
合 PG中使用pg_basebackup实现时间点恢复( Point-in-Time Recovery (PITR))
Tags: PG备份恢复PITR不完全恢复基于时间点的恢复pg_basebackup
- pg_basebackup备份工具简介
- PITR简介
- 1、什么是PITR ?
- 2、什么是基础备份?怎么获取基础备份?
- 3、pg_start_backup做了什么?
- 4、backup_label文件的内容和作用什么?
- 5、此时你可能有疑问,为什么checkpoint的检查点的位置保存在了backup_label,而不是我们已知的pg_control里?
- 6、pg_stop_backup做了什么?
- 7、什么是数据库归档?
- 8、怎么开启归档?
- 9、怎么做PITR(按时间点恢复)?
- 10、PITR的工作流程?
- 11、PITR与正常的数据库恢复有何不同?
- 12、什么是时间线?什么时间线历史文件?
- 13、PITR有哪些参数可以配置?
- 14、PITR类型有哪些?
- 1、基于命名还原点恢复
- 2、基于 recovery_target_name
- 3、基于 recovery_target_xid 恢复方式
- 4、基于 time 恢复方式
- 示例:按照recovery_target_time恢复
- 配置归档
- 做基础备份
- 做增量数据
- 数据库故障
- 不完全恢复到表tl1_t2
- 创建recovery.signal
- 修改postgresql.auto.conf文件
- 启动数据库并验证数据
- 继续增量恢复
- 恢复到RW状态
- 在timeline2回退到tl1_t1表
- 在timeline3恢复到tl2_t1表
- 总结
- 参考
pg_basebackup备份工具简介
参考:https://www.dbaup.com/pg_basebackupbubeifentemporary-tablehe-unlogged-table.html
该备份工具自动执行 pg_start_backup()和 pg_stop_backup()函数,而且备份速度和数据都比手动的备份快。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | 1、 数据库处于归档模式 2、 备份: a) 产生压缩的 tar 包,-Ft 参数指定: pg_basebackup -D bk1 -Ft -z -P 此备份花的时间比较长,但是节省空间。 b) 产生跟源文件一样的格式,即原样格式,-Fp 参数指定: pg_basebackup -D bk2 -Fp -P 此备份方式很快,但是不节省空间。 3、 恢复: a) 关闭数据库或者 kill 服务器主进程模拟主机断电 pg_ctl stop b) 删除 data 目录下所有的文件,(如果是删除这个 data 目录,则下一次创建该目录时要求该目录的权限是 750,否则启动数据库时会报错): rm –rf $PGDATA/* c) 使用 tar 包进行恢复: tar -zvxf bk1/base.tar.gz -C /usr/local/pg12.2/data tar -zvxf bk1/pw_wal.tar.gz -C /usr/local/pg12.2/data/pg_wal d)或者使用原样文件备份进行恢复: cp –rf bk2/* $PGDATA e)在 postgres.conf 文件中添加如下 2 行: restore_command = 'cp /home/postgres/arch/%f %p' recovery_target_timeline = 'latest' f) 在$PGDATA 目录下 touch 一个空文件,告诉 pg 需要做 recovery: touch recovery.signal g) 启动数据库: pg_ctl start h) 登录数据库,执行函数(否则 pg 数据库处于只读状态): select pg_wal_replay_resume(); g)验证数据的完整性: testdb=# select count(*) from t1; count 524288 |
注意:
把数据库文件转储出来后,在启动数据库前 postgresql.conf 一定要添加恢复参数,否则只恢复到备份的时间点。
经过测试,第一次恢复后,数据库能够恢复到最新状态,t1 表的数据能够恢复到归档的最后位置。对数据库进行操作,切换几个日志后,再用之前的备份对数据库进行恢复,结果能够恢复到最新的状态,能够自动应用归档,此恢复方式比 mysql 要智能。
如果当前的日志丢失,pg 实际上做的是不完全恢复,但是恢复的时候没有提示,而且不需要显式进行 recovery,在启动数据库的时候自动运行,类似 oracle 的实例恢复。
PITR简介
1、什么是PITR ?
PITR: 全称是Point-In-Time-Recover (时间点恢复),是PG从8.0版本开始引入的一个特性,该特性可以使用基础备份和连续归档日志将数据库集群恢复到任意时间点。
2、什么是基础备份?怎么获取基础备份?
在pg中,也是从8.0版本中引入了在线物理全备份,运行中的整个数据库集群的快照(即物理备份数据)被称为基础备份。
在pg中可以由两种方法获取基础备份:
- 使用系统low-level函数:pg_start_backup、pg_stop_backup以及一些shell命令(如cp、tar、rsync等)。
- 使用pg_basebackup工具
3、pg_start_backup做了什么?
pg_start_backup和pg_stop_backup命令定义见这里:
src/backend/access/transam/xlogfuncs.c
链接:https://github.com/postgres/postgres/blob/master/src/backend/access/transam/xlogfuncs.c
pg_start_backup()是一个用来启动基本备份的函数。它是PostgreSQL 8.0中引入的原始物理备份API的一部分。
pg_start_backup主要执行以下几个操作:
- 强制服务器进入全页写模式(即使你设置了full_page_writes=off)。
- 执行checkpoint(我在前面checkpoint的文章中提过,数据库恢复的过程需要从一个REDO位置开始,所以pg_start_backup需要做checkpoint来创建一个REDO点)。
- 创建一个backup_label文件。
4、backup_label文件的内容和作用什么?
一个backup_label示例:
1 2 3 4 5 6 | START WAL LOCATION: 0/9000028 (file 000000010000000000000009) CHECKPOINT LOCATION: 0/9000060 BACKUP METHOD: pg_start_backup BACKUP FROM: master START TIME: 2021-5-10 11:45:19 GMT LABEL: Weekly Backup |
其中:
CHECKPOINT LOCATION: 这是该函数创建的检查点被记录的LSN位置。当使用这个基础备份恢复数据库时,PostgreSQL从backup_label文件中获取“CHECKPOINT LOCATION”,并开始恢复过程。
BACKUP METHOD: 标示用于进行基础备份的方法(pg_start_backup或pg_basebackup)。
START TIME: 执行pg_start_backup时的时间戳。
LABEL: 这是在调用pg_start_backup(LABEL)中指定的标签。
5、此时你可能有疑问,为什么checkpoint的检查点的位置保存在了backup_label,而不是我们已知的pg_control里?
因为数据库的备份时间可能很长的,期间可能会多次执行常规checkpoint,如果放在pg_control里,那这个位置就可能会常规checkpoint被覆盖了。
6、pg_stop_backup做了什么?
pg_stop_backup主要完成以下工作:
如果pg_start_backup强制打开了full_page_write,pg_stop_backup将会将其重置为非全页写模式。
创建备份历史文件(timeline.hostory)。
删除backup_label文件。(注:从基础备份恢复时,需要backup_label文件,其被复制到归档目录之后,在原始数据库集中就不再需要了。)
7、什么是数据库归档?
一般情况下,PostgreSQL数据库将wal文件保存在$PGDATA的pg_wal下。但是这些wal文件可能会被回收。为了避免这种情况,我们可以将wal文件的副本保存在除$PGDATA之外的单独目录中。在PG中,将wal文件复制到其他位置被称为归档(让服务器读取wal文件并应用它称为恢复)。
8、怎么开启归档?
在pg中开启归档,依赖三个配置:archive_mode、archive_command和wal_level
archive_mode:表示是否要启用wal归档。
archive_command:指定如何归档。此选项接受shell命令或shell脚本。
wal_level:可选项:
Minimal:只添加崩溃服务或立即关闭所需的信息。它不能用于复制或归档目的。
Replica: 表示wal将有足够的信息用于wal归档和复制。
Logical:添加逻辑复制所需的信息。
一个配置示例:
1 2 3 | archive_mode = on archive_command = 'cp %p /path/to//archive_dir/%f' wal_level = replica |
其中:
%p: 被替换为WAL文件的路径名。
%f: 被替换为WAL文件的文件名。
9、怎么做PITR(按时间点恢复)?
PITR工作需要两个重要的先决条件:
基础备份的可用性。
连续归档日志。
有了这两个为前提,然后需要配置restore_command和recovery_target选项。
示例:
1 2 3 4 5 | # Place archive logs under /mnt/server/archivedir directory. restore_command = 'cp /mnt/server/archivedir/%f %p' recovery_target_time = "2021-5-10 12:05 GMT" |
restore_command:指定从何处查找要在该服务器上重播的WAL文件。这个命令接受与archive_command相同的占位符。
recovery_target_time:该选项告诉服务器何时停止恢复或重放进程。一旦到达给定的时间戳,进程就会停止。
注:pg11.0以及之前,这两个参数在recovery.conf中进行设置。pg12.0以及之后在postgresql.conf中进行配置(12.0已经废除了recovery.conf,所有与recovery相关的参数都移到了postgresql.conf中)。除此之后,在版本12或更高版本中,当进行恢复时,还需要创建一个名为recovery.signal的空文件。
10、PITR的工作流程?
(1)PostgreSQL从backup_label文件中读取CHECKPOINT LOCATION的值,即REDO点。
(2) PostgreSQL从recovery.conf(版本11或更早)或PostgreSQL .conf(版本12或更高)中读取restore_command和recovery_target_time参数值。
(3) PostgreSQL从REDO点开始重放WAL数据,通过参数resotere_command,从归档日志中读取WAL数据,将归档日志从归档区复制到临时区。(临时区域中复制的日志文件使用后会被删除。)
注:如果没有配置recovery_target_time,PG将重放日志直到归档结束。
(4)恢复过程结束后,生成时间线历史文件,如00000002.History,该文件被创建在pg_xlog子目录(在版本10或更高版本,pg_wal子目录),如果启用了归档日志特性,归档目录下也会创建相同的命名文件。
11、PITR与正常的数据库恢复有何不同?
正常复模式是从base目录下的pg_wal目录中获取wal文件,而PITR模式是从archive_command中设置的归档目录中获取。
正常恢复模式从pg_control文件获取检查点位置,而PITR模式从backup_label文件中获取检查点位置。
12、什么是时间线?什么时间线历史文件?
PG中的时间线用于区分原始的数据库集群和恢复后的数据库集群,是PITR的核心概念。
每个数据库集群分配一个单独的timelineId。initdb实用程序创建的原始数据库集群的timelineId为1。当数据库集群恢复时,timelineId将增加1。
当我们启动PostgreSQL服务器时,初始时间线被设置为1,从pg_start_backup创建的REDO点到恢复目标,在归档日志中回放WAL数据,然后,一个新的timelineId 2被分配给恢复的数据库集,PostgreSQL将在新的时间线2上运行。如下图所示:
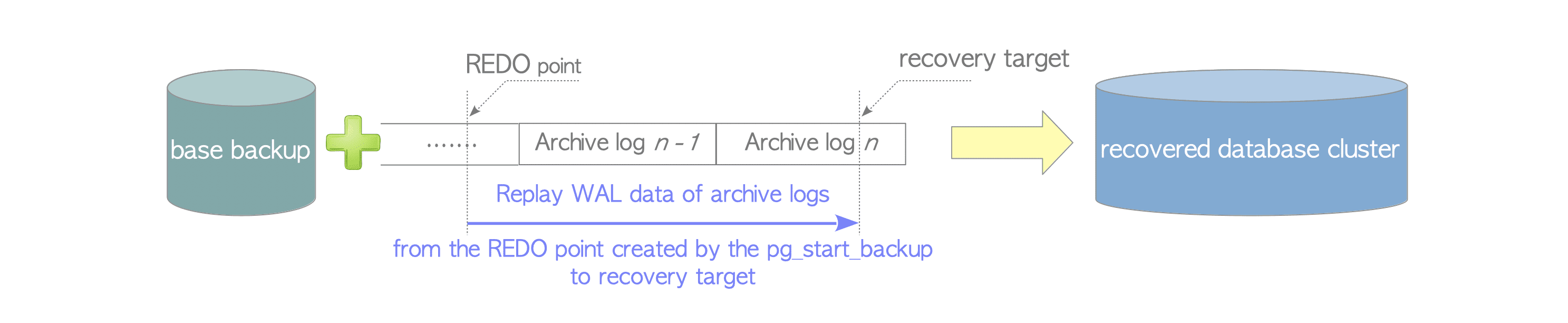
前面提到,当一个PITR进程完成时,会生时间线历史文件。这个文件的命名规则为:


麦老师请教一下,恢复后数据是有了
但select pg_is_in_recovery();结果是t,
select pg_wal_replay_resume();执行了表也还是只读状态,
recovery.signal也还在
不知道是不是我漏掉什么操作?还是哪个步骤搞错?
那你得看告警日志有没有啥输出,告警日志很重要