | select * from test1 a where not exists (select 1 from test2 b where a.t1 = b.t1 and a.t2 = b.t2); no rows selected Elapsed: 00:00:00.06 ------------------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | ------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 75816 | 7996K| | 691 (1)| 00:00:09 | |* 1 | HASH JOIN ANTI | | 75816 | 7996K| 3040K| 691 (1)| 00:00:09 | | 2 | TABLE ACCESS FULL| TEST1 | 75816 | 2147K| | 104 (1)| 00:00:02 | | 3 | TABLE ACCESS FULL| TEST2 | 77512 | 5979K| | 104 (1)| 00:00:02 | ------------------------------------------------------------------------------------ Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("A"."T1"="B"."T1" AND "A"."T2"="B"."T2") |
照理说在数据量较大的情况下not exists使用的HASH JOIN ANTI是在性能上是优于MINUS操作的, 但是当所要比较的表身处不同的2个数据库(distributed query)时将无法使用HASH JOIN ANTI,而会使用FILTER OPERATION这种效率极低的操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | select * from test1 a where not exists (select 1 from test2@maclean b where a.t1 = b.t1 and a.t2 = b.t2) no rows selected Elapsed: 00:01:05.76 -------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Inst |IN-OUT| -------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 75816 | 2147K| 147K (1)| 00:29:31 | | | |* 1 | FILTER | | | | | | | | | 2 | TABLE ACCESS FULL| TEST1 | 75816 | 2147K| 104 (1)| 00:00:02 | | | | 3 | REMOTE | TEST2 | 1 | 29 | 2 (0)| 00:00:01 | MACLE~ | R->S | -------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter( NOT EXISTS (SELECT 0 FROM "B" WHERE "B"."T1"=:B1 AND "B"."T2"=:B2)) Remote SQL Information (identified by operation id): ---------------------------------------------------- 3 - SELECT "T1","T2" FROM "TEST2" "B" WHERE "T1"=:1 AND "T2"=:2 (accessing 'MACLEAN' ) |
可以从以上执行计划看到FILTER 操作是十分昂贵的。
补充:
有网友反映可以通过增加 unnest hint 让CBO优化器在远程子查询有效的情况下整体考虑整个查询块,这样可以让执行计划用上HASH JOIN RIGHT ANTI, 这是我一开始没有考虑到的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | select * from test1 a where not exists (select /*+ unnset */ 1 from test2@maclean b where a.t1 = b.t1 and a.t2 = b.t2); PLAN_TABLE_OUTPUT ------------------------------------------ Plan hash value: 1776635653 ------------------------------------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | Inst |IN-OUT| ------------------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 79815 | 12M| | 594 (1)| 00:00:08 | | | |* 1 | HASH JOIN RIGHT ANTI| | 79815 | 12M| 1816K| 594 (1)| 00:00:08 | | | | 2 | REMOTE | TEST2 | 20420 | 1575K| | 56 (0)| 00:00:01 | MACLE~ | R->S | | 3 | TABLE ACCESS FULL | TEST1 | 79815 | 6157K| | 104 (1)| 00:00:02 | | | ------------------------------------------------------------------------------------------------------ Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("A"."T1"="B"."T1" AND "A"."T2"="B"."T2") Remote SQL Information (identified by operation id): ---------------------------------------------------- 2 - SELECT "T1","T2" FROM "TEST2" "B" (accessing 'MACLEAN' ) |
在此基础上加入ordered hint 可以让执行计划使用HASH JOIN ANTI
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | select /*+ ordered */ * from test1 a where not exists (select /*+ unnset */ 1 from test2@maclean b where a.t1 = b.t1 and a.t2 = b.t2); PLAN_TABLE_OUTPUT -------------------------------------------------- Plan hash value: 3089912131 ---------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | Inst |IN-OUT| ---------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 79815 | 12M| | 594 (1)| 00:00:08 | | | |* 1 | HASH JOIN ANTI | | 79815 | 12M| 7096K| 594 (1)| 00:00:08 | | | | 2 | TABLE ACCESS FULL| TEST1 | 79815 | 6157K| | 104 (1)| 00:00:02 | | | | 3 | REMOTE | TEST2 | 20420 | 1575K| | 56 (0)| 00:00:01 | MACLE~ | R->S | ---------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("A"."T1"="B"."T1" AND "A"."T2"="B"."T2") Remote SQL Information (identified by operation id): ---------------------------------------------------- 3 - SELECT "T1","T2" FROM "TEST2" "B" (accessing 'MACLEAN' ) |
方式3 的优点在于操作简便, 且当需要对比的表位于同一数据库时效率要比MINUS方式高,但如果是distributed query分布式查询则效率可能会因FILTER操作而急剧下降,这时候需要我们手动添加unnest这样的SQL提示,以保证执行计划使用HASH JOIN ANTI操作,这样能够保证not exists方式的性能。not exists同样不支持CLOB等大对象。
方式4:
Toad、PL/SQL Developer等图形化工具都提供了compare table data的功能, 这里我们以Toad工具为例,介绍如何使用该工具校验数据:
打开Toad 链接数据库-> 点击Database-> Compare -> Data

分别在Source 1和Source 2对话框中输入源表和目标表的信息
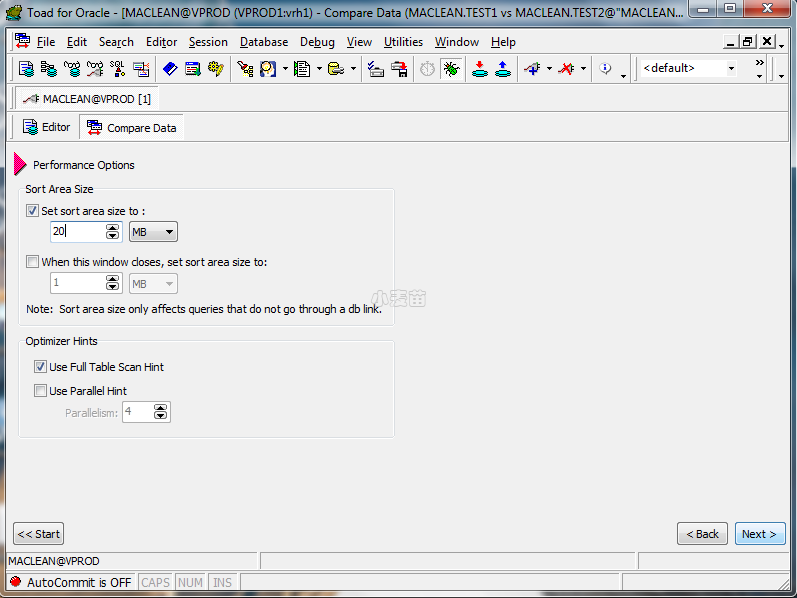
因为Toad的底层实际上使用了MINUS操作,所以提高SORT_AREA_SIZE有助于提高compare的性能,若使用AUTO PGA则可以不设置。
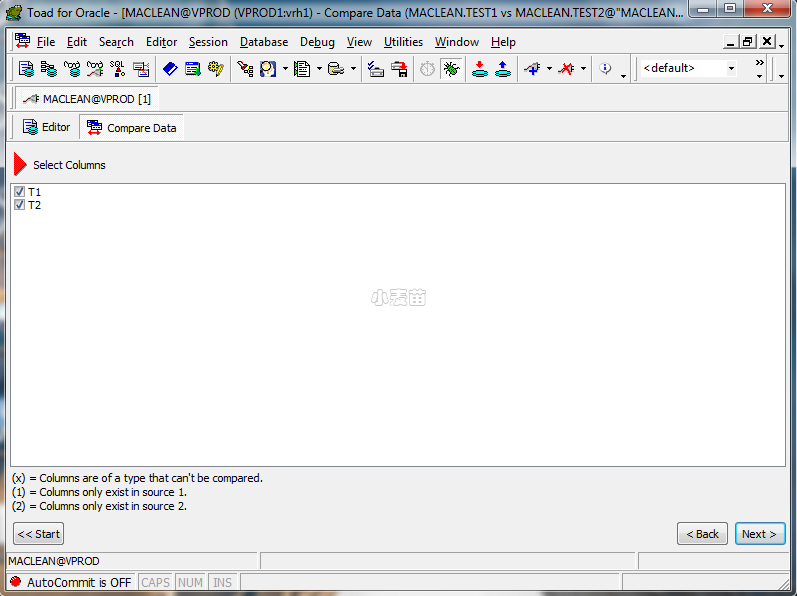
选择所要比较的列
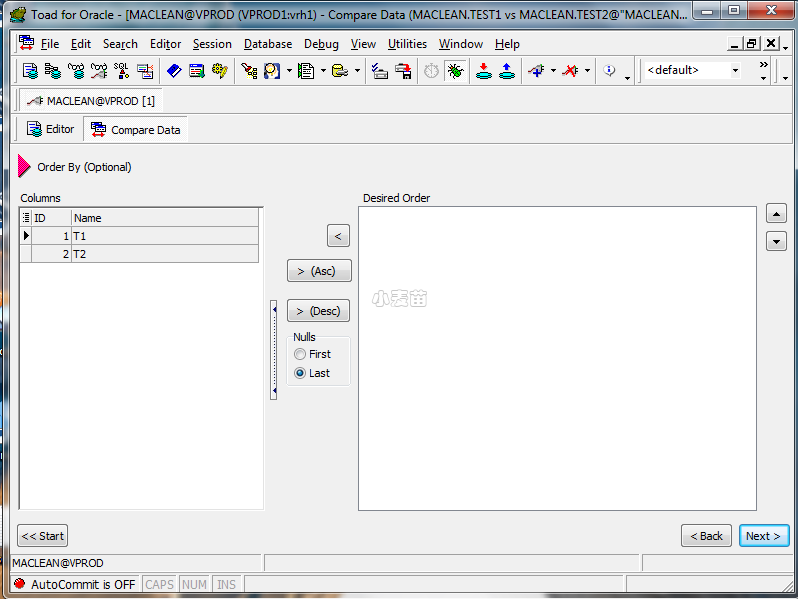
首先可以比较2张表的行数,点击Execute计算count
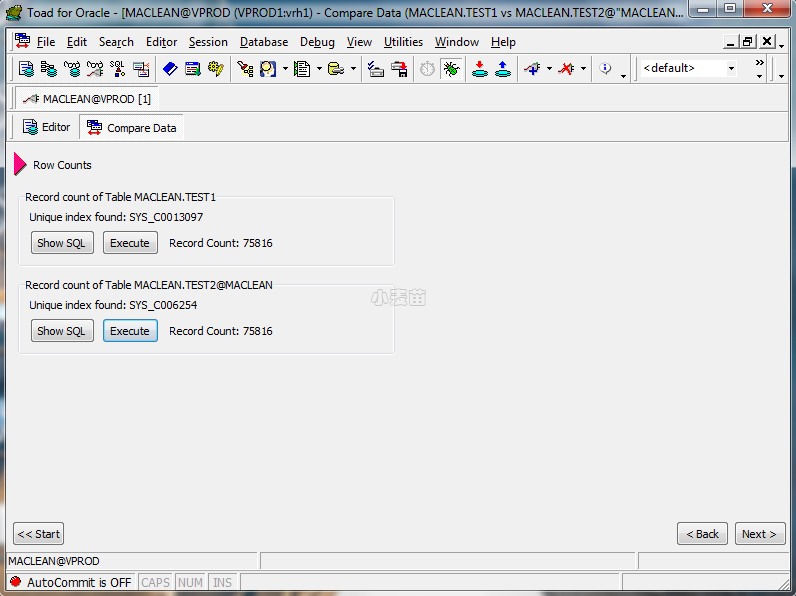
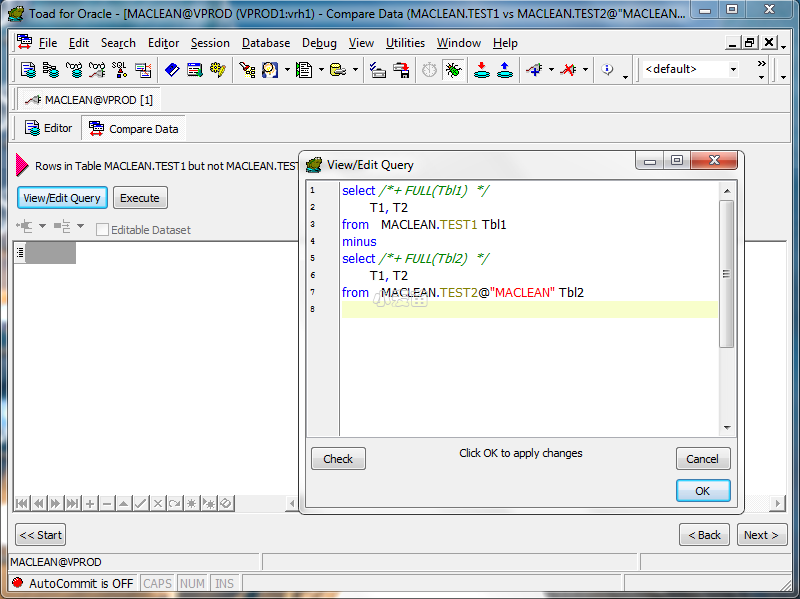
使用MINUS 找出其中一张表上有,而另一张没有的行
使用MINUS 找出所有的差别
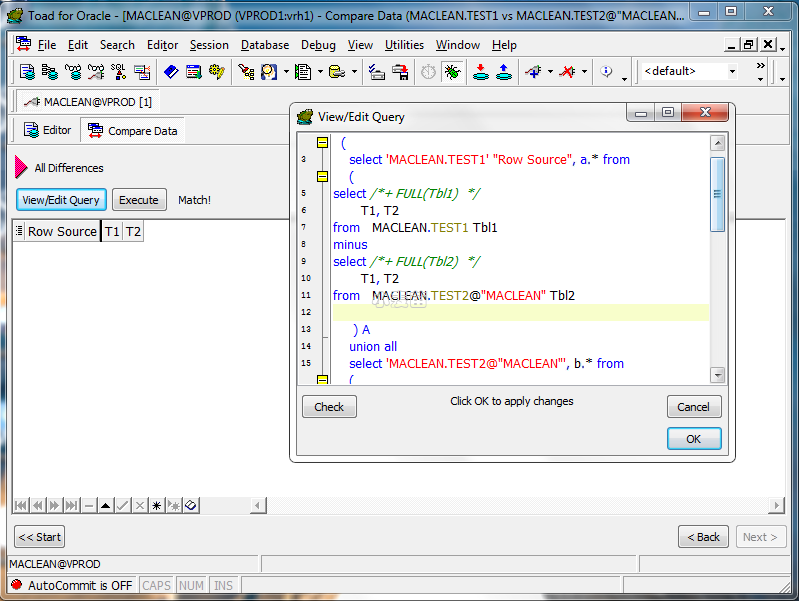
Toad的compare data功能是基于MINUS实现的,所以效率上并没有优势。但是通过图形界面省去了写SQL语句的麻烦。这种方法同样不支持LOB、LONG等对象。
1. PL/SQL Developer 工具使用
PLSQL Developer Tools菜单下有Compare User Objects和Compare Table Data功能。
① Tools –> compare user objects
该功能用于比较不同用户所拥有的对象(包括table、sequence、function、procedure、view等),并生成同步差异的sql脚本,用户通过执行该脚本,可保持两个用户的对象结构的同步,当然你也可以选择一个对象或者多个对象来进行比较。
操作步骤:
\1. 选择样本库的对比对象
\2. 选择目标库(Target Session..),即需修改和被同步的库
\3. 点击Compare按钮
\4. 在Differences选项卡,点击每个对象能查看消除差异的SQL,点击Apply SQL in Target Session执行
\5. 点击Show Differences按钮,显示具体区别
② Tools –> compare table data
该功能用于比较某些个表里面的数据是否一致,并自动生成同步差异的sql脚本,用户通过执行该脚本,就可以保持比较对象与被比较对象里面数据的同步。
操作步骤:
\1. 选择样本库的对比表
\2. 选择目标库(Target Session..),即需修改和被同步的库
\3. 点击Compare按钮
\4. 在Differences选项卡,点击每个表能查看消除差异的SQL
\5. 点击Apply SQL in Target Session执行
注: 主键相同值的记录做更新(Update)其他字段。
- 登录数据库A
- 打开【工具】菜单下的【比较用户对象】
- 点【目标会话】,登录数据库B
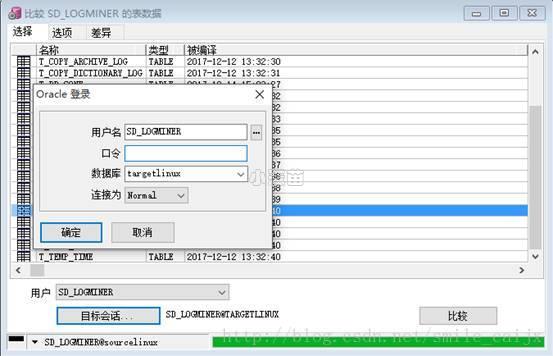
- 点击【比较】
- 切换到【差异】面板可以看到不同的对象以及更新语句
- 同理,我们也可以通过【比较表数据】来查看两库表数据的不同。
- 如果要将两库的表结构或者表数据进行同步的话,则拷贝出脚本并执行。
注意以下几种数据比对方式适用的前提条件:
\1. 所要比对的表的结构是一致的
\2. 比对过程中源端和 目标端 表上的数据都是静态的,没有任何DML修改
方式5:
这是一种别出心裁的做法。 将一行数据的上所有字段合并起来,并使用dbms_utility.get_hash_value对合并后的中间值取hash value,再将所有这些从各行所获得的hash值sum累加, 若2表的hash累加值相等则判定2表的数据一致。
简单来说,如下面这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | create table hash_one as select object_id t1,object_name t2 from dba_objects; select dbms_utility.get_hash_value(t1||t2,0,power(2,30)) from hash_one where rownum <3; DBMS_UTILITY.GET_HASH_VALUE(T1||T2,0,POWER(2,30)) ------------------------------------------------- 89209477 757190129 select sum(dbms_utility.get_hash_value(t1||t2,0,power(2,30))) from hash_one; SUM(DBMS_UTILITY.GET_HASH_VALU ------------------------------ 40683165992756 select sum(dbms_utility.get_hash_value(object_id||object_name,0,power(2,30))) from dba_objects; SUM(DBMS_UTILITY.GET_HASH_VALU ------------------------------ 40683165992756 |
对于列较多的表,手动去构造所有字段合并可能会比较麻烦,利用以下SQL可以快速构造出我们所需要的语句:
1 2 3 4 5 6 | 放到PL/SQL Developer等工具中运行,在sqlplus 中可能因ORA-00923: FROM keyword not found where expected出错 select 'select sum(dbms_utility.get_hash_value('||column_name_path||',0,power(2,30)) ) from '||owner||'.'||table_name||';' from (select owner,table_name,column_name_path,row_number() over(partition by table_name order by table_name,curr_level desc) column_name_path_rank from (select owner,table_name,column_name,rank,level as curr_level,ltrim(sys_connect_by_path(column_name,'||''|''||'),'||''|''||') column_name_path from (select owner,table_name,column_name,row_number() over(partition by table_name order by table_name,column_name) rank from dba_tab_columns where owner=UPPER('&OWNER') and table_name=UPPER('&TABNAME') order by table_name,column_name) connect by table_name = prior table_name and rank-1 = prior rank)) where column_name_path_rank=1; |
使用示范:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | SQL> @get_hash_col Enter value for owner: SYS Enter value for tabname: TAB$ 'SELECTSUM(DBMS_UTILITY.GET_HASH_VALUE('||COLUMN_NAME_PATH||',0,POWER(2,30)))FROM -------------------------------------------------------------------------------- select sum(dbms_utility.get_hash_value(ANALYZETIME||'|'||AUDIT$||'|'||AVGRLN||'| '||AVGSPC||'|'||AVGSPC_FLB||'|'||BLKCNT||'|'||BLOCK#||'|'||BOBJ#||'|'||CHNCNT||' |'||CLUCOLS||'|'||COLS||'|'||DATAOBJ#||'|'||DEGREE||'|'||EMPCNT||'|'||FILE#||'|' ||FLAGS||'|'||FLBCNT||'|'||INITRANS||'|'||INSTANCES||'|'||INTCOLS||'|'||KERNELCO LS||'|'||MAXTRANS||'|'||OBJ#||'|'||PCTFREE$||'|'||PCTUSED$||'|'||PROPERTY||'|'|| ROWCNT||'|'||SAMPLESIZE||'|'||SPARE1||'|'||SPARE2||'|'||SPARE3||'|'||SPARE4||'|' ||SPARE5||'|'||SPARE6||'|'||TAB#||'|'||TRIGFLAG||'|'||TS#,0,1073741824) ) from S YS.TAB$; 利用以上生成的SQL 计算表的sum(hash)值 select sum(dbms_utility.get_hash_value(ANALYZETIME || '|' || AUDIT$ || '|' || AVGRLN || '|' || AVGSPC || '|' || AVGSPC_FLB || '|' || BLKCNT || '|' || BLOCK# || '|' || BOBJ# || '|' || CHNCNT || '|' || CLUCOLS || '|' || COLS || '|' || DATAOBJ# || '|' || DEGREE || '|' || EMPCNT || '|' || FILE# || '|' || FLAGS || '|' || FLBCNT || '|' || INITRANS || '|' || INSTANCES || '|' || INTCOLS || '|' || KERNELCOLS || '|' || MAXTRANS || '|' || OBJ# || '|' || PCTFREE$ || '|' || PCTUSED$ || '|' || PROPERTY || '|' || ROWCNT || '|' || SAMPLESIZE || '|' || SPARE1 || '|' || SPARE2 || '|' || SPARE3 || '|' || SPARE4 || '|' || SPARE5 || '|' || SPARE6 || '|' || TAB# || '|' || TRIGFLAG || '|' || TS#, 0, 1073741824)) from SYS.TAB$; SUM(DBMS_UTILITY.GET_HASH_VALU ------------------------------ 1646389632463 |
方式5 利用累加整行数据的hash来判定表上数据是否一致, 仅需要对2张表做全表扫描,效率上是这几种方法中最高的, 且能保证较高的准确率。
但是该hash方式存在以下几点不足:
\1. 所有字段合并的整行数据可能超过4000字节,这时会出现ORA-1498错误。换而言之使用这种方式的前提是表中任一行的行长不能超过4000 bytes,当然常规情况下很少会有一行数据超过4000 bytes,也可以通过dba_tables.avg_row_len平均行长的统计信息来判定,若avg_row_len<<4000 那么一般不会有溢出的问题。
\2. 该hash 方式仅能帮助判断 数据是否一致, 而无法提供更多有用的,例如是哪些行不一致等细节信息
\3. 同样的该hash方式对于lob、long字段也无能为力
SQL Server数据库
可以使用微软提供的专用数据库比对工具:Visual Studio 2017 (SSDT) --
SQL Server Data Tools (SSDT)
1.准备两个要比较的数据库
我这里有两个数据库,一个是本地的(JXPT_CS),一个是测试服务器的(JXPT_MS)。本次演练我将连接这两个数据库。
2.连接源数据库和目标数据库
所谓的源数据库和目标数据库也就是字面的意思(源>目标)将源数据中新增修改删除的数据同步到目标数据库中。
首先我们打开VS>工具>SQL Server>新建数据比较。
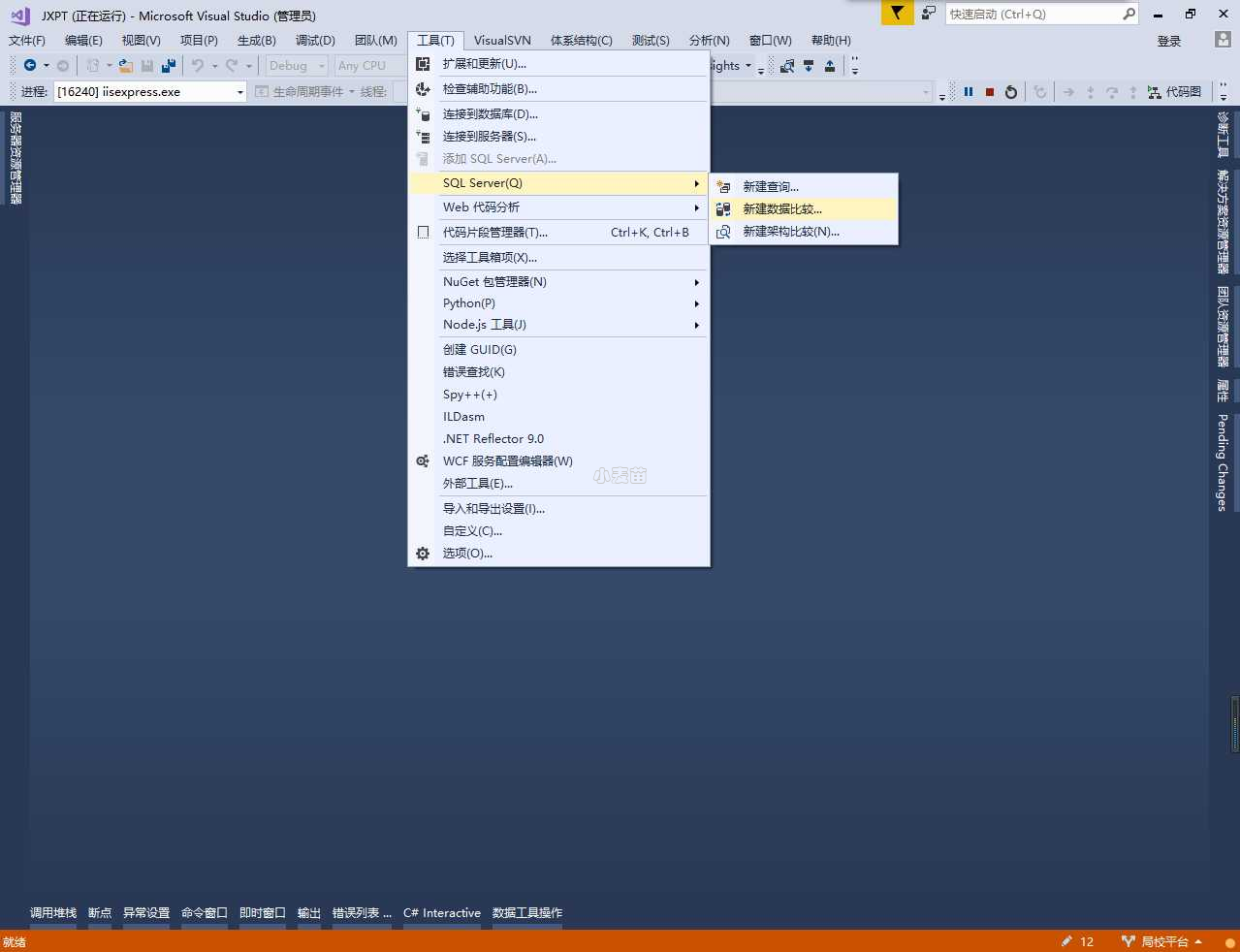
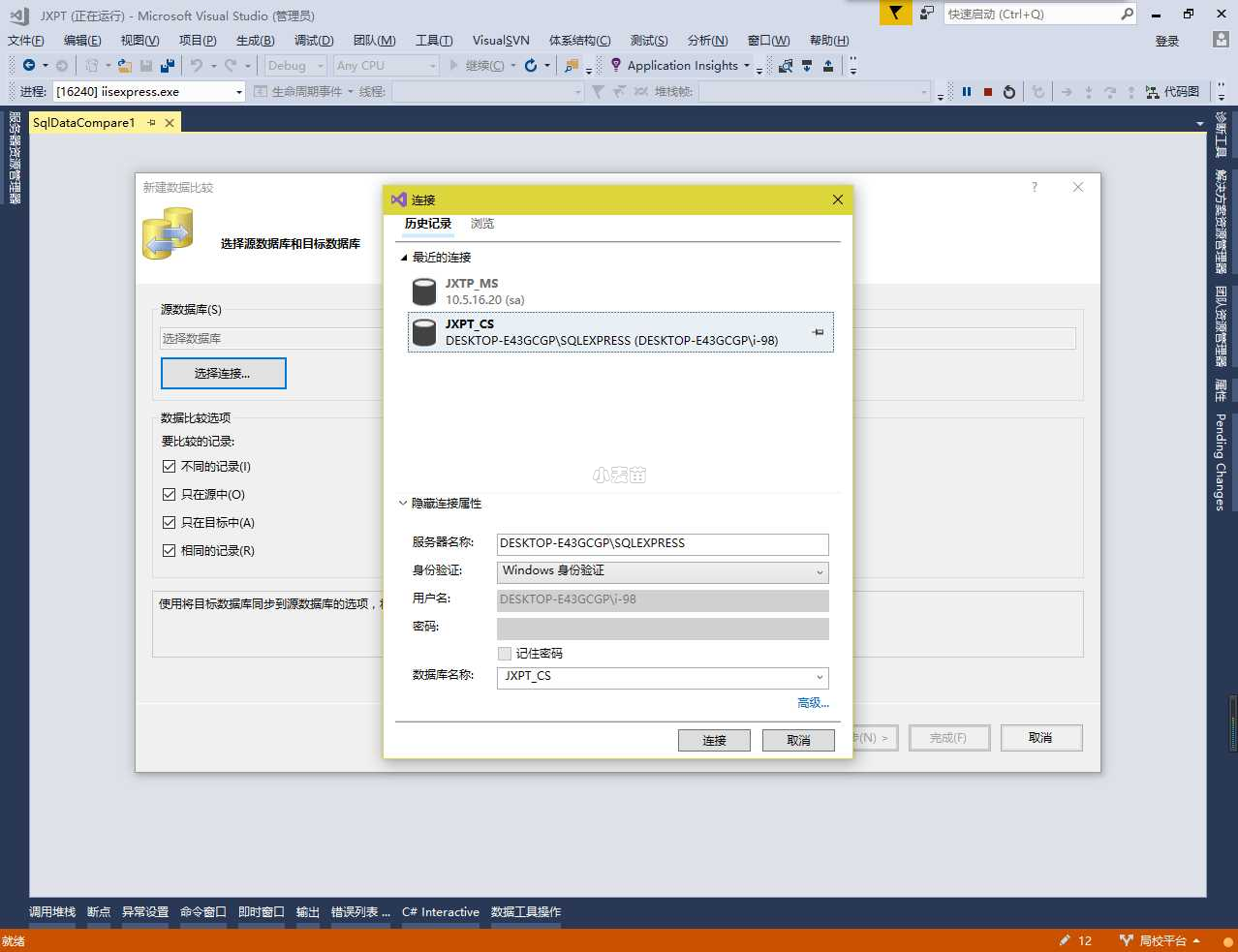
选择源数据库

我们选择数据库,点击连接
选择目标 操作和选择源一样
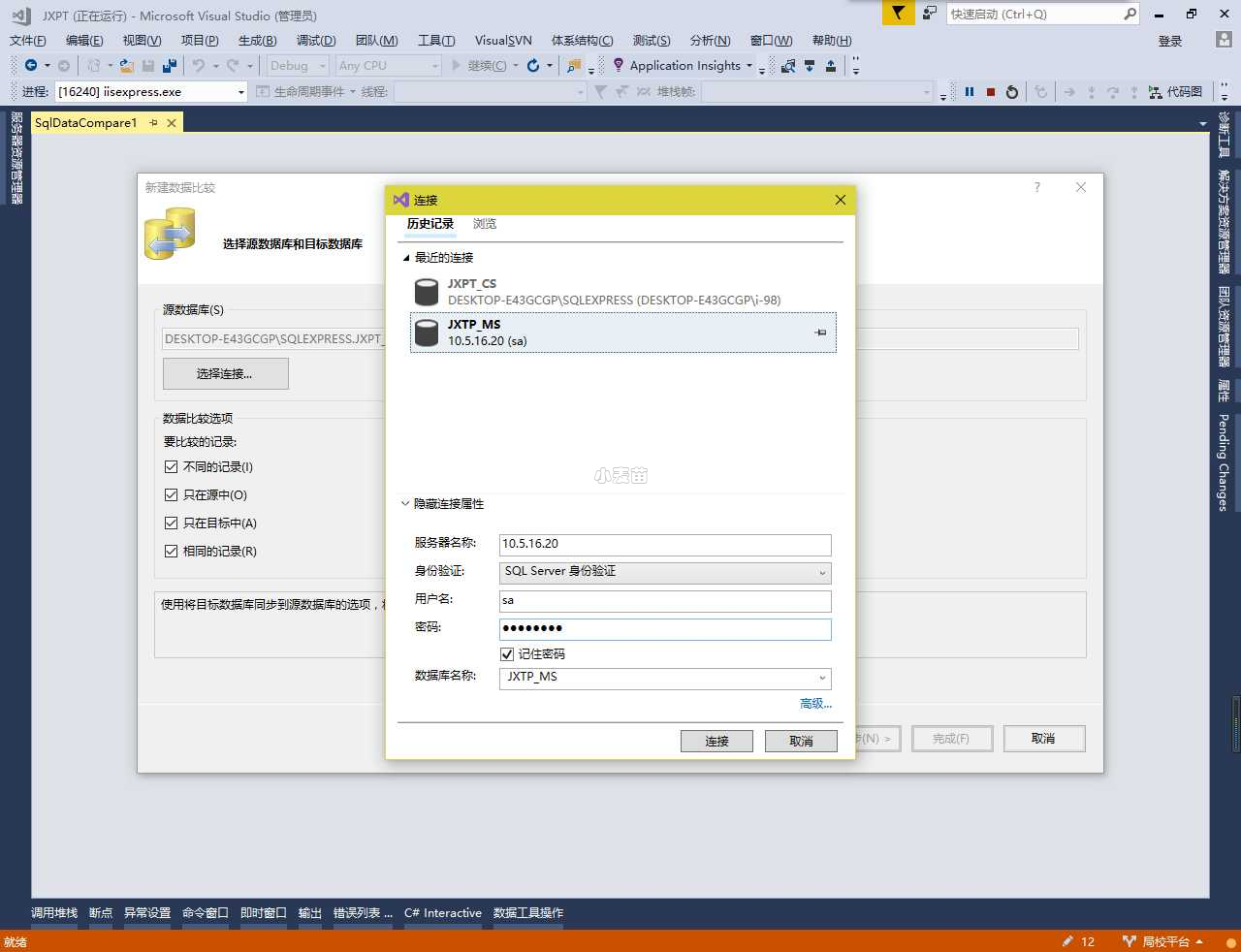
然后我们点击下一步
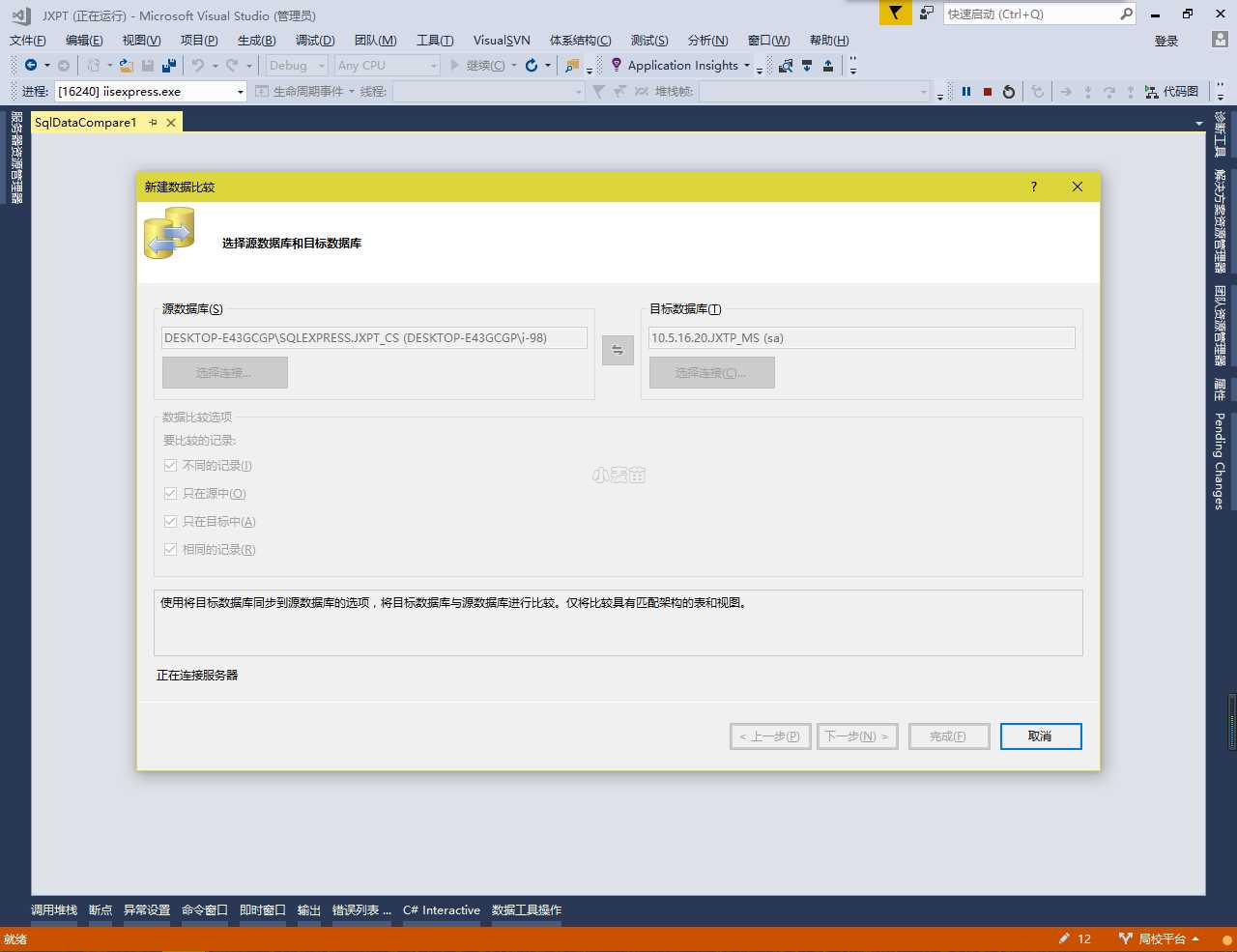
3.比较源数据库和目标数据库
源数据库和目标数据库都选择完成后,然后选择要比较的表、字段和视图
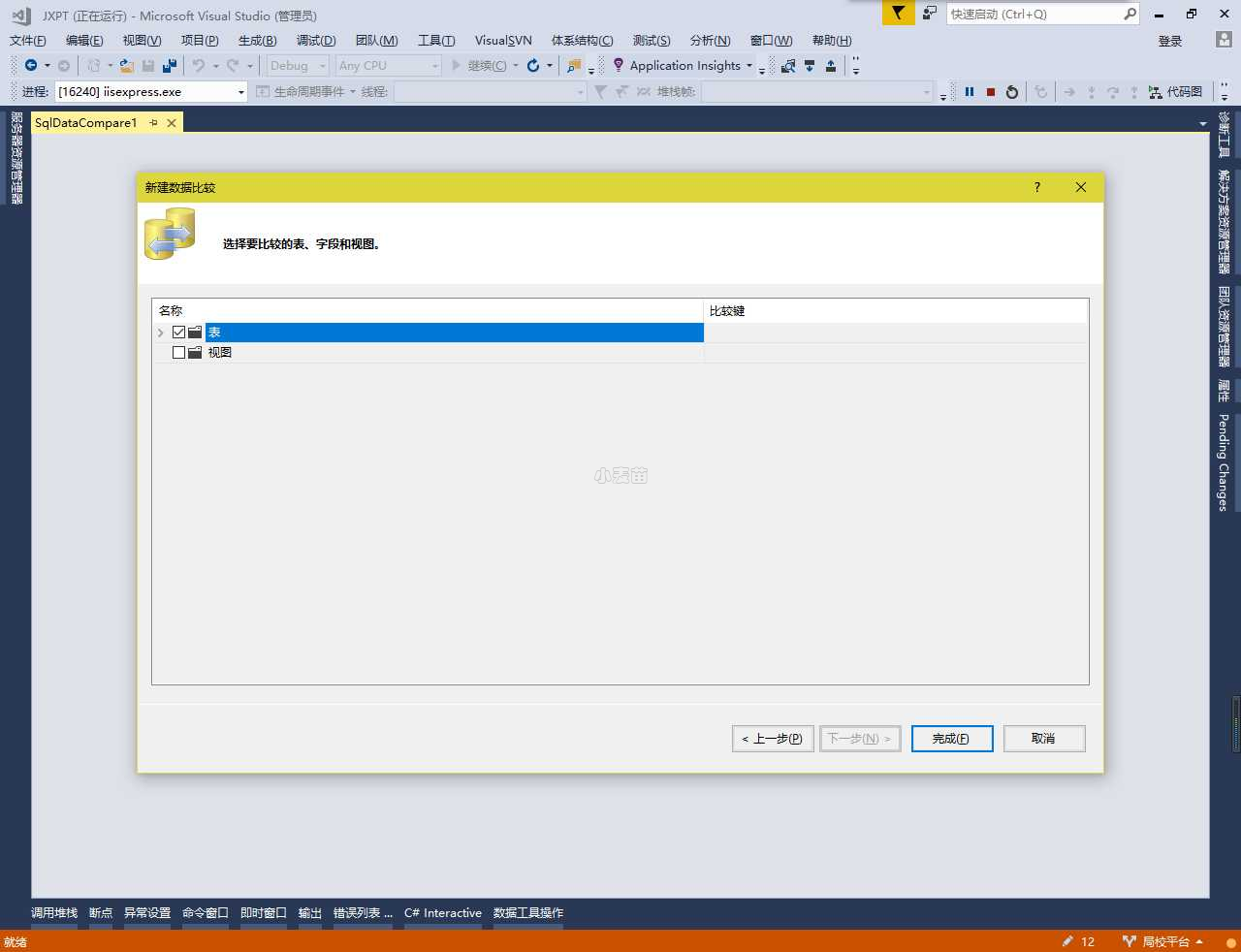
点开表,也可以根据需求选择相应的表
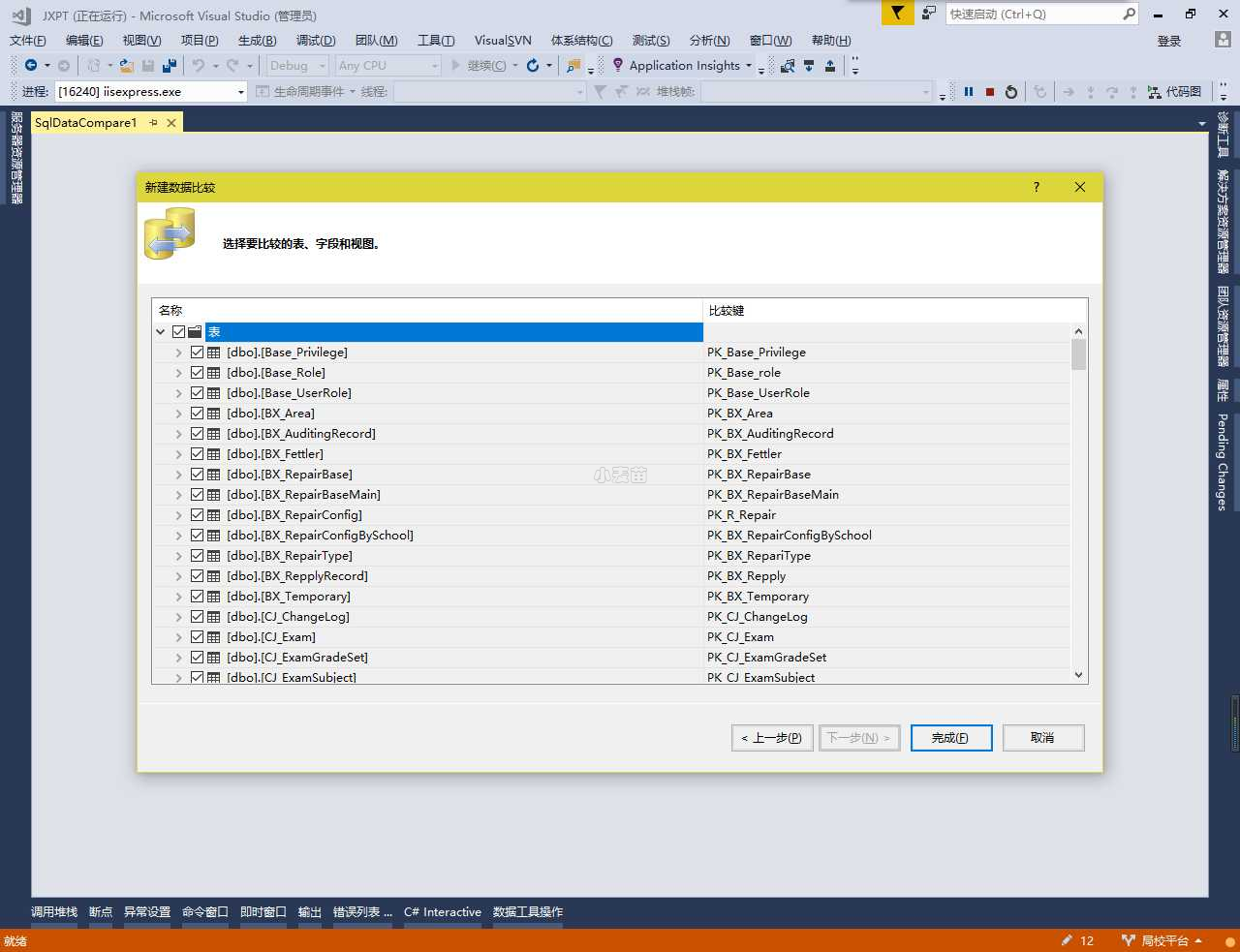
点击完成,开始比较
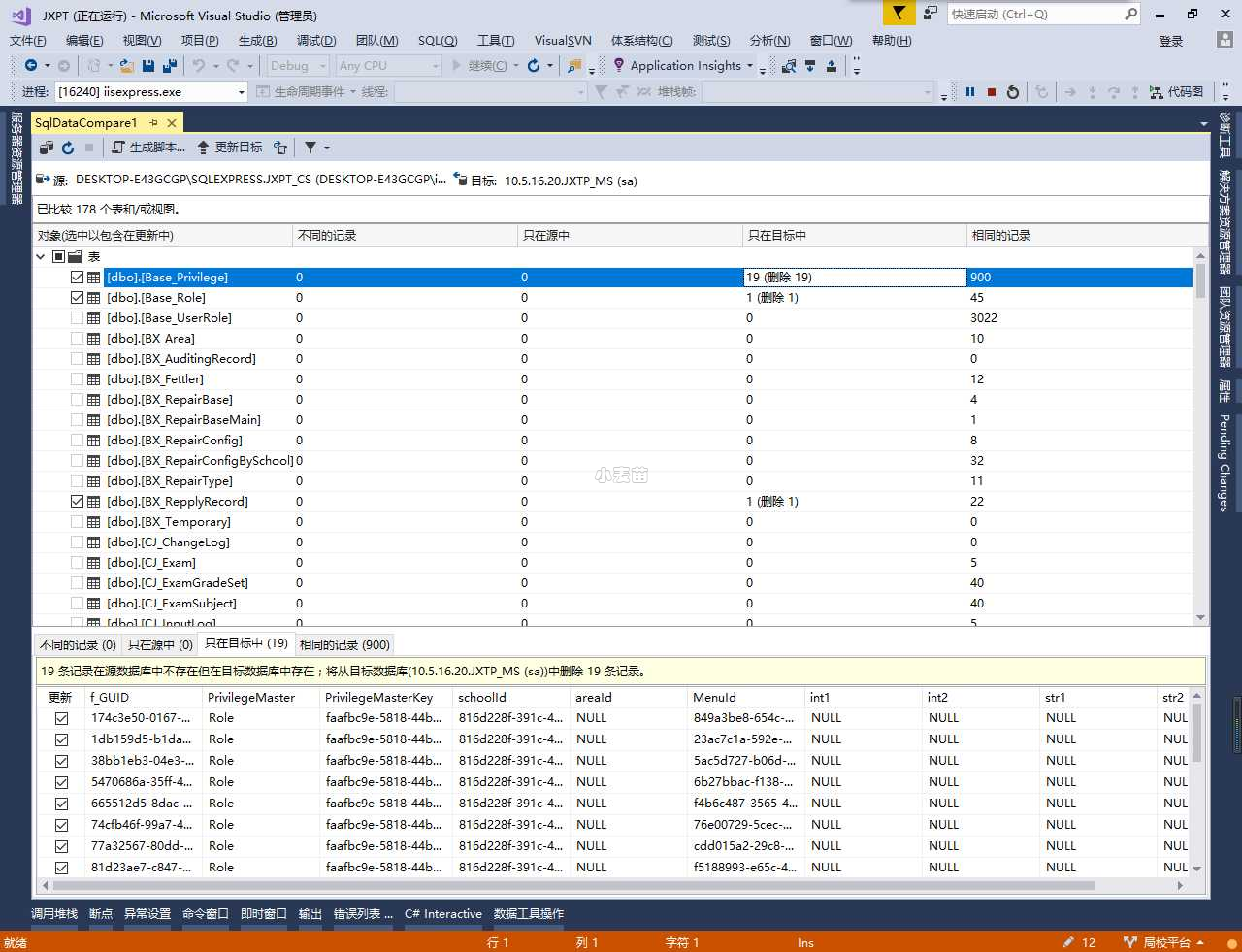
上面我们会看到各个表之间的数据差异,可以选择查看,可以以在下面Tab页切换查看。