合 Greenplum的日常监控
- 简介
- 监控数据库活动和性能
- 监控系统状态
- 检查系统状态
- 查看Master和Segment的状态及配置
- 查看镜像配置和状态
- 检查磁盘空间使用
- 检查分布式数据库和表的大小
- 查看一个数据库的磁盘空间使用情况
- 查看一个表的磁盘空间使用情况
- 查看索引的磁盘空间使用情况
- 检查数据分布倾斜
- 查看一个表的分布键
- 查看数据分布
- 检查查询过程倾斜
- 避免极度倾斜警告
- 查看数据库对象的元数据信息
- 查看最后一个执行的操作
- 查看一个对象的定义
- 查看会话内存使用信息
- 创建session_level_memory_consumption视图
- session_level_memory_consumption视图
- 查看查询工作文件使用信息
- 查看数据库服务器日志文件
- 日志文件格式
- 搜索Greenplum服务器日志文件
- 监控Greenplum数据库日志文件
- 使用gp_toolkit
- 用操作系统工具监控
- 最佳实践
- 附加信息
- 用ANALYZE更新统计信息
- 有选择地生成统计信息
- 提升统计信息质量
- 何时运行ANALYZE
- 配置统计信息自动收集
- 管理数据库膨胀
- 检测膨胀
- 从数据库表移除膨胀
- 从索引移除膨胀
- 从系统目录移除膨胀
- 从追加优化表移除膨胀
- Recommended Monitoring and Maintenance Tasks
- Database State Monitoring Activities
- Database Alert Log Monitoring
- Hardware and Operating System Monitoring
- Catalog Monitoring
- Data Maintenance
- Database Maintenance
- Patching and Upgrading
- 参考
简介
可以用系统中包含的各种工具以及附加组件来监控一个Greenplum数据库系统。
观察Greenplum数据库系统日常的性能有助于管理员理解系统的行为、计划工作流以及故障排查问题。 本章讨论用于监控数据库性能和活动的工具。
另外,记得回顾Recommended Monitoring and Maintenance Tasks中编写脚本 监控活动来快速检测系统中问题的有关内容。
Greenplum数据库提供了一些对监控系统非常有用的工具。
gp_toolkit模式包含多个可以用SQL命令访问的视图,通过它们可以查询系统目录、日志 文件以及操作环境来获得系统状态信息。
gp_stats_missing视图展示没有统计信息且要求运行ANALYZE的表。
监控数据库活动和性能
Greenplum数据库包含一个可选的系统监控和管理数据库gpperfmon,管理员可以 选择启用它。gpperfmon_install命令行工具创建gpperfmon 数据库并启用数据收集代理来存储查询和系统矩阵信息到该数据库。管理员可以查询gpperfmon 数据库中的矩阵信息。更多gpperfmon的信息,请见Greenplum Database Reference Guide。
监控系统状态
作为一个Greenplum数据库管理员,必须监控系统的问题事件,例如一个Segment宕机或者一台Segment主机磁盘 空间耗尽。下面的主题描述如何监控一个Greenplum数据库系统的健康状况以及检查一个Greenplum数据库系统的 特定状态信息。
检查系统状态
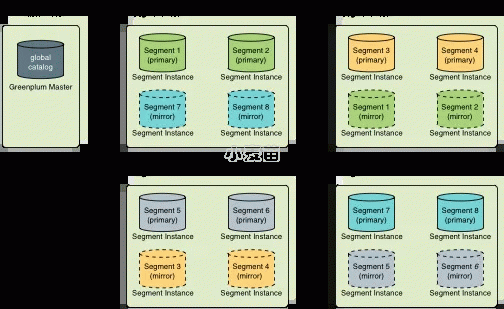
一个Greenplum数据库系统由横跨多台机器的多个PostgreSQL实例(Master和Segment)构成。要监控一个 Greenplum数据库系统,需要了解整个系统的信息以及个体实例的状态信息。gpstate 工具提供有关一个Greenplum数据库系统的状态信息。
查看Master和Segment的状态及配置
默认的gpstate行为是检查Segment实例并且显示可用和失效Segment的一个简短状态。 例如,要快速查看Greenplum数据库系统的状态:
1 | $ gpstate |
要查看Greenplum数据库阵列配置更详细的信息,使用带有-s选项的gpstate:
1 | $ gpstate -s |
查看镜像配置和状态
如果在使用镜像作为数据冗余,用户可能想要看看系统中的镜像Segment实例列表、它们当前的同步状态以及 镜像和主Segment之间的映射。例如,要查看一个系统中的镜像Segment和它们的状态:5
1 | $ gpstate -m |
要查看主Segment到镜像Segment的映射:
1 | $ gpstate -c |
要查看后备Master镜像的状态:
1 | $ gpstate -f |
检查磁盘空间使用
一个数据库管理员最重要的监控任务是确保Master和Segment数据目录所在的文件系统的使用率不会超过 70%的。完全占满的数据磁盘不会导致数据损坏,但是可能会妨碍数据库的正常操作。如果磁盘占用得太满, 可能会导致数据库服务器关闭。
可以使用gp_toolkit管理模式中的gp_disk_free外部表 来检查Segment主机文件系统中的剩余空闲空间(以KB为计量单位)。例如:
1 | =# SELECT * FROM gp_toolkit.gp_disk_free ORDER BY dfsegment; |
检查分布式数据库和表的大小
gp_toolkit管理模式包含几个可以用来判断Greenplum数据库的分布式数据库、 模式、表或索引磁盘空间使用的视图。
用于检查数据库对象尺寸和磁盘空间的视图列表,请见Greenplum Database Reference Guide.
查看一个数据库的磁盘空间使用情况
要查看一个数据库的总大小(以字节计),使用gp_toolkit管理模式中的gp_size_of_database 视图。例如:
1 | => SELECT * FROM gp_toolkit.gp_size_of_database ORDER BY sodddatname; |
查看一个表的磁盘空间使用情况
gp_toolkit管理模式包含几个检查表大小的视图。表大小视图根据对象ID (而不是名称)列出表。要根据一个表的名称检查其尺寸,必须在pg_class表中查找关系名称 (relname)。例如:
1 2 3 4 | => SELECT relname AS name, sotdsize AS size, sotdtoastsize AS toast, sotdadditionalsize AS other FROM gp_toolkit.gp_size_of_table_disk as sotd, pg_class WHERE sotd.sotdoid=pg_class.oid ORDER BY relname; |
可用的表大小视图的列表请见Greenplum Database Reference Guide.
查看索引的磁盘空间使用情况
gp_toolkit管理模式包含几个用于检查索引大小的视图。要查看一个表上所有索引的总大小,使用 gp_size_of_all_table_indexes视图。要查看一个特定索引的大小,使用gp_size_of_index视图。 该索引大小视图根据对象ID(而不是名称)列出表和索引。要根据一个索引的名称查看其尺寸,必须在pg_class 表中查找关系名称(relname)。例如:
1 2 3 4 | => SELECT soisize, relname as indexname FROM pg_class, gp_toolkit.gp_size_of_index WHERE pg_class.oid=gp_size_of_index.soioid AND pg_class.relkind='i'; |
检查数据分布倾斜
Greenplum数据库中所有的表都是分布式的,意味着它们的数据被按规则划分到系统中的所有Segment上。 不均匀分布的数据可能会削弱查询处理性能。一个表的分布策略在表创建时被确定。有关选择表分布策略的信息, 请见下列主题:
gp_toolkit管理模式还包含一些用于检查表上数据分布倾斜的视图。有关如何检查非均匀数据分布的信息, 请见Greenplum Database Reference Guide.
查看一个表的分布键
要查看一个表中被用作数据分布键的列,可以使用psql中的\d+ 元命令来检查表的定义。例如:
1 2 3 4 5 6 7 8 9 | =# \d+ sales Table "retail.sales" Column | Type | Modifiers | Description -------------+--------------+-----------+------------- sale_id | integer | | amt | float | | date | date | | Has OIDs: no Distributed by: (sale_id) |
当我们创建复制表时,Greenplum数据库会在每个Segment上都存储一份完整的表数据。复制表没有分布键。 \d+元命令会展示分布表的分布键,复制表展示状态为Distributed Replicated。
查看数据分布
要查看一个表中行的数据分布(每个Segment上的行数),可以运行一个这样的查询:
1 | =# SELECT gp_segment_id, count(*) FROM table_name GROUP BY gp_segment_id; |
如果所有的Segment都有大致相同的行数,一个表就可以被认为是分布均匀的。
Note:
如果在复制表上运行该查询会执行失败,因为Greenplum数据库不允许用户查询复制表的gp_segment_id 系统列数据。由于每个Segment上都有一份完整的表数据,复制表必然是均匀的。
检查查询过程倾斜
当一个查询被执行时,所有的Segment应该具有等量的负载来保证最好的性能。如果发现了一个执行性能低下的查询, 可能需要使用EXPLAIN命令进行深入研究。有关使用EXPLAIN命令和查询 分析的信息,请见查询分析.
如果表的数据分布策略与查询谓词没有很好地匹配,查询执行负载可能会倾斜。要检查执行倾斜,可以运行一个这样 的查询:
1 | =# SELECT gp_segment_id, count(*) FROM table_name WHERE column='value' GROUP BY gp_segment_id; |
这将显示对于给定的WHERE谓词,Segment会返回的行数。
如查看数据分布所说的, 该查询在复制表上运行时也会报错,因为在复制表上查询的 gp_segment_id列不具有参考价值。
避免极度倾斜警告
当执行一个使用哈希连接操作的查询时,可能会收到下面的警告消息:
Extreme skew in the innerside of Hashjoin
当一个哈希连接操作符的输入倾斜时,就会发生这种情况。它不会阻碍查询成功完成。可以按照这些步骤来避免计划 中的倾斜:
- 确保所有的事实表都被分析过。
- 验证该查询用到的任何已填充临时表都被分析过。
- 查看该查询的EXPLAIN ANALYZE计划,并且在其中查找以下信息:
- 如果有带多列过滤的扫描产生超过预估的行数,则将gp_selectivity_damping_factor 服务器配置参数的值设置为当前值的2倍以上并且重新测试该查询。
- 如果在连接一个相对较小(小于5000行)的单一事实表时发生倾斜,将gp_segments_for_planner 服务器配置参数设置为1并且重新测试该查询。
- 检查应用于该查询的过滤属性是否匹配基表的分布键。如果过滤属性和分布键相同,考虑用不同的 分布键重新分布一些基表。
- 检查连接键的基数。如果基数较低,尝试用不同的连接列或者表上额外的过滤属性来重写该查询以降低行数。 这些更改可能会改变查询的语义。
查看数据库对象的元数据信息
Greenplum数据库在其系统目录中跟踪各种有关存储在数据库中对象(例如表、视图、索引等等)和 全局对象(例如角色和表空间)的元数据信息。
查看最后一个执行的操作
可以使用系统视图pg_stat_operations和 pg_stat_partition_operations 查看在一个对象(例如一个表)上执行的动作。例如,要查看在一个表上执行的动作,比如它何时被创建以及它上一次是什么时候被清理和分析:
1 2 3 4 5 6 7 8 9 10 11 | => SELECT schemaname as schema, objname as table, usename as role, actionname as action, subtype as type, statime as time FROM pg_stat_operations WHERE objname='cust'; schema | table | role | action | type | time --------+-------+------+---------+-------+-------------------------- sales | cust | main | CREATE | TABLE | 2016-02-09 18:10:07.867977-08 sales | cust | main | VACUUM | | 2016-02-10 13:32:39.068219-08 sales | cust | main | ANALYZE | | 2016-02-25 16:07:01.157168-08 (3 rows) |
查看一个对象的定义
要查看一个对象(例如表或者视图)的定义,在psql中可以使用\d+元命令。 例如,要查看一个表的定义:
1 | => \d+ mytable |
查看会话内存使用信息
参考:https://www.dbaup.com/greenplumchakanhuihuaneicunshiyongxinxi.html
可以创建并且使用session_level_memory_consumption视图来查看正在Greenplum数据库上运行查询的会话的 当前内存利用信息。该视图包含会话信息以及该会话连接到的数据库、该会话当前运行的查询和会话处理所消耗的内存等信息。
创建session_level_memory_consumption视图
要在Greenplum数据库中创建session_level_memory_consumption视图, 为每一个数据库运行一次扩展创建语句CREATE EXTENSION gp_internal_tools;。 例如,要在数据库testdb中安装该视图,可使用这个命令:
1 | $ psql -d testdb -c "CREATE EXTENSION gp_internal_tools;" |
session_level_memory_consumption视图
session_level_memory_consumption视图提供有关正在运行SQL查询的会话的内存消耗以及闲置时间的信息。
当基于资源队列的资源管理方式启用时,在该视图中,列is_runaway表示是否Greenplum数据库认为 该会话是一个失控会话,这种判断基于该会话的查询的vmem内存消耗来做出。在资源队列管理模式下,当查询消耗过多内存时, Greenplum数据库认为该会话处于失控状态。Greenplum数据库的服务器配置参数runaway_detector_activation_percent 控制Greenplum数据库什么时候会认为一个会话是失控会话。
在该视图中,当基于组的资源管理方式启用时,列is_runaway, runaway_vmem_mb,和 runaway_command_cnt功能失效。
| 列 | 类型 | 引用 | 描述 |
|---|---|---|---|
| datname | name | 该会话连接到的数据库名。 | |
| sess_id | integer | 会话ID。 | |
| usename | name | 会话用户的用户名。 | |
| current_query | text | 该会话正在运行的当前SQL查询。 | |
| segid | integer | Segment ID。 | |
| vmem_mb | integer | 该会话的总vmem内存使用,以MB计。 | |
| is_runaway | boolean | 会话被标记为在Segment上失控。 | |
| qe_count | integer | 该会话的查询处理数量。 | |
| active_qe_count | integer | 该会话的活动查询处理数量。 | |
| dirty_qe_count | integer | 还没有释放其内存的查询处理的数量。对于没有运行的会话该值为-1。 | |
| runaway_vmem_mb | integer | 当会话被标记为失控会话时消耗的vmem内存量。 | |
| runaway_command_cnt | integer | 当会话被标记为失控会话时的命令计数。 | |
| idle_start | timestamptz | 这个会话中上一次一个查询处理变成空闲的时间。 |
查看查询工作文件使用信息
Greenplum数据库管理方案gp_toolkit包含显示Greenplum数据库工作文件信息的视图。 如果没有足够的内存让查询完全在内存中执行,Greenplum数据库会在磁盘上创建工作文件。这些 信息可以用来故障排查和查询调优。这些视图中的信息也可以被用来为Greenplum数据库配置参数 gp_workfile_limit_per_query和gp_workfile_limit_per_segment 指定值。
在模式gp_toolkit中有下面这些视图:
- gp_workfile_entries视图为当前在Segment上创建了工作文件的每个 操作符都包含一行。
- gp_workfile_usage_per_query视图为当前在Segment上创建了工作 文件的每个查询都包含一行。
- gp_workfile_usage_per_segment视图为每个Segment都包含一行。 每一行显示了当前在该Segment上用于工作文件的总磁盘空间。
有关使用gp_toolkit的信息请见使用gp_toolkit。
查看数据库服务器日志文件
Greenplum数据库中的每一个数据库实例(Master和Segment)都运行着一个有着自己的服务器日志文件的 PostgreSQL数据库服务器。日常的日志文件被创建在Master和每个Segment的数据目录中的 pg_log目录下。
日志文件格式
服务器日志文件被写成一种逗号分隔值(CSV)格式。一些日志项并不会所有的域都有值。例如,只有与一个查询 工作者进程相关的日志项才会有slice_id值。可以用查询的会话标识符(gp_session_id) 和命令标识符(gp_command_count)来确定一个特定查询的相关日志项。
下列域会被写入到日志中:
| # | 域名称 | 数据类型 | 描述 |
|---|---|---|---|
| 1 | event_time | timestamp with time zone | 该日志项被写入到日志中的时间 |
| 2 | user_name | varchar(100) | 数据库用户名 |
| 3 | database_name | varchar(100) | 数据库名 |
| 4 | process_id | varchar(10) | 系统进程ID(以”p”为前缀) |
| 5 | thread_id | varchar(50) | 线程号(以”th”为前缀) |
| 6 | remote_host | varchar(100) | 在Master上,是客户端机器的主机名/地址。在Segment上,是Master的主机名/地址。 |
| 7 | remote_port | varchar(10) | Segment或者Master的端口号 |
| 8 | session_start_time | timestamp with time zone | 会话连接被打开的时间 |
| 9 | transaction_id | int | Master上的顶层事务ID。这个ID是任何子事务的父亲。 |
| 10 | gp_session_id | text | 会话标识符号(以”con”为前缀) |
| 11 | gp_command_count | text | 会话中的命令号(以”cmd”为前缀) |
| 12 | gp_segment | text | Segment内容标识符(主Segment以”seg”为前缀,镜像Segment以”mir”为前缀)。Master的内容ID总是为-1。 |
| 13 | slice_id | text | 切片ID(被执行的查询计划的一部分) |
| 14 | distr_tranx_id | text | 分布式事务ID |
| 15 | local_tranx_id | text | 本地事务ID |
| 16 | sub_tranx_id | text | 子事务ID |
| 17 | event_severity | varchar(10) | 值包括:LOG、ERROR、FATAL、PANIC、DEBUG1、DEBUG2 |
| 18 | sql_state_code | varchar(10) | 与日志消息相关的SQL状态代码 |
| 19 | event_message | text | 日志或者错误消息文本 |
| 20 | event_detail | text | 与一个错误或者警告消息相关的详细消息文本 |
| 21 | event_hint | text | 与一个错误或者警告消息相关的提示消息文本 |
| 22 | internal_query | text | 内部生成的查询文本 |
| 23 | internal_query_pos | int | 内部生成的查询文本的指针式索引 |
| 24 | event_context | text | 这个消息产生的上下文 |
| 25 | debug_query_string | text | 完整的用户提供的查询字符串,用于调试。内部使用可能会修改这个字符串。 |
| 26 | error_cursor_pos | int | 该查询字符串中的指针式索引 |
| 27 | func_name | text | 这个消息产生的函数 |
| 28 | file_name | text | 产生该消息的内部代码文件 |
| 29 | file_line | int | 产生该消息的内部代码文件的行号 |
| 30 | stack_trace | text | 与这个消息相关的堆栈跟踪 |
搜索Greenplum服务器日志文件
Greenplum数据库提供一个名为gplogfilter的工具,它可以在一个Greenplum数据库 日志文件中搜索匹配指定条件的项。默认情况下,这个工具在默认日志位置搜索Greenplum数据库的Master日志。 例如,要显示Master日志文件的最后三行:
1 | $ gplogfilter -n 3 |
要同时搜索所有Segment的日志文件,可以通过gpssh工具来运行gplogfilter。 例如,要显示每个Segment日志文件的最后三行:
1 2 | $ gpssh -f seg_host_file => source /usr/local/greenplum-db/greenplum_path.sh=> gplogfilter -n 3 /gpdata/gp*/pg_log/gpdb*.log |
监控Greenplum数据库日志文件
了解系统日志文件的位置和内容并且定期监控它们而不是在问题发生时才监控。
下面的表格展示了各种Greenplum数据库日志文件的位置。在文件路径中:
- $GPADMIN_HOME 是操作系统用户gpadmin的家目录 路径。
- $MASTER_DATA_DIRECTORY是Greenplum数据库master主机的数据目录。
- $GPDATA_DIR是Greenplum数据库segment主机的数据目录。
- host表示segment主机的主机名。
- segprefix是segment前缀。
- N是segment实例数量。
- date是YYYYMMDD格式的日期。
| 路径 | 描述 |
|---|---|
| $GPADMIN_HOME/gpAdminLogs/ | 很多不同种类的日志文件,每台服务器都有的目录。$GPADMIN_HOME是gpAdminLogs/目录的 默认存放位置。用户也可以在运行管理工具命令时指定一个另外的位置。 |
| $GPADMIN_HOME/gpAdminLogs/gpinitsystemdate.log | 系统初始化日志 |
| $GPADMIN_HOME/gpAdminLogs/gpstart*date.log | 启动日志 |
| $GPADMIN_HOME/gpAdminLogs/gpstop*date.log | 停止日志 |
| $GPADMIN_HOME/gpAdminLogs/gpsegstart.pyhost:gpadmindate.log* | segment主机启动日志 |
| $GPADMIN_HOME/gpAdminLogs/gpsegstop.pyhost:gpadmin_date.log | segment主机停止日志 |
| $MASTER_DATA_DIRECTORY/pg_log/startup.log, $GPDATA_DIR/segprefixN/pg_log/startup.log | segment实例启动日志 |
| $MASTER_DATA_DIRECTORY/gpperfmon/logs/gpmon..log | gpperfmon日志 |
| $MASTER_DATA_DIRECTORY/pg_log/.csv, $GPDATA_DIR/segprefixN/pg_log/.csv | master和segment数据库日志 |
| $GPDATA_DIR/mirror/segprefixN/pg_log/.csv | 镜像segment数据库日志 |
| $GPDATA_DIR/primary/segprefixN/pg_log/*.csv | 主segment数据库日志 |
| /var/log/messages | Linux系统消息 |
首先使用gplogfilter -t(--trouble)在master日志中搜索以 ERROR:、FATAL:或者PANIC:开始的消息。 以WARNING开始的消息也可能提供有用的信息。