合 《PostgreSQL技术内幕——原理探索》第七章 堆内元组与仅索引扫描
Tags: PGPostgreSQL翻译《PostgreSQL技术内幕——原理探索》
本章中介绍两个和索引扫描有关的特性—— 堆内元组(heap only tuple, HOT)和仅索引扫描(index-only scan) 。
7.1 堆内元组(HOT)
在8.3版本中实现的HOT特性,使得更新行的时候,可以将新行放置在老行所处的同一个数据页中,从而高效地利用索引与表的数据页;HOT特性减少了不必要的清理过程。
在源码的README.HOT中有关于HOT的详细介绍,本章只是简短的介绍HOT。首先,7.1.1节描述了在没有HOT特性的时候,更新一行是怎样一个过程,以阐明要解决的问题。接下来,在7.1.2中将介绍HOT做了什么。
7.1.1 没有HOT时的行更新
假设表tbl有两个列:id和data;id是tbl的主键。
1 2 3 4 5 6 7 8 | testdb=# \d tbl Table "public.tbl" Column | Type | Collation | Nullable | Default --------+---------+-----------+----------+--------- id | integer | | not null | data | text | | | Indexes: "tbl_pkey" PRIMARY KEY, btree (id) |
表tbl有1000条元组;最后一个元组的id是1000,存储在第五个数据页中。最后一条元组被相应的索引元组所引用,索引元组的key是1000,且tid是(5,1),如图7.1(a)所示。
图 7.1 没有HOT的行更新
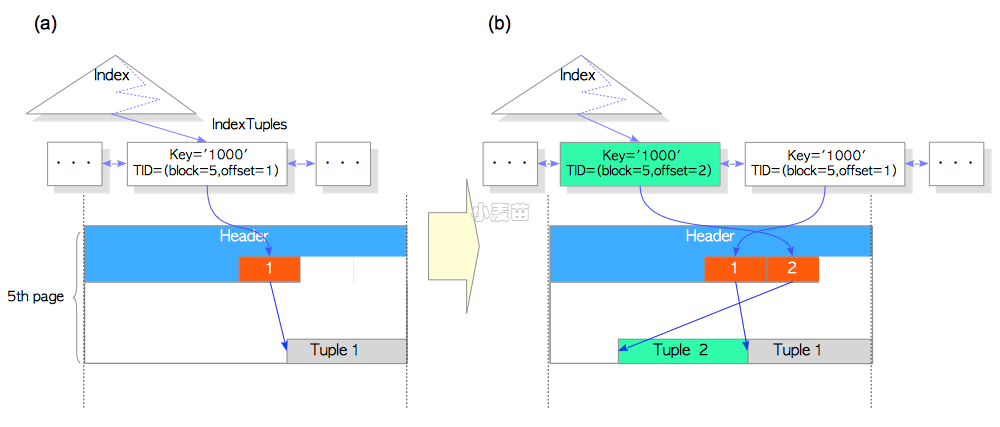
我们考虑一下,没有HOT特性时,最后一个元组是如何更新的。
1 | testdb=# UPDATE tbl SET data = 'B' WHERE id = 1000; |
在该场景中,PostgreSQL不仅要插入一条新的表元组,还需要在索引页中插入新的索引元组,如图7.1(b)所示。索引元组的插入消耗了索引页的空间,而且索引元组的插入和清理都是开销很大的操作。HOT的目的,就是降低这种影响。
7.1.2 HOT如何工作
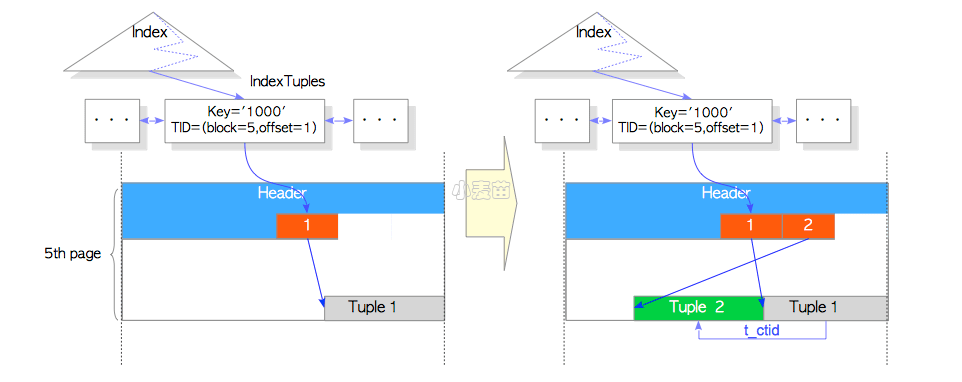
当使用HOT特性更新行时,如果被更新的元组存储在老元组所在的页面中,PostgreSQL就不会再插入相应的索引元组,而是分别设置新元组的HEAP_ONLY_TUPLE标记位与老元组的HEAP_HOT_UPDATED标记位,两个标记位都保存在元组的t_informask2字段中。如图7.2和7.3所示;
图7.2 HOT的行更新
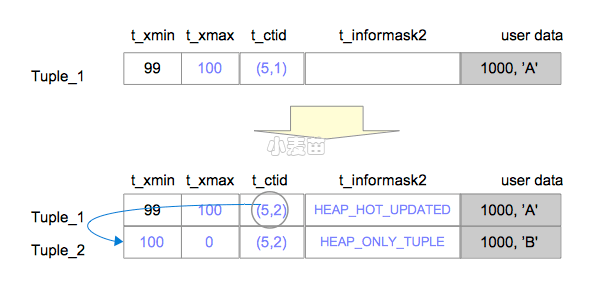
比如在这个例子中,Tuple_1和Tuple_2分别被设置成HEAP_HOT_UPDATED和HEAP_ONLY_TUPLE。
另外,在修剪(pruning)和碎片整理(defragmentation)处理过程中,都会使用下面介绍的HEAP_HOT_UPDATED和HEAP_ONLY_TUPLE标记位。
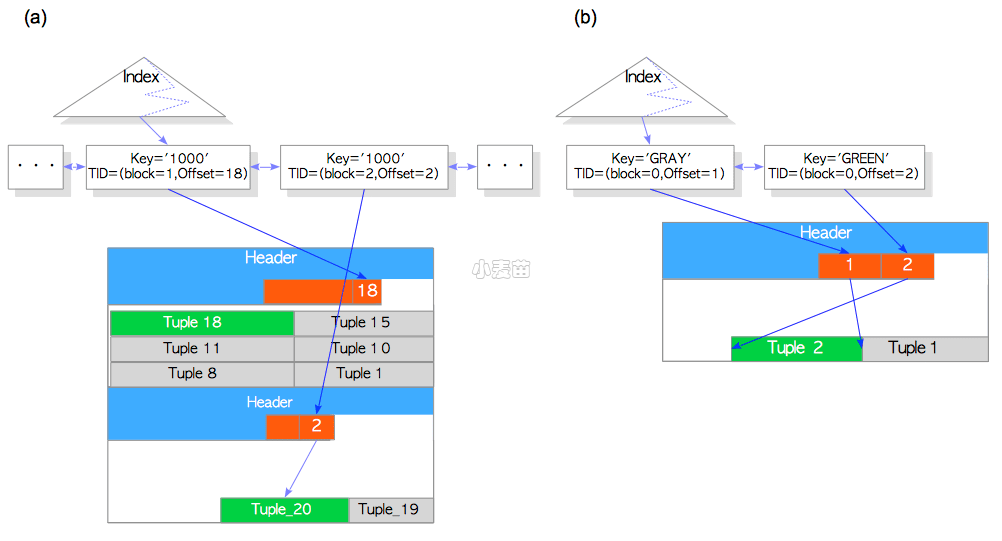
接下来会介绍,当基于HOT更新一个元组后,PostgreSQL是如何在索引扫描中访问这些被HOT更新的元组的,如图7.4(a)所示。
图7.4 行指针修剪

- 找到指向目标数据元组的索引元组
- 按所获索引元组指向的位置访问行指针数组,找到行指针
1 - 读取
Tuple_1 - 经由
Tuple_1的t_ctid字段,读取Tuple_2。
在这种情况下,PostgreSQL会读取两条元组,Tuple_1和Tuple_2,并通过第5章所述的并发控制机制来判断哪条元组是可见的;但如果数据页中的死元组(dead tuple)已经被清理了,那就有问题了。比如在图7.4(a)中,如果Tuple_1由于是死元组而被清理了,就无法通过索引访问Tuple_2了。
为了解决这个问题,PostgreSQL会在合适的时候进行行指针重定向:将指向老元组的行指针重新指向新元组的行指针。在PostgreSQL中,这个过程称为修剪(pruning)。图7.4(b)说明了PostgreSQL在修剪之后如何访问更新的元组。
- 找到索引元组
- 通过索引元组,找到行指针
[1] - 通过重定向的行指针
[1],找到行指针[2]; - 通过行指针
[2],读取Tuple_2
可能的话,剪枝任何时候都有可能会发生,比如 SELECT ,UPDATE, INSERT ,DELETE这类SQL命令执行的时候,确切的执行时机不会在本章中描述,因为它太复杂了。细节可以在README.HOT文件中找到。
在PostgreSQL执行剪枝时,如果可能,会挑选合适的时机来清理死元组。在PostgreSQL中这种操作称为碎片整理(defragmentation),图7.5中描述了HOT中的碎片整理过程。
图 7.5 死元组的碎片整理
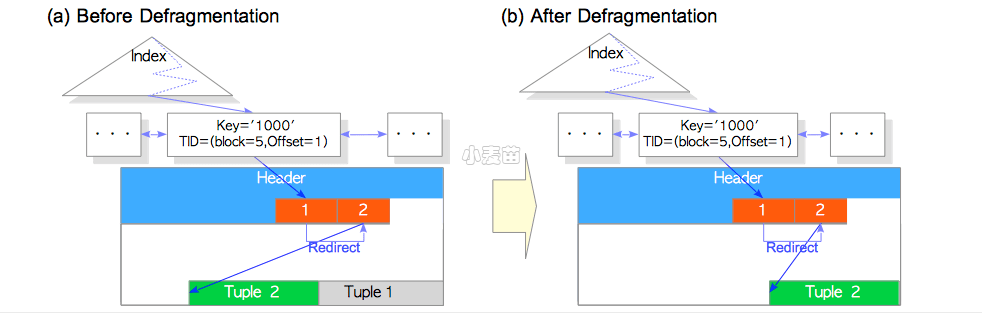
需要注意的是,因为碎片整理的工作并不涉及到索引元组的移除,因此碎片整理比起常规的清理开销要小得多。
因此,HOT特性降低了索引和表的空间消耗,同样减少了清理过程需要处理的元组数量。由于减少了更新操作需要插入的索引元组数量,并减小了清理操作需要处理的元组数量,HOT对于性能提高有良好的促进作用。
HOT不可用的场景
为了清晰地理解HOT的工作,这里介绍一些HOT不可用的场景。
- 当更新的元组在其他的页面时,即和老元组在不在同一个数据页中时,指向该元组的索引元组也会被添加至索引页中,如图7.6(a)所示。
- 当索引的键更新时,会在索引页中插入一条新的索引元组,如图7.6(b)所示。
图7.6 HOT不适用的情况
pg_stat_all_tables视图提供了每个表的统计信息视图,也可以参考这个扩展。
7.2 仅索引扫描
当SELECT语句的所有的目标列都在索引键中时,为了减少I/O代价,仅索引扫描(Index-Only Scan)(又叫仅索引访问)会直接使用索引中的键值。所有商业关系型数据库中都提供这个技术,比如DB2和Oracle。PostgreSQL在9.2版本中引入这个特性。
接下来我们会基于一个特殊的例子,介绍PostgreSQL中仅索引扫描的工作过程。
首先是关于这个例子的假设:
表定义
我们有一个
tbl表,其定义如下所示:本人提供Oracle(OCP、OCM)、MySQL(OCP)、PostgreSQL(PGCA、PGCE、PGCM)等数据库的培训和考证业务,私聊QQ646634621或微信dbaup66,谢谢!