原 Greenplum集群Master与Segment节点故障检测和恢复
Greenplum集群主要包括Master节点和Segment节点,Master节点称之为主节点,Segment节点称之为数据节点。Master节点与Segment节点都是有备份的,其中Master节点的备节点为Standby Master(不能够自动故障转移),Segment是通过Primary Segment与Mirror Segment进行容错的。通过本文你可以了解:
- Greenplum数据库的高可用(HA)原理
- Greenplum生产集群中master节点故障恢复
- greenplum生产集群中segment故障检测与恢复
- Segment节点故障恢复原理与实践
Greenplum数据库的HA
master mirroring概述
可以在单独的主机或同一主机上部署master实例的备份或镜像。如果primary master服务器宕机,则standby master服务器将用作热备用服务器。在primary master服务器在线时,可以从primary master服务器创建备用master服务器。
Primary master服务器持续为用户提供服务,同时获取Primary master实例的事务快照。在standby master服务器上部署事务快照时,还会记录对primary master服务器的更改。在standby master服务器上部署快照后,更新也会被部署,用于使standby master服务器与primary master服务器同步。
Primary master服务器和备用master服务器同步后,standbymaster服务器将通过walsender 和 walreceiver 的复制进程保持最新状态。该walreceiver是standby master上的进程, walsender流程是primary master上的流程。这两个进程使用基于预读日志(WAL)的流复制来保持primary master和standby master服务器同步。在WAL日志记录中,所有修改都会在应用生效之前写入日志,以确保任何进程内操作的数据完整性。
由于primary master不包含任何用户数据,因此只需要在主master和备份master之间同步系统目录表(catalog tables)。当这些表发生更新时,更改的结果会自动复制到备用master上,以确保与主master同步。
如果primary master发生故障,管理员需要使用gpactivatestandby工具激活standby master。可以为primary master和standby master配置一个虚拟IP地址,这样,在primary master出现故障时,客户端程序就不用切换到其他的网络地址,因为在master出现故障时,虚拟IP地址可以交换到充当primary master的主机上。
mirror segment概述
当启用Greenplum数据库高可用性时,有两种类型的segment:primary和mirror。每个主segment具有一个对应的mirror segment。主segment接收来自master的请求以更改主segment的数据库,然后将这些更改复制到相应的mirror segment上。如果主segment不可用,则数据库查询将故障转移到mirror segment上。
Mirror segment采用物理文件复制的方案---primary segment中数据文件I / O被复制到mirror segment上,因此mirror segment的文件与primary segment上的文件相同。Greenplum数据库中的数据用元组(tuple)表示,元组被打包成块(block)。数据库的表存储在由一个或多个块组成的磁盘文件中。对元组进行更改操作,同时会更改保存的块,然后将其写入primary segment上的磁盘并通过网络复制到mirror segment。Mirror segment只更新其文件副本中的相应块。
对于堆表(heap)而言,块被保存在内存缓存区中,直到为新更改的块腾出空间时,才会将它们清除,这允许系统可以多次读取或更新内存中的块,而无需执行昂贵的磁盘I / O。当块从缓存中清除时,它将被写入磁盘并复制到mirror segment主机的磁盘。当块保存在缓存中时,primary segment和mirror segment具有不同的块镜像,但是,数据库仍然是一致的,因为事务日志已经被复制了。
AO表(Append-optimized)不使用内存缓存机制。对AO表的块所做的更改会立即复制到mirror segment上。通常,文件写入操作是异步的,但是打开、创建和同步文件是“同步复制”的,这意味着primary segment的块需要从mirror segment上接收确认。
如果primary segment失败,则文件复制进程将会停止,mirror segment会自动作为活动segment实例,活动mirror segment的系统状态会变为“ 更改跟踪”(Change Tracking),这意味着在primary segment不可用时,mirror segment维护着一个系统表和记录所有块的更改日志。当故障的primary segment被修复好,并准备重新上线时,管理员启动恢复过程,系统进入重新同步状态。恢复过程将记录的更改日志应用于已修复的primary segment上。恢复过程完成后,mirror segment的系统状态将更改为“已同步 ”。
如果mirror segment在primary segment处于活动状态时失败或无法访问,则primary segment的系统状态将更改为“ 更改跟踪”,并且它会记录更改的状态,用于mirror segment的恢复。
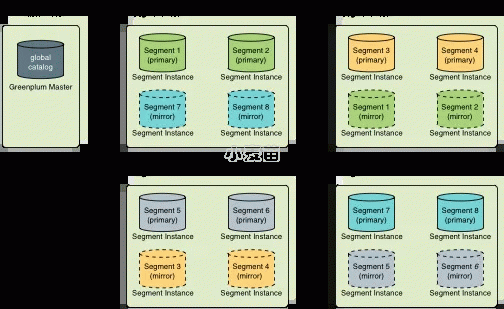
- group mirroring方式
只要primary segment实例和mirror segment实例位于不同的主机上,mirror segment就可以以不同的配置方式放置在群集中的主机上。每个主机必须具有相同数量的mirror segment和primary segment。默认mirror segment配置方式是group mirroring,其中每个主机的primary segment的mirror segment位于另一个主机上。如果单个主机发生故障,则部署该主机的mirror segment主机上的活动primary segment数量会翻倍,从而会加大该主机的负载。下图说明了group mirroring配置。
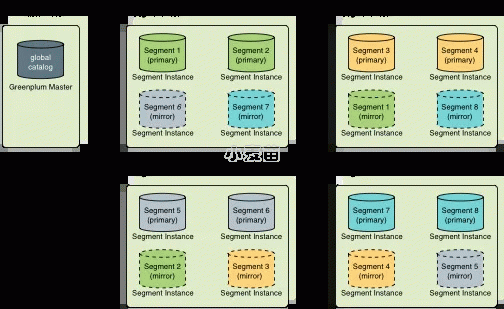
- Spread mirroring方式
Spread mirroring方式是指将每个主机的mirror segment分布在多个主机上,这样,如果任何单个主机发生故障,该主机的mirror segment会分散到其他多个主机上运行,从而达到负载均衡的效果。仅当主机数量多于每个主机的segment数时,才可以使用Spread方式。下图说明了Spread mirroring方式。
Master节点故障恢复
如果primary master节点失败,日志复制进程就会停止。可以使用gpstate -f命令查看standby master的状态,使用gpactivatestandby命令激活standby master。
激活Standby master
(1)确保原来的集群中配置了standby master
(2)在standby master主机上运行gpactivatestandby命令
$ gpactivatestandby -d /data/master/gpseg-1-d参数是指standby master的数据目录,一旦激活成功,原来的standby master就成为了primary master。(3)执行激活命令后,运行gpstate命令检查状态
$ gpstate -f新激活的master的状态是active,如果已经为集群配置一个新的standby master节点,则其状态会是passive。如果还没有为集群配置一个新的standby master,则会看到下面的信息:No entries found,该信息表明尚未配置standby master。
(4)在成功切换到了standbymaster之后,运行ANALYZE命令,收集该数据库的统计信息
$ psql postgres -c 'ANALYZE;'(5)可选:如果在成功激活standby master之后,尚未指定新的standby master,可以在active master上运行gpinitstandby命令,配置一个新的standby master
$ gpinitstandby -s new_standby_master_hostname
恢复到原来的设置(可选的)
(1)确保之前的master节点能够正常使用
(2)在原来的master主机上,移除(备份)原来的数据目录gpseg-1,比如:
$ mv /data/master/gpseg-1 /data/master/backup_gpseg-1(3)在原来的master节点上,初始化standby master,在active master上运行如下命令
$ gpinitstandby -s mdw(4)初始化完成之后,检查standby master的状态
$ gpstate -f显示的状态应该是--Sync state: sync
(5)在active master节点上运行下面的命令,用于停止master
$ gpstop -m(6)在原来的master节点(mdw)上运行gpactivatestandby命令
$ gpactivatestandby -d /data/master/gpseg-1(7)在上述命名运行结束之后,再运行gpstate命令查看状态
$ gpstate -f确认原始的primary master状态是active。
(8)在原来的standby master节点(smdw)上,移除(备份)数据目录gpseg-1
$ mv /data/master/gpseg-1 /data/master/backup_gpseg-1(9)原来的master节点正常运行之后,在该节点上执行如下命令,用于激活standby master
$ gpinitstandby -s smdw
检查standby master的状态
可以通过查看视图pg_stat_replication,来获取更多的信息。该视图可以列出walsender进程的信息,下面的命令是查看walsender进程的进程id和状态信息。
1 | $ psql postgres -c 'SELECT procpid, state FROM pg_stat_replication;' |
segment节点故障检测与恢复
概述
Greenplum数据库服务器(Postgres)有一个子进程,该子进程为ftsprobe,主要作用是处理故障检测。ftsprobe 监视Greenplum数据库阵列,它以可以配置的间隔连接并扫描所有segment和数据库进程。如果 ftsprobe无法连接到segment,它会在Greenplum数据库系统目录中将segment标记为”down”。在管理员启动恢复进程之前,该segment是不可以被操作的。
启用mirror备份后,如果primary segment不可用,Greenplum数据库会自动故障转移到mirror segment。如果segment实例或主机发生故障,系统仍可以运行,前提是所有在剩余的活动segment上数据都可用。
要恢复失败的segment,管理员需要执行 gprecoverseg 恢复工具。此工具可以找到失败的segment,验证它们是否有效,并将事务状态与当前活动的segment进行比较,以确定在segment脱机时所做的更改。gprecoverseg将更改的数据库文件与活动segment同步,并使该segment重新上线。管理员需要在在Greenplum数据库启动并运行时执行恢复操作。
禁用mirror备份时,如果segment实例失败,系统将会自动关闭。管理员需要手动恢复所有失败的segment。
检测和管理失败的segment
使用工具命令查看
启用mirror备份后,当primary segment发生故障时,Greenplum会自动故障转移到mirror segment。如果每个数据部分所在的segment实例都是在线的,则用户可能无法意识到segment已经出现故障。如果在发生故障时正在进行事务,则正在进行的事务将回滚并在重新配置的segment集上自动重新启动。