合 Oracle的内存结构以及ORA-04030和ORA-04031错误
Tags: Oracle体系结构Shared Pool内存结构Buffer CacheLibrary CacheUGA数据字典缓存(Data Dictionary Cache)大池(Large Pool)Java PoolORA-04030保留池(Keep Pool)Database Buffer Cache保留池(Reserved Pool)Streams PoolPGAORA-04031Java池(Java Pool)Large PoolRedo Log BufferRedo日志缓冲区(Redo Log Buffer)SGA默认池(Default Pool)共享池内存大小评估回收池(Recycle Pool)库缓存库缓存(Library Cache)数据缓冲区流池(Streams Pool)程序全局区结果缓存(Result Cache)
- 简介
- SGA介绍
- (1)共享池(Shared Pool)
- 库缓存(Library Cache)
- 数据字典缓存(Data Dictionary Cache)
- 保留池(Reserved Pool)
- 结果缓存(Result Cache)
- 共享池大小评估
- (2)数据缓冲区(Database Buffer Cache)
- (3)Redo日志缓冲区(Redo Log Buffer)
- (4)大池(Large Pool)
- (5)Java池(Java Pool)
- (6)流池(Streams Pool)
- PGA介绍
- 自动PGA内存管理(Automatic PGA Memory Management)
- UGA介绍
- SHOW SGA和V$SGA的结果区别
- 和内存相关的比较有用的视图
- V$SGASTAT
- V$SGA_DYNAMIC_COMPONENTS
- V$LIBRARYCACHE
- OCP真题
- 如何解决ORA-04030和ORA-04031错误?
- (一)ORA-04030错误
- (二)ORA-04031错误
- 参考
简介
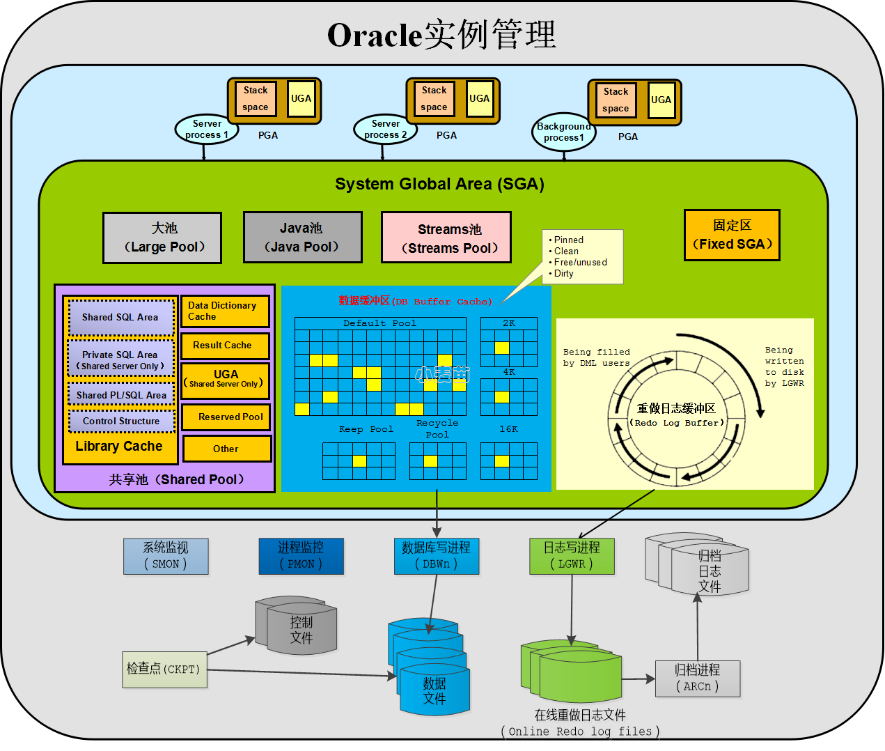
Oracle内存结构主要分共享内存区与非共享内存区,共享内存区主要包含SGA(System Global Area,系统全局区),非共享内存区主要由PGA(Program Global Area,程序全局区)组成,如下图所示:
SGA介绍
SGA(System Global Area,系统全局区)是Oracle实例的基本组成部分,是Oracle为一个实例分配的一组共享内存缓冲区,保存着Oracle系统与所有数据库用户的共享信息,包括数据维护、SQL语句分析、Redo日志管理等。SGA是实例的主要部分,它在实例启动时分配。
SGA是动态的,由参数SGA_MAX_SIZE决定。查看当前系统的SGA可以使用的最大内存大小的命令是:SHOW PARAMETER SGA_MAX_SIZE。修改SGA大小的命令是:ALTER SYSTEM SET SGA_MAX_SIZE=1200M SCOPE=SPFILE。因为实例内存的分配是在数据库启动时进行的,所以,要让修改生效,必须重启数据库。当Oracle运行在32位Linux上时,其默认SGA无法超过1.7GB。
在Oracle 10g中引入了ASMM(Automatic Shared Memory Management,自动共享内存管理),DBA只需设置SGA_TARGET,Oracle就会自动地对共享池、数据缓冲区、Redo日志缓冲区、大池、Java池和流池进行自动调配,取消自动调配的方法为设置SGA_TARGET为0。
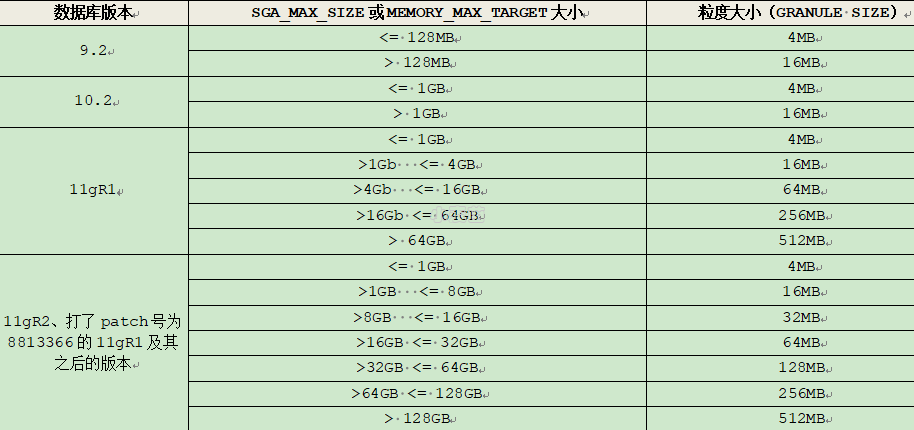
需要注意的是,Oracle分配内存的单位是granule,即粒度。最小的粒度为4M,设置大小不到一个粒度按一个粒度计算。在32位操作系统的平台上,粒度的最大值为16M。粒度的大小在数据库实例周期内不能被修改。按照粒度为单位分配的组件包括:Shared Pool、Buffer Cache(以及不同大小块的Buffer Cache)、Redo Log Buffer、Java Pool、Streams Pool和Large Pool。粒度的大小参考下表:
通过视图V$SGAINFO可以查询当前SGA分配的粒度大小,如下所示:
1 2 3 4 | SYS@orclasm > SELECT * FROM V$SGAINFO WHERE NAME='Granule Size'; NAME BYTES RES -------------------------------- ---------- --- Granule Size 4194304 No |
下面将对SGA的各个组成部分进行介绍。
缓存了各用户间可共享的各种结构,例如,缓存最近被执行的SQL语句和最近被使用的数据定义。共享池主要包括:库缓存(Library Cache)、数据字典缓存(Data Dictionary Cache)、保留池(Reserved Pool)和结果缓存(Result Cache)。
库缓存(Library Cache)
库缓存(Library Cache)是存放用户SQL命令、解析树和执行计划的区域。对于库缓存来说,具体包含以下几个部分:
共享SQL区(Shared SQL Area):保存了SQL语句文本,编译后的语法分析树及执行计划。查看共享SQL区的使用率命令为:
SELECT (SUM(PINS-RELOADS))/SUM(PINS) "LIBRARY CACHE" FROM V$LIBRARYCACHE;。私有SQL区(Private SQL Area):包含当前会话的绑定信息以及运行时内存结构。每个发出SQL语句的会话,都有一个Private SQL Area。当多个用户执行相同的SQL语句,此SQL语句保存在共享SQL区。若是共享服务器模式,则Private SQL Area位于SGA的Share Pool或Large Pool中。若是专用服务器模式,则Private SQL Area位于PGA中。
共享PL/SQL区(Shared PL/SQL Area):保存了分析与编译过的PL/SQL块(存储过程、函数、包、触发器和匿名PL/SQL块)。
控制结构区(Control Structure Area):保存锁等控制信息。
数据字典缓存(Data Dictionary Cache)
数据字典缓存(Data Dictionary Cache)存放数据库运行的动态信息,例如,表和列的定义,数据字典表的权限。查看数据字典缓冲区命中率的SQL为:“SELECT ROUND((SUM(GETS-GETMISSES-USAGE-FIXED))/SUM(GETS)*100,2) DATA_DICTIONARY_CACHE FROM V$ROWCACHE;”。
保留池(Reserved Pool)
保留池(Reserved Pool)也叫保留区域(Reserved Area),是指Shared Pool中配置的一个内存保留区域,这个保留区域用做当在普通的Shared Pool列表中的空间不能用来满足Large Request的内存分配请求而分配大块的连续内存块。当一个内存请求大于隐含参数“_SHARED_POOL_RESERVED_MIN_ALLOC”(默认:4400 bytes,如果系统经常出现ORA-04031错误,基本上都是请求大于4400的内存块,那么就可能需要增加SHARED_POOL_RESERVED_SIZE参数设置。)的值时就是一个Large Request,反之当内存请求小于“_SHARED_POOL_RESERVED_MIN_ALLOC”时就是一个Small Request。
另外关于Reserved Pool还有两个参数需要关注一下,一个是SHARED_POOL_RESERVED_SIZE,另外一个是隐含参数“_SHARED_POOL_RESERVED_PCT”(默认:5%)。通过SHARED_POOL_RESERVED_SIZE可以为Reserved Pool指定一个大小,也可以通过“_SHARED_POOL_RESERVED_PCT”来为Shared Pool指定一个比例。如果这两个参数同时设置了,那么就会以“_SHARED_POOL_RESERVED_PCT”为准。参数SHARED_POOL_RESERVED_SIZE的缺省值是SHARED_POOL_SIZE的5%,最小值为5000bytes,最大不得超过SHARED_POOL_SIZE的50%。
通过视图V$SHARED_POOL_RESERVED可以查到保留池的统计信息。其中字段REQUEST_MISSES记录了没有立即从空闲列表中得到可用的大内存段请求次数,这个值理想状态下要为0。当REQUEST_FAILURES大于0时,则需要增加SHARED_POOL_SIZE和SHARED_POOL_RESERVED_SIZE的空间。当REQUEST_MISS等于0,或是FREE_MEMORY大于等于SHARED_POOL_RESERVED_SIZE的空间时,则增加SHARED_POOL_RESERVED_SIZE的空间。MAX_USED_SPACE字段可以用来判断保留池的大小是否合适。保留区使用Shared Pool的LRU链表来管理内存块。可以通过如下的SQL语句来查询保留池的命中率(Hit Ratio),查询语句如下:
1 2 3 4 | SELECT (REQUEST_MISSES / (REQUESTS + 0.0001)) * 100 "REQUEST MISSES RATIO", (REQUEST_FAILURES / (REQUESTS + 0.0001)) * 100 "REQUEST FAILURES RATIO" FROM V$SHARED_POOL_RESERVED; |
以上结果应该都要小于1%,如果大于1,那么应该考虑加大SHARED_POOL_RESERVED_SIZE。
结果缓存(Result Cache)
结果缓存(Result Cache)是存放SQL查询结果和PL/SQL函数查询结果的区域。
共享池大小评估
共享池的大小由参数SHARED_POOL_SIZE决定。只要将初始化参数STATISTICS_LEVEL设置为TYPICAL(默认值)或ALL,就能启动对Shared Pool的建议功能,如果设置为BASIC,则关闭建议功能。使用如下的SQL语句可以查询到Oracle所建议的Shared Pool的大小:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | SYS@orclasm > SELECT SHARED_POOL_SIZE_FOR_ESTIMATE, 2 ESTD_LC_SIZE, 3 ESTD_LC_MEMORY_OBJECTS, 4 ESTD_LC_TIME_SAVED, 5 ESTD_LC_TIME_SAVED_FACTOR, 6 ESTD_LC_MEMORY_OBJECT_HITS 7 FROM V$SHARED_POOL_ADVICE; SHARED_POOL_SIZE_FOR_ESTIMATE ESTD_LC_SIZE ESTD_LC_MEMORY_OBJECTS ESTD_LC_TIME_SAVED ESTD_LC_TIME_SAVED_FACTOR ESTD_LC_MEMORY_OBJECT_HITS ----------------------------- ------------ ---------------------- ------------------ ------------------------- -------------------------- 180 9 596 15816 .9874 244830 184 13 876 15879 .9913 247845 188 17 996 15910 .9933 249132 192 21 1191 15937 .9949 249697 196 25 1329 15944 .9954 250167 200 29 1447 16018 1 254285 204 33 1630 16033 1.0009 255345 208 37 1810 16041 1.0014 255949 212 40 1999 16068 1.0031 256701 216 43 2209 16069 1.0032 257237 220 46 2428 16083 1.0041 257685 224 50 2549 16088 1.0044 258030 228 53 2639 16089 1.0044 258234 232 57 2833 16092 1.0046 258457 236 61 2985 16095 1.0048 258802 240 65 3061 16097 1.0049 259258 260 85 3709 16118 1.0062 259946 280 104 4411 16142 1.0077 260564 300 124 5084 16157 1.0087 260859 320 143 5990 16166 1.0092 260956 340 162 7155 16174 1.0097 260999 360 162 7155 16174 1.0097 261001 380 162 7155 16174 1.0097 261001 400 162 7155 16174 1.0097 261001 |
第一列表示Oracle所估计的Shared Pool的尺寸值,其他列表示在该估计的Shared Pool大小下所表现出来的指标值。可以主要关注ESTD_LC_TIME_SAVED_FACTOR列的值,当该列值为1时,表示再增加Shared Pool的大小对性能的提高没有意义。对于上例来说,当Shared Pool为200MB时,达到最佳大小。对于设置比200MB更大的Shared Pool来说,就是浪费空间,没有更多的好处了。
(2)数据缓冲区(Database Buffer Cache)
也叫数据库缓冲区高速缓存,用于缓存从数据文件中检索出来的数据块,可以大大提高查询和更新数据的性能,是数据库实例的重要组成部分。参数DB_CACHE_SIZE可指定数据缓冲区的大小,需要在参数文件中静态修改。Oracle在处理某个查询时,服务器进程会在Buffer Cache中查找它所需的所有数据块。如果未在Buffer Cache中找到所需要的数据块,那么服务器进程会从数据文件中读取所需的数据块,并在Buffer Cache中添加一个副本。因为关于同一数据块的后续请求可能会在内存中找到该数据块,因此,这些请求可能不需要进行物理读操作。Buffer Cache中的内存块有4种状态:
① Pinned:当前块正在被某个进程读取到Cache或正写到磁盘,即当前正在被访问的数据块,可防止多个会话同时对同一数据块进行写操作。此时,其他会话正等待访问该块。
② Clean:服务器进程从数据文件中读入的Block且还没有被其它进程所修改或者后台进程DBWn将Dirty Buffer写入到数据文件中的Buffer,该Buffer中的内容与数据文件中的Block一致。该状态的数据块是可以立即被移出的候选数据块。
③ Free/Unused:Buffer内为空,为实例刚启动时的状态。Buffer Cache初始化时或者在执行alter system flush buffer_cache以后的Buffer,该Buffer中没有存放任何内容。此状态与“clean”状态非常相似,不同之处在于“free/unused”状态的缓冲区尚未使用。
④ Dirty:脏数据,数据块已被修改,需要先被DBWn刷新到磁盘,才能执行过期处理(移出缓冲区)。在该状态下,该Buffer的内容与数据文件中Block的内容不一致。
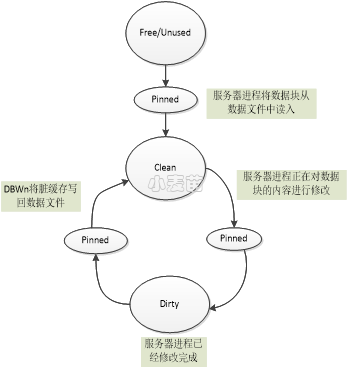
图 3-6 Database Buffer Cache中数据块的状态转变
数据库高速缓冲区的主要功能是用来暂时存放最近读取自数据库中的数据,也就是数据文件(Data File)内的数据,而数据文件是以数据块(Block)为单位,因此,数据库高速缓冲区中的大小是以块为基数。当用户通过应用程序第一次向Oracle数据库发出查询请求时,Oracle会先在Buffer Cache内寻找该数据,如果有该请求所需要的数据,那么就直接从Buffer Cache传回给用户,这称为缓存命中(Cache Hit),这样就可以减少硬盘上的I/O次数。如果Oracle发现用户要的数据并不在Buffer Cache里,就称为缓存失误(Cache Miss),Oracle会从数据库中读取所需要的数据块,先放入Buffer Cache中,再传送给用户。该区域内的数据块通过LRU(Least Recently Used,最近最少使用)算法管理。LRU将Buffer Cache中的所有的Clean和Free状态的Buffer按照它们被读取的频率连接起来。(冷端:最少使用的;热端:最常被使用的;在服务器进程将磁盘的Block读取到Buffer Cache时,会先覆盖冷端的Buffer。)。
Buffer Cache可以分为多个缓冲池:
① 回收池(Recycle Pool):放到回收池中的数据,只要空间不够用,它们马上就会被释放出来,即回收池中的数据会最先被替换出内存,很少使用的数据放在该区。被放在回收池中的数据块不会被反复使用。也就是说,这些数据块只在事务(Transaction)还存在时才会被用到,一旦事务结束,就会被释放出来。回收池的大小最好是默认池的1/2,通过DB_RECYCLE_CACHE_SIZE参数指定回收池的大小。该缓存不参与ASMM的动态管理,不能自动调整大小。默认未启用,大小为0。手工修改指定值后,Default Pool的空间将被相应的减少。
② 保留池(Keep Pool):当数据被放到保留池里时,就代表这个数据是需要常常被重复使用的。保留池中的数据不会被替换出去,可以将常用的小表放置在该区可以降低I/O操作。可以通过DB_KEEP_CACHE_SIZE参数指定保留池的大小。该区域的大小不会被ASMM自动调节。默认未启用,大小为0,当手工修改指定该值后,Default Pool的空间将被相应的减少。
③ 默认池(Default Pool):当没有指定对象存储的缓冲池时,数据就会放在默认池中,相当于一个没有Keep与Recycle池的实例的Buffer Cache。也就是说,放在默认池的数据利用的是LRU机制。通过DB_CACHE_SIZE参数指定默认池的大小。
BUFFER_POOL子句可以在对象的STORAGE子句中为对象指定使用具体的Buffer Pool。如果现有对象没有明确指定Buffer Pool,那么默认都指定为Default Buffer Pool。可以使用CREATE或ALTER语句指定对象存储的缓冲池:
1 2 3 4 5 | CREATE INDEX CUST_IDX ON TT(ID) STORAGE (BUFFER_POOL KEEP); ALTER TABLE OE.CUSTOMERS STORAGE (BUFFER_POOL RECYCLE); ALTER INDEX OE.CUST_LNAME_IX STORAGE (BUFFER_POOL KEEP); |
在同一个数据库中,支持多种大小的数据块缓存。通过DB_nK_CACHE_SIZE参数指定,如:
DB_CACHE_SIZE(指定标准块(这里为8K)的缓存区)
DB_2K_CACHE_SIZE(指定块大小为2K的缓存区)
DB_4K_CACHE_SIZE(指定块大小为4K的缓存区)
DB_16K_CACHE_SIZE(指定块大小为16K的缓存区)
DB_32K_CACHE_SIZE(指定块大小为32K的缓存区)
标准块缓冲区大小由DB_CACHE_SIZE指定。如标准块为nK,则不能通过DB_nK_CACHE_SIZE来指定标准块缓冲区的大小,应由DB_CACHE_SIZE指定。
当数据库高速缓冲区需要读取或写回数据到数据文件中时,都需要通过DBWn这个后台进程来协助处理,而参数DB_WRITER_PROCESSES主要设置要由几个DBWn来协助处理。在此建议不要超过系统CPU的个数,如果设置的值超过了CPU的个数,那么超过的那些是无法起作用的。
当参数DB_CACHE_ADVICE设置为ON(当STATISTICS_LEVEL为TYPICAL或ALL时,DB_CACHE_ADVICE参数值默认为ON)时,表示开启DB_CACHE_ADVICE功能。当开启参数DB_CACHE_ADVICE后,经过一段时间,Oracle就会自动收集足够的相关统计数据,并预测出DB_CACHE_SIZE在不同大小情况下的性能数据,而这些数据就是通过V$DB_CACHE_ADVICE视图来显示的,因此,可以根据这些数据对DB_CACHE_SIZE做相关的调整,以达到最佳情况。
对视图V$DB_CACHE_ADVICE的各列介绍如下表所示:
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| ID | NUMBER | 不同数据库高速缓冲区的编号,一般来说,DB_CACHE_SIZE的编号是3 |
| NAME | VARCHAR2(20) | 数据库高速缓冲区的名称(Default、Keep、Recycle) |
| BLOCK_SIZE | NUMBER | 数据块的大小(单位是K) |
| ADVICE_STATUS | VARCHAR2(3) | 开启状态:ON代表开启,OFF代表关闭 |
| SIZE_FOR_ESTIMATE | NUMBER | 预测性能的Cache大小(以M为单位) |
| SIZE_FACTOR | NUMBER | 预测的Cache大小比例,也就是与目前大小的比例 |
| BUFFERS_FOR_ESTIMATE | NUMBER | 预测性能数据的数据块个数 |
| ESTD_PHYSICAL_READ_FACTOR | NUMBER | 在数据库高速缓冲区里物理读取的因子,也就是说,当数据库高速缓冲区大小为SIZE_FOR_ESTIMATE此字段时,DB_CACHE_ADVICE预测的物理读数与当前物理读数的比率值。如果当前物理读数为0,那么,这个值为空 |
| ESTD_PHYSICAL_READS | NUMBER | 当数据库高速缓冲区大小为SIZE_FOR_ESTIMATE时,DB_CACHE_ADVICE预测的实际读数 |
| ESTD_PHYSICAL_READ_TIME | NUMBER | 当前物理读取的时间 |
| ESTD_PCT_OF_DB_TIME_FOR_READS | NUMBER | 当前物理读取的时间占所有时间的比例 |
查询视图V$DB_CACHE_ADVICE如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | SYS@orclasm > SELECT ADVICE_STATUS, 2 SIZE_FOR_ESTIMATE, 3 ESTD_PHYSICAL_READ_FACTOR, 4 ESTD_PHYSICAL_READS 5 FROM V$DB_CACHE_ADVICE 6 WHERE NAME = 'DEFAULT'; ADV SIZE_FOR_ESTIMATE ESTD_PHYSICAL_READ_FACTOR ESTD_PHYSICAL_READS --- ----------------- ------------------------- ------------------- ON 4 1.028 4028357 ON 8 1.0223 4006098 ON 12 1.0178 3988551 ON 16 1.0109 3961532 ON 20 1.0068 3945138 ON 24 1.0052 3939208 ON 28 1.0045 3936105 ON 32 1.004 3934171 ON 36 1.0033 3931620 ON 40 1.0023 3927591 ON 44 1.0013 3923578 ON 48 1 3918655 ON 52 .9992 3915665 ON 56 .9988 3913960 ON 60 .9984 3912432 ON 64 .9982 3911506 ON 68 .998 3910840 ON 72 .9979 3910450 ON 76 .9978 3910125 ON 80 .9925 3889182 |
由以上结果可以知道,当ESTD_PHYSICAL_READ_FACTOR为1时,最佳的DB_BUFFER_SIZE是48,因为在这之后再进行调整对降低I/O的影响有限,所以该系统最佳的Buffer Cache的大小为48M。
(3)Redo日志缓冲区(Redo Log Buffer)
对数据库进行修改的任何事务(Transaction)在记录到Redo日志文件之前都必须首先放到Redo日志缓冲区中。Redo日志缓冲区中的内容将被后台进程LGWR写入联机Redo日志文件(Online Redo Log Files)中。Redo日志缓冲区是一个循环缓存区,在使用时从顶端向底端写入数据,然后再返回到缓冲区的起始点循环写入。Oracle中所有的DML和DDL操作都会记录日志,即便没有提交的DML操作也会记录日志,在指定了NOLOGGING时,也会记录一些日志。Redo日志缓冲区大小由参数LOG_BUFFER决定,需要在参数文件中静态修改。服务器进程(Server Process)及后台进程(Background Process)对Oracle的变更记录会写到Redo日志缓冲区,这些变更的数据都在内存中的Redo日志缓冲区中以Redo Entry(重做条目,也可称为Redo Record)的方式存储。Redo Entry是Oracle从用户会话占用的内存里将这些变更的记录复制到Redo日志缓冲区内,其在内存中是一段连续的内存块,Oracle利用后台进程LGWR在适当的时机将Redo日志缓冲区中的信息(也就是Redo Entry)写回到联机Redo日志文件内,以便万一数据库崩溃,可以进行必要的恢复。后台进程LGWR将Redo Entry写回到联机Redo日志文件的时机如下:
① 用户发出提交命令(COMMIT)
② 每隔3秒
③ Redo日志缓冲区空间剩余不到2/3
④ Redo日志缓冲区内的数据达到1MB
⑤ 在发生联机Redo日志切换(Log Switch)时
⑥ 在DBWn进程将修改的缓冲区写入磁盘时(如果相应的Redo日志数据尚未写入磁盘)
(4)大池(Large Pool)
SGA中一个可选的内存区域,大池用来分配大块的内存,处理比共享池更大的内存,用来缓解Shared Pool的负担。
大池主要用在3种情况下,
①若是共享服务器模式时,则在Large Pool中分配UGA,若Large Pool没有分配则在Shared Pool中分配。若是专用服务器(多线程服务器MTS,Multi-Threaded Server)连接,则UGA在PGA中创建;
②语句的并行查询(Parallel Executeion of Statements),允许进程间消息缓冲区的分配,用来协调并行查询服务器;
③恢复管理器RMAN,用于RMAN磁盘I/O缓冲区。
大池的大小由参数LARGE_POOL_SIZE决定,可以动态修改。大池也使用共享池的闩锁机制,但和共享池不同的是,大池并不使用LRU机制,而是使用Large Memory Latch的保护,因此,大池中缓冲区内的数据不会被置换出来。大池内的数据会利用用户的会话来控制分配和释放大池的空间。如果大池的空间不足,那么也会出现ORA-04031错误。
(5)Java池(Java Pool)
为Java命令的语法分析提供服务。Java池也是SGA中的一块可选内存块,大小由参数JAVA_POOL_SIZE决定。在Oracle 10g以后,提供了一个新的Java池的建议功能,以辅助调整Java池的大小,而建议的统计数据可以通过视图V$JAVA_POOL_ADVICE来查询。
(6)流池(Streams Pool)
被Oracle流所使用,主要提供专门的Streams复制功能,流池是可选用内存块,它也属于SGA中的可变区域。参数STREAMS_POOL_SIZE可以指定流池的大小。如果设置为0,那么当第一次使用Streams复制功能时,Oracle会自动建立此块区域,而自动建立的大小为共享池大小的10%。Oracle也提供了一个流池的建议功能,来协助调整流池的大小,而建议的统计数据可以通过视图V$STREAMS_POOL_ADVICE来查询。
PGA介绍
PGA(Program Global Area,程序全局区)是单个Oracle进程使用的内存区域,为每个连接到Oracle数据库的用户进程保留的内存,不属于实例的内存结构。它含有单个进程工作时需要的数据和控制信息。PGA是非共享的,只有服务进程本身才能够访问它自己的PGA区。PGA在进程创建时分配,进程结束时释放。PGA的内容随服务器的模式(专用模式/共享服务器模式)不同而不同。PGA的大小由参数PGA_AGGREGATE_TARGET决定,可动态修改。
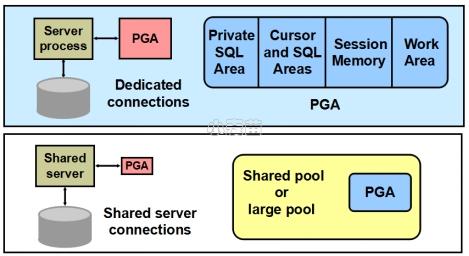
图 3-7 PGA结构图
PGA有如下几个组件:
① Private SQL Area(私有SQL区):参考Shared Pool部分的介绍。
② Cursor and SQL Areas(游标和SQL区):Oracle Pro*C程序(Pro*C是Oracle提供的应用程序专用开发工具,它以C语言为宿主语言,能在C程序中嵌入SQL语句,进行数据库操作。)的应用程序开发人员或Oracle调用接口(Oracle Call Interface,OCI)程序可以显式打开游标或处理私有SQL区。
③ Session Memory(会话内存):保存会话的变量(例如,登录信息)及其他与会话相关的信息。在共享服务器模式下,Session Memory是共享的。
④ Work Area(工作区):PGA的一大部分被分配给Work Area,用来执行如下操作:
基于排序的操作,GROUP BY、ORDER BY、ROLLUP和窗口函数。由于排序需要内存空间,Oracle利用该内存排序数据,这部分空间称为排序区。排序区存在于请求排序的用户进程的内存中,该空间的大小为适应排序数据量的大小,可增长,但受参数SORT_AREA_SIZE所限制。
HASH连接,大小受参数HASH_AREA_SIZE所限制
位图合并,大小受参数BITMAP_MERGE_AREA_SIZE所限制
位图创建,大小受参数CREATE_BITMAP_AREA_SIZE所限制
批量装载操作使用的写缓存
PGA和SGA最明显的差别在于,PGA不是共享内存,是私有不共享的。用户对数据库发起的无论查询还是更新的任何操作,都是在PGA先预处理,然后接下来才进入实例区域,由SGA和系列后台进程共同完成用户发起的请求。PGA起到的具体作用主要有三点:第一,保存用户的连接信息,如会话属性、绑定变量等;第二,保存用户权限等重要信息,当用户进程与数据库建立会话时,系统会将这个用户的相关权限查询出来,然后保存在这个会话区内;第三,当发起的指令需要排序的时候,PGA正是这个排序区,如果在内存中可以放下排序的尺寸,就在内存PGA区内完成,如果放不下,超出的部分就在临时表空间中完成排序,也就是在磁盘中完成排序。
自动PGA内存管理(Automatic PGA Memory Management)
从Oracle9i开始,Oracle引入了PGA自动管理的特性。若设置参数PGA_AGGREGATE_TARGET为非0,则表示启用PGA内存自动管理,并忽略所有*_AREA_SIZE的设置,例如SORT_AREA_SIZE、HASH_AREA_SIZE等。默认为启用PGA的自动管理,Oracle根据SGA的20%来动态调整PGA中专用于Work Area部分的内存大小,最小为10MB。
设置WORKAREA_SIZE_POLICY参数,可以在PGA自动(AUTO,默认是AUTO)和PGA手动管理(MANUAL)之间进行选择,然后通过设置初始化参数PGA_AGGREGATE_SIZE来设置PGA的内存总和。如果设置参数WORKAREA_SIZE_POLICY为MANUAL(默认值是AUTO),就代表此数据库的PGA管理模式属于手动管理模式,且在此模式下必须设置SORT_AREA_SIZE、HASH_AREA_SIZE等相关参数。需要注意的是,在Oracle 9i时,PGA自动管理只对Dedicate Server有效,对Shared Server无效,但是从Oracle 10g开始,PGA自动管理都有效。
对于OLTP系统,典型的PGA内存为:
PGA_AGGREGATE_SIZE = (total_memory 80%) 20%
对于OLAP系统,由于会运行一些很大的查询:
PGA_AGGREATE_SIZE = (total_memoery 80%) 50%
80%是指,将机器总内存的80%分给Oracle使用。然后再将80%中的20%给PGA。
可以使用PGA相关的一些视图来调整PGA_AGGREGATE_SIZE的大小,例如:V$PGASTAT、V$PGA_TARGET_ADVICE、V$PGA_TARGET_ADVICE_HISTOGRAM等。当自动PGA内存管理功能打开后,可以从V$PGA_TARGET_ADVICE中得到相关的指导数据,进而评估PGA_AGGREGATE_TARGE是否需要调整。该视图的ESTD_OVERALLOC_COUNT列表示需要额外分配的PGA内存,如果此数值不是0,就表示PGA_AGGREGATE_TARGE设置得太小,需要调整。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | SQL> SELECT PGA_TARGET_FOR_ESTIMATE / 1024 / 1024 PGAMB, 2 PGA_TARGET_FACTOR P_TR_FCT, 3 ESTD_PGA_CACHE_HIT_PERCENTAGE E_P_C_HIT_PRCT, 4 ESTD_OVERALLOC_COUNT E_OR_CNT 5 FROM V$PGA_TARGET_ADVICE; PGAMB P_TR_FCT E_P_C_HIT_PRCT E_OR_CNT ---------- ---------- -------------- ---------- 23.75 .125 82 1179 47.5 .25 82 1179 95 .5 95 233 142.5 .75 99 6 190 1 99 1 228 1.2 99 0 266 1.4 99 0 304 1.6 99 0 342 1.8 99 0 380 2 99 0 570 3 99 0 760 4 99 0 1140 6 99 0 1520 8 99 0 |
从上面的查询中可以看出当设置PGA的大小为228MB时,可以消除PGA过载的情形。
UGA介绍
UGA(User Global Area)保存了会话信息,会话总能访问这部分内存。UGA的位置取决于会话连接到Oracle的方式。如果是专用服务器连接,那么UGA在PGA中创建;如果是共享服务器连接,那么UGA在SGA的Large Pool中创建,若Large Pool没有分配则在Shared Pool中分配。
PGA和UGA两者间的区别跟一个进程和一个会话之间的区别是类似的。尽管说进程和会话之间一般都是一对一的关系,但实际上比这个更复杂。一个很明显的情况是MTS配置,会话往往会比进程多得多。在这种配置下,每一个进程会有一个PGA,每一个会话会有一个UGA。PGA所包含的信息跟会话是无任何关联的,而UGA包含的信息是以特定的会话为基础的。
SHOW SGA和V$SGA的结果区别
SHOW SGA的结果比V$SGA的结果多一行“Total System Global Area”数据。其实,SHOW SGA的结果来源于V$SGA视图。运行命令“vi $ORACLE_HOME/bin/sqlplus”打开sqlplus文件,匹配SGA可以发现这么一行代码:
1 2 3 4 5 6 7 8 9 10 | SELECT DECODE(NULL, '', 'Total System Global Area', '') NAME_COL_PLUS_SHOW_SGA, SUM(VALUE), DECODE(NULL, '', 'bytes', '') UNITS_COL_PLUS_SHOW_SGA FROM V$SGA UNION ALL SELECT NAME NAME_COL_PLUS_SHOW_SGA, VALUE, DECODE(NULL, '', 'bytes', '') UNITS_COL_PLUS_SHOW_SGA FROM V$SGA; |
该行代码的结果和执行SHOW SGA可以得到一样的结果,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | SYS@omflhr> SHOW SGA Total System Global Area 1068937216 bytes Fixed Size 2253216 bytes Variable Size 771755616 bytes Database Buffers 289406976 bytes Redo Buffers 5521408 bytes SYS@omflhr> SELECT DECODE(NULL, '', 'Total System Global Area', '') NAME_COL_PLUS_SHOW_SGA, 2 SUM(VALUE), 3 DECODE(NULL, '', 'bytes', '') UNITS_COL_PLUS_SHOW_SGA 4 FROM V$SGA 5 UNION ALL 6 SELECT NAME NAME_COL_PLUS_SHOW_SGA, 7 VALUE, 8 DECODE(NULL, '', 'bytes', '') UNITS_COL_PLUS_SHOW_SGA 9 FROM V$SGA; NAME_COL_PLUS_SHOW_SGA SUM(VALUE) UNITS_COL_PLUS_ ------------------------ ---------- --------------- Total System Global Area 1068937216 bytes Fixed Size 2253216 bytes Variable Size 771755616 bytes Database Buffers 289406976 bytes Redo Buffers 5521408 bytes |
在以上结果中,各部分的含义如下:
Total System Global Area:显示目前此SGA的大小,包括Fixed Size、Variable Size、 Database buffers和Redo Buffers的大小总和。
Fixed Size:这里存储了SGA各部分组件的相关信息,主要是作为引导SGA创建的区域,Oracle通过这个区找到SGA其它区,类似一个SGA各个组件的索引。这部分是Oracle内部使用的一个区,包括了数据库与实例的控制信息、状态信息、字典信息等。当实例被打开时,此块区域就被固定住而不能做任何变动,此区域也可称为Fixed SGA。不同平台和不同版本下这部分的大小可能不一样。
Variable Size:包括Shared Pool、Java Pool、Large Pool、Streams Pool、游标区和其它结构。由于这些内存块都是可动态分配的,所以统称为Variable Size。
Database Buffers:显示数据库高速缓冲区的大小,是SGA中最大的地方,决定数据库性能。为DB_CACHE_SIZE、DB_KEEP_CACHE_SIZE、DB_RECYCLE_CACHE_SIZE、DB_NK_CACHE_SIZE的总大小,当然这是SGA_TARGET为0的情况,也就是手动SGA管理模式下,如果是自动SGA管理(SGA_TARGET>0),则这个值根据SGA的分配情况自动进行调整。
Redo Buffers:显示Redo日志缓冲区的大小,这部分是实际分配的Redo Log Buffer的大小,由初始化参数LOG_BUFFER根据SGA的最小分配单位granule向上取整得到。
和内存相关的比较有用的视图
V$SGASTAT
V$SGASTAT主要记录了有关SGA的统计信息,以及内存分配的情况,对于发生ORA-04031错误有很重要的参考价值。其中的信息由三个字段组成,依序是:Name(SGA内存块的名称)、Bytes(内存块的大小)、Pool(内存所属的内存块)。
以下SQL可以查询SGA每个组件真实的分配大小和剩余空间(重要):