
合 GreenPlum中的GPORCA优化器
关于GPORCA
在Greenplum数据库中,默认的GPORCA优化器与传统查询优化器共存。
这些小节描述GPORCA的功能和用法:
- GPORCA概述
GPORCA扩展了Greenplum数据库传统优化器的规划和优化能力。 - 启用和禁用GPORCA
默认情况下,Greenplum数据库使用GPORCA来替代传统查询规划器。服务器配置参数可以启用或者禁用GPORCA。 - 收集根分区统计信息
对于分区表,GPORCA使用表根分区的统计信息来生成查询计划。这些统计信息用于确定联接顺序、拆分和联接聚合节点以及计算查询步骤的成本。相比之下,Postgres规划器使用每个叶分区的统计信息。 - 使用GPORCA时的考虑
用GPORCA最优化执行查询需要考虑的查询条件。 - GPORCA特性和增强
GPORCA是Greenplum的下一代查询优化器,它包括了对特定类型的查询和操作的增强: - GPORCA改变的行为
相比使用传统规划器,启用了GPORCA优化器(默认启用)的Greenplum数据库的行为有些改变。 - GPORCA的限制
在Greenplum数据库中使用默认的GPORCA优化器时有一些限制。GPORCA和传统的查询优化器当前并存于Greenplum数据库中,因为GPORCA不支持所有的Greenplum数据库特性。 - 判断被使用的查询优化器
当GPORCA被启用(默认启用)时,可以判断Greenplum数据库是在使用GPORCA还是退回到传统查询优化器。 - 关于统一多级分区表
GPORCA概述
GPORCA扩展了Greenplum数据库传统优化器的规划和优化能力。 GPORCA是可扩展的,它能在多核环境中获得更好的性能。Greenplum数据库默认使用GPORCA来生成查询计划。
GPORCA也在下列领域增强了Greenplum数据库的查询性能调优:
- 针对分区表的查询
- 包含公共表表达式(CTE)的查询
- 包含子查询的查询
在Greenplum数据库中,GPORCA与传统查询优化器并存。默认情况下,Greenplum数据库使用GPORCA。如果无法使用GPORCA,则会使用传统查询优化器。
下图展示了GPORCA如何融合到查询规划架构中。
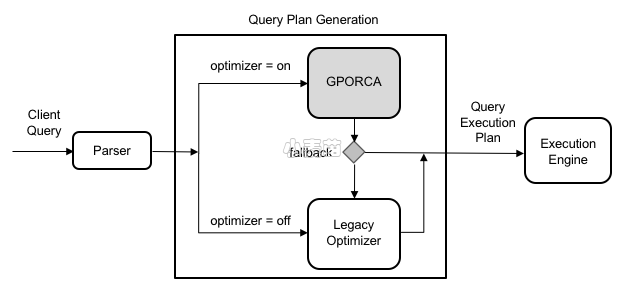
Note: GPORCA会忽略所有的传统查询优化器服务器参数。然而,如果Greenplum数据库回退到传统查询优化器,优化器服务器配置参数将影响查询计划的生成。关于传统查询优化器的服务器参数,查看查询调节参数.
启用和禁用GPORCA
默认情况下,Greenplum数据库使用GPORCA来替代传统查询规划器。服务器配置参数可以启用或者禁用GPORCA。
虽然GPORCA默认处于启用状态,但您可以使用optimizer参数在系统,数据库,会话或查询级别配置GPORCA使用情况。 如果要更改默认行为,请参阅以下部分之一:
Note: 可以使用服务器配置参数optimizer_control禁用启用或者禁用GPORCA的能力。有关服务器配置参数的信息请见Greenplum数据库参考指南。
为一个系统启用GPORCA
为Greenplum数据库系统设置服务器配置参数optimizer。
作为gpadmin(Greenplum数据库管理员)登入到Greenplum数据库的Master主机。
设置服务器配置参数的值。下面这些Greenplum数据库gpconfig工具命令把这些参数的值设置为on:
1$ gpconfig -c optimizer -v on --masteronly重启Greenplum数据库。下面这个Greenplum数据库gpstop工具命令重新载入Master和Segment的postgresql.conf文件而不关闭Greenplum数据库。
1gpstop -u
为一个数据库启用GPORCA
用ALTER DATABASE命令为单个Greenplum数据库设置服务器配置参数optimizer。例如,这个命令为数据库test_db启用GPORCA。
1 | > ALTER DATABASE test_db SET OPTIMIZER = ON ; |
为一个会话或者查询启用GPORCA
可以使用SET命令为一个会话设置optimizer服务器配置参数。例如,在使用psql工具连接到Greenplum数据库之后,这个SET命令启用GPORCA:
1 | > set optimizer = on ; |
要为特定查询设置参数,请在运行查询之前包含SET命令。
收集根分区统计信息
对于分区表,GPORCA使用表根分区的统计信息来生成查询计划。这些统计信息用于确定联接顺序、拆分和联接聚合节点以及计算查询步骤的成本。相比之下,Postgres规划器使用每个叶分区的统计信息。
如果在分区表上执行查询,应收集根分区的统计信息,并定期更新这些统计信息,以确保gporca能够生成最佳查询计划。如果根分区统计信息不是最新的或不存在,gporca仍然对表的查询执行动态分区消除。但是,查询计划可能不是最佳的。
运行ANALYZE
默认情况下,在分区表的根分区上运行ANALYZE命令将对表中的叶分区数据进行采样, 并存储根分区的统计信息。ANALYZE 收集根分区和叶分区的统计信息,包括HyperLogLog (HLL)统计信息。ANALYZE ROOTPARTITION 只收集根分区上的统计信息。服务器配置参数optimizer_analyze_root_partition控制是否需要ROOTPARTITION关键字来收集分区表根分区的根统计信息。有关收集分区表统计信息的信息,请参阅ANALYZE命令。 .
记住,在更新根分区统计信息之前,ANALYZE总是扫描整个表。如果您的表非常大,则此操作可能需要大量时间。ANALYZE ROOTPARTITION还使用一个访问ACCESS SHARE锁,用于在执行期间阻止某些操作,如TRUNCATE和VACUUM操作。 出于这些原因,您应该定期或者当叶分区数据发生重大更改时进行ANALYZE操作。
按照以下最佳实践在系统中分区表上运行ANALYZE或ANALYZE ROOTPARTITION :
- 运行ANALYZE 在一个新的分区表中添加初始数据后。运行ANALYZE 在新的叶分区或数据已更改的叶分区上。默认情况下,如果其他叶分区具有统计信息,则在叶分区上运行命令将更新根分区统计信息。
- 当您在表的EXPLAIN查询计划中发现查询性能衰退,或者在叶分区数据发生重大更改之后,更新根分区统计信息。 例如,如果在生成根分区统计信息后的某个时刻添加新的叶子分区,请考虑运行ANALYZE或ANALYZE ROOTPARTITION以使用从新叶子分区插入的新元组更新根分区统计信息。
- 对于非常大的表,只需每周运行ANALYZE或ANALYZE ROOTPARTITION,或者以长于每天的更新时间间隔运行。
- 避免在没有参数的情况下运行ANALYZE,因为这样做会对所有数据库表(包括分区表)执行命令。对于大型数据库,这些全局ANALYZE操作很难监控,并且很难预测完成所需的时间。
- 如果您的I/O吞吐量能够支持负载,可以考虑并行运行多个ANALYZE 或ANALYZE ROOTPARTITION 操作来加速统计数据收集的操作。
- 还可以使用Greenplum数据库实用程序analyzedb更新表统计信息。使用analyzedb确保如果没有对叶分区进行任何修改,则不会重新分析以前分析过的表。
GPORCA和叶分区统计信息
尽管创建和维护根分区统计信息对于分区表的GPORCA查询性能至关重要,但是维护叶分区统计信息也很重要。 如果GPORCA无法针对分区表生成查询计划,则使用传统查询优化器,需要叶分区统计信息来为该查询生成最佳计划。
GPORCA本身也将叶分区统计信息用于直接访问叶分区的任何查询,而不是使用带有谓词的根分区来消除分区。 例如,如果知道哪些分区包含查询所需的元组,则可以直接查询叶分区表本身;在这种情况下,GPORCA使用叶分区统计信息。
禁用自动根分区统计信息收集
如果不打算使用GPORCA对分区表执行查询(设置服务器配置参数optimizer为off),然后你可以禁用自动收集分区表的根分区的统计信息。服务器配置参数optimizer_analyze_root_partition控制是否需要 ROOTPARTITION关键字来收集分区表根分区的根统计信息。参数的默认设置为on,ANALYZE命令可以在不使用ROOTPARTITION关键字的情况下收集根分区统计信息。通过将参数设置为off,可以禁用根分区统计信息的自动收集。当该值为off时,必须运行ANALZYE ROOTPARTITION来收集根分区统计信息。
以数据库管理员,比如gpadmin的身份登录Greenplum数据库master主机。
设置服务器配置参数的值。这些Greenplum数据库gpconfig实用程序命令将参数值设置为off:
1$ gpconfig -c optimizer_analyze_root_partition -v off --masteronly重启Greenplum数据库。这个实用程序命令gpstop在不关闭Greenplum数据库的情况下重新加载master和segments的postgresql.conf文件。
使用GPORCA时的考虑
用GPORCA最优化执行查询需要考虑的查询条件。
确保满足下列条件:
表不含有多列分区键。
多级分区表是一个统一多级分区表。请见关于统一多级分区表.
在针对只存在于Master的表(例如系统表pg_attribute)运行时,服务器配置参数optimizer_enable_master_only_queries被设置为on。有关该参数的信息,请见Greenplum数据库参考指南。
Note: 启用这一参数会降低catalog短查询的性能。为了避免这一问题,只对会话或者查询设置这一参数。
已经在分区表的根分区上收集了统计信息。
如果分区表包含超过20,000个分区,考虑重新设计该表的模式。
这些服务器配置参数影响GPORCA查询处理。
optimizer_cte_inlining_bound 控制对公共表表达式(CTE)查询(含有WHERE子句的查询)执行的内联量。
optimizer_force_multistage_agg 强制GPORCA为标量区分限制聚集选择一种3阶段聚集计划。
optimizer_force_three_stage_scalar_dqa 强制GPORCA在生成了带有多阶段聚集的计划时选择它。
optimizer_join_order为连接排序设置查询优化级别,通过指定要评估哪些类型的连接排序选项。
optimizer_join_order_threshold指定GPORCA使用基于动态编程的连接排序算法的最大连接子数。
optimizer_nestloop_factor控制查询优化时应用到嵌套循环连接的代价因子。
optimizer_parallel_union控制对于含有UNION或者UNION ALL子句的查询发生的并行量。当该值为on时,GPORCA可以生成一个查询计划,其中UNION或者UNION ALL操作的子操作在Segment实例上并行执行。
optimizer_sort_factor 控制GPORCA在查询优化时应用于排序操作的代价因子。当出现数据倾斜时可以为查询调整代价因子。
gp_enable_relsize_collection控制GPORCA(和传统查询优化器)处理一个没有统计信息的表的方式。默认情况下,如果统计信息不可用,GPORCA使用默认值估计行数。当该值为on,GPORCA使用表的估计大小(如果没有统计数据)。
对于分区表的根分区,此参数将被忽略。如果根分区没有统计信息,GPORCA总是使用默认值。你可以使用ANALZYE ROOTPARTITION收集根分区的统计信息。 请见ANALYZE。
这些服务器配置参数控制信息的显示和记录。
- optimizer_print_missing_stats控制有关对查询缺失统计信息的列的信息显示(默认是true)
- optimizer_print_optimization_stats控制GPORCA查询优化度量对于查询的记录(默认为off)
有关这些参数的信息请见Greenplum数据库参考指南。
GPORCA生成minidump来描述一个给定查询的优化上下文。 该文件中的信息不太容易被用于调试或者排错。minidump文件位于Master的数据目录中并且使用下面的命名格式:
Minidump_date_time.mdp
有关minidump文件的信息,请见Greenplum数据库参考指南中的服务器配置参数 optimizer_minidump 。
当EXPLAIN ANALYZE 命令使用GPORCA时,EXPLAIN计划只显示被消除的分区数。被扫描的分区不被显示。 要在Segment日志中显示被扫描分区的名字,可设置服务器配置参数gp_log_dynamic_partition_pruning为on。 下面这个SET命令的例子启用该参数。
1 | SET gp_log_dynamic_partition_pruning = on; |
GPORCA特性和增强
GPORCA是Greenplum的下一代查询优化器,它包括了对特定类型的查询和操作的增强:
GPORCA还包括下面这些优化增强:
- 改进的连接排序
- 连接-聚集重排序
- 排序顺序优化
- 查询优化中包括的数据倾斜估计
对分区表的查询
GPORCA包括这些对分区表上查询的增强:
改进了分区消除。
支持统一多级分区表。有关统一多级分区表的信息,请见关于统一多级分区表
查询计划可以包含分区选择器操作符。
不在EXPLAIN计划中枚举分区。
对于涉及静态分区选择的查询,在其中会将分区键与常量进行比较,GPORCA会在EXPLAIN输出的分区选择器操作符下面列出要被扫描的分区数。这个示例分区选择器操作符展示了过滤条件和选中的分区数:
123Partition Selector for Part_Table (dynamic scan id: 1)Filter: a > 10Partitions selected: 1 (out of 3)对于涉及动态分区选择的查询,在其中会将分区键与变量进行比较,要扫描的分区数只有在查询执行时才能知道。选中的分区不会显示在EXPLAIN输出中。
计划尺寸与分区数无关。
由于分区数导致的内存不足错误被减少。
这个CREATE TABLE命令的例子创建一个范围分区表。
1 2 3 | CREATE TABLE sales(order_id int, item_id int, amount numeric(15,2), date date, yr_qtr int) range partitioned by yr_qtr; |
GPORCA改进了针对分区表的这些类型的查询:
全表扫描。计划中不会枚举分区。
1SELECT * FROM sales;带一个常量过滤谓词的查询。会执行分区消除。
1SELECT * FROM sales WHERE yr_qtr = 201501;范围选择。会执行分区消除。
1SELECT * FROM sales WHERE yr_qtr BETWEEN 201601 AND 201704 ;涉及到分区表的连接。在下面这个例子中,分区过的维度表date_dim 被连接到事实表catalog_sales:
12SELECT * FROM catalog_salesWHERE date_id IN (SELECT id FROM date_dim WHERE month=12);
含有子查询的查询
GPORCA更有效地处理子查询。子查询是嵌套在外层查询块里面的查询。在下面的查询中,WHERE子句中的SELECT是一个子查询。
1 2 | SELECT * FROM part WHERE price > (SELECT avg(price) FROM part); |
GPORCA还能更有效地处理含有相关子查询(CSQ)的查询。相关子查询是使用来自外层查询的值的子查询。在下面的查询中,price列被使用在外层查询和子查询中。
1 2 3 | SELECT * FROM part p1 WHERE price > (SELECT avg(price) FROM part p2 WHERE p2.brand = p1.brand); |
GPORCA为下列类型的子查询生成更有效的计划:
SELECT列表中的CSQ。
1234SELECT *,(SELECT min(price) FROM part p2 WHERE p1.brand = p2.brand)AS fooFROM part p1;析取(OR)过滤条件中的CSQ。
12345SELECT FROM part p1 WHERE p_size > 40 ORp_retailprice >(SELECT avg(p_retailprice)FROM part p2WHERE p2.p_brand = p1.p_brand)具有越级关联的嵌套CSQ
123456SELECT * FROM part p1 WHERE p1.p_partkeyIN (SELECT p_partkey FROM part p2 WHERE p2.p_retailprice =(SELECT min(p_retailprice)FROM part p3WHERE p3.p_brand = p1.p_brand));Note: 传统查询优化器不支持具有越级关联的嵌套CSQ。
有聚集和不等于的CSQ。下面这个例子包含一个有不等于的CSQ。
12SELECT * FROM part p1 WHERE p1.p_retailprice =(SELECT min(p_retailprice) FROM part p2 WHERE p2.p_brand <> p1.p_brand);必须返回一行的CSQ。
123SELECT p_partkey,(SELECT p_retailprice FROM part p2 WHERE p2.p_brand = p1.p_brand )FROM part p1;
含有公共表表达式的查询
GPORCA处理含有WITH子句的查询。WITH子句也被称为公共表表达式(CTE),它会生成只在该查询中存在的临时表。下面这个查询例子包含一个CTE。
1 2 3 | WITH v AS (SELECT a, sum(b) as s FROM T where c < 10 GROUP BY a) SELECT *FROM v AS v1 , v AS v2 WHERE v1.a <> v2.a AND v1.s < v2.s; |
作为查询优化的一部分,GPORCA可以把谓词下推到一个CTE中。对于下面的例子查询,GPORCA把等于谓词推到了CTE。
1 2 3 4 5 6 7 8 | WITH v AS (SELECT a, sum(b) as s FROM T GROUP BY a) SELECT * FROM v as v1, v as v2, v as v3 WHERE v1.a < v2.a AND v1.s < v3.s AND v1.a = 10 AND v2.a = 20 AND v3.a = 30; |
GPORCA可以处理这些类型的CTE:
定义一个或者多个表的CTE。在下面的这个查询中,CTE定义两个表。
123456WITH cte1 AS (SELECT a, sum(b) as s FROM Twhere c < 10 GROUP BY a),cte2 AS (SELECT a, s FROM cte1 where s > 1000)SELECT *FROM cte1 as v1, cte2 as v2, cte2 as v3WHERE v1.a < v2.a AND v1.s < v3.s;嵌套CTE。
12345678WITH v AS (WITH w AS (SELECT a, b FROM fooWHERE b < 5)SELECT w1.a, w2.bFROM w AS w1, w AS w2WHERE w1.a = w2.a AND w1.a > 2)SELECT v1.a, v2.a, v2.bFROM v as v1, v as v2WHERE v1.a < v2.a;
GPORCA的DML操作增强
GPORCA含有对DML操作(例如INSERT,UPDATE和DELETE)的增强。

