合 Cloudberry Database(CBDB)介绍
Tags: GreenPlum整理自官网MPPCloudberry Database(CBDB)
CBDB简介
Cloudberry Database(可简称为“CBDB”或“CloudberryDB”)是面向分析和 AI 场景打造的下一代统一型开源数据库,搭载了 PostgreSQL 14.4 内核,兼容 PostgreSQL 和 Greenplum Database 生态,采用 Apache License 2.0 许可协议,由北京酷克数据HashData科技有限公司开发,目前源码已公开。
️GitHub 地址:https://github.com/cloudberrydb/cloudberrydb
️官网主页:https://cloudberrydb.org/
官方文档:https://cloudberrydb.org/zh/docs/
| 厂商 | 酷克数据 |
|---|---|
| 官网 | https://cloudberrydb.org/zh |
| 微信公众号 | HashData |
| 总部城市 | 北京 |
2023年7月14日,Cloudberry Database v1.0.0 发布。
产品特性
多场景高效查询
- Cloudberry Database 支持用户在大数据分析环境和分布式环境下进行有效的查询:
- 大数据分析环境:Cloudberry Database 使用内置的 PostgreSQL 的优化器,可更好地支持分布式环境。这意味着它能够在处理大数据分析任务时产生更高效的查询计划。
- 分布式环境:采用开源优化器 GPORCA 优化器,经过特定适配,可满足分布式环境下的查询优化需求。
- 提供分区静态和动态减裁、聚集下推、连接过滤等技术,以帮助用户获得快速、精确的查询结果。
- 提供了基于规则的查询优化手段和基于代价的查询优化手段,帮助用户生成更高效的查询执行计划。
多态数据存储
Cloudberry Database 支持多种不同的存储格式,包括 Heap 存储、AO 行存储、AOCS 列存储,用于不同的应用场景。同时,Cloudberry Database 还支持分区表,用户可以按照某个条件定义表的分区方式,查询时根据查询条件自动过滤不需要查询的子表,提高数据的查询效率。
多层次的数据安全防护
Cloudberry Database 加强对用户数据的保护,支持函数加密解密,以及透明数据加密和解密。透明数据加密解密指在用户不感知的情况下,加密解密过程由 Cloudberry Database 内核完成,目前可以支持的数据格式包括 Heap 表、AO 行存储、AOCS 列存储。同时加密算法除了常用的 AES 等算法以外,还特别支持国密算法,用户可以方便的扩展自己的算法到透明数据加密中。
数据加载
Cloudberry Database 提供了一系列高效且灵活的数据加载解决方案,以满足各种数据处理需求,包括并行化和持久化的数据加载、支持灵活的数据源和文件格式、集成多款 ETL 工具、支持流式数据加载、提供高性能的数据访问。
多层容错
Cloudberry Database 为了确保数据安全和服务的连续性,采取了数据页面、Checksum、镜像节点配置、控制节点备份的多级容错机制。
丰富的数据分析支持
Cloudberry Database 提供了强大的数据分析功能,使得数据处理、查询和分析变得更加高效,满足各类复杂的数据处理、分析和查询需求。
灵活的工作负载管理
Cloudberry Database 提供了全面的工作负载管理功能,旨在有效地利用和优化数据库资源,以确保高效、稳定的运行。其工作负载管理主要包括连接级别管理、会话级别管理、SQL 级别管理三个层次的控制。
多种兼容性
Cloudberry Database 的兼容性表现在 SQL 语法、组件、工具和程序、硬件平台和操作系统等多个方面,这使得它能够灵活应对各种工具、平台和语言。
架构介绍
在大多数情况下,Cloudberry Database 在 SQL 支持、功能、配置选项和最终用户功能方面与 PostgreSQL 非常相似。数据库用户与 Cloudberry Database 数据库的交互体验,非常接近与单机 PostgreSQL 进行交互。
Cloudberry Database 采用 MPP 架构技术,通过在多个服务器或主机之间分配数据和处理工作负载来存储和处理大量数据。
MPP 也称为大规模并行处理架构,是指具有多台主机的系统,这些主机协作执行同一操作。每台主机都有自己的处理器、内存、磁盘、网络资源和操作系统。Cloudberry Database使用这种高性能的系统架构来分配海量数据的负载,并且可以并行使用系统的所有资源来处理查询。
从用户角度来看,Cloudberry Database 是一个完备的关系数据库管理系统 (RDBMS)。从物理层面来看,它内含多个 PostgreSQL 实例。为了实现多个独立 PostgreSQL 实例的分工和合作,Cloudberry Database 在不同层面对数据存储、计算、通信和管理进行了分布式集群化处理。Cloudberry Database 虽然是一个集群,然而对用户而言,它封装了所有分布式的细节,为用户提供了单个逻辑数据库。这种封装极大地解放了开发人员和运维人员的工作。
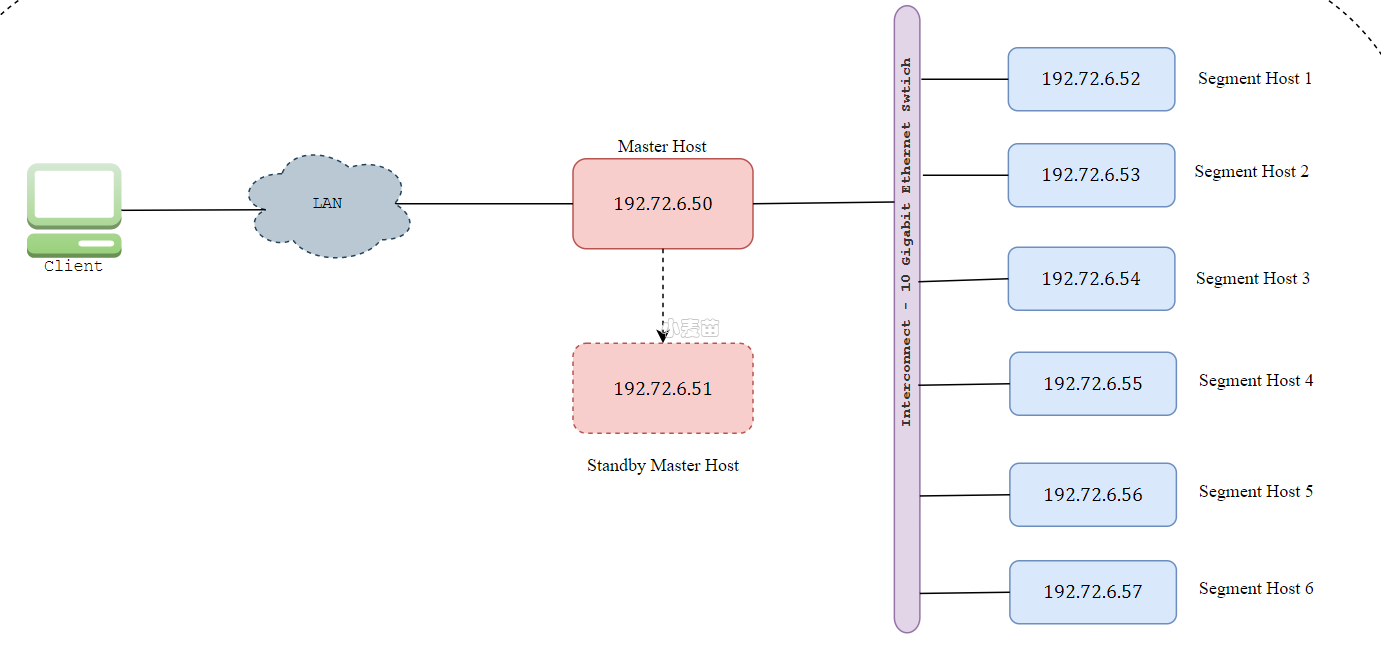
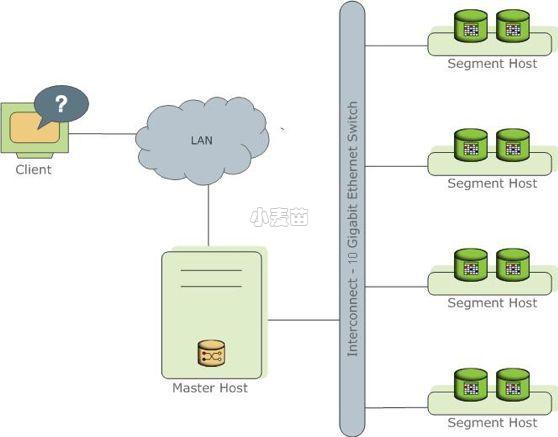
Cloudberry Database 架构图如下所示:
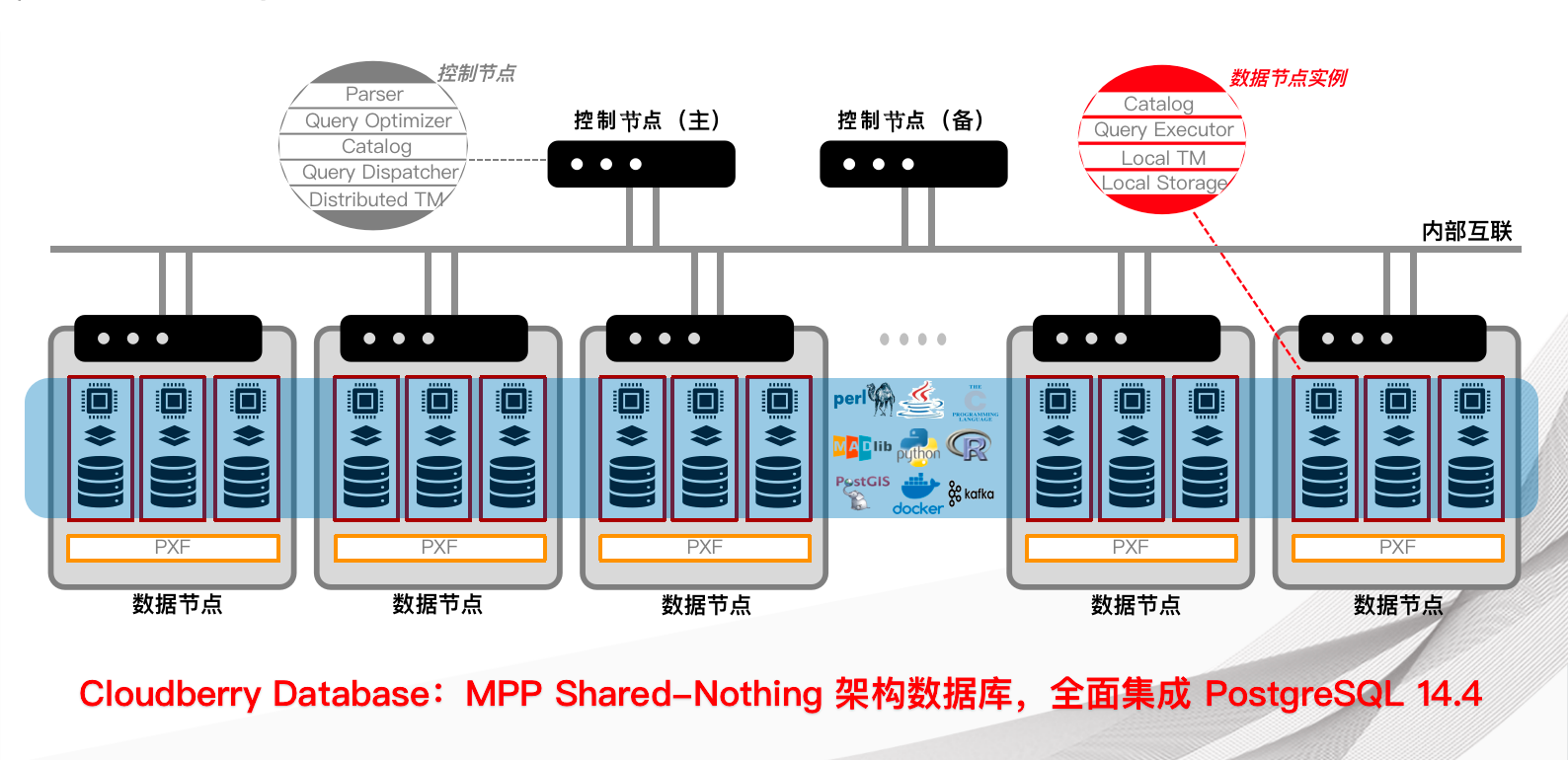
控制节点 (Coordinator) 是 Cloudberry Database 数据库系统的入口,它接受客户端连接和 SQL 查询,并将工作分配给数据节点实例。用户与 Cloudberry Database 进行交互,使用客户端程序(例如 psql)或应用程序编程接口(API)(例如 JDBC、ODBC 或 libpq PostgreSQL C API)连接到控制节点。
- 控制节点是全局系统目录所在的位置,全局系统目录是一组系统表,其中包含有关 Cloudberry Database 数据库系统本身的元数据。
- 控制节点不包含任何用户数据,数据只保存在数据节点实例上。
- 控制节点对客户端连接进行身份验证,处理传入的 SQL 命令,在数据节点之间分配工作负载,协调每个数据节点返回的结果,并将最终结果呈现给客户端程序。
- Cloudberry Database 使用预写日志记录(WAL)进行控制节点/Standby 镜像。在基于 WAL 的日志记录中,所有修改都将在写入磁盘之前先写日志,以确保任何进程内操作的数据完整性。
数据节点 (Segment) 实例是独立的 Postgres 进程,每个数据节点存储一部分数据并执行相应部分查询。当用户通过控制节点连接到数据库并提交查询请求时,会在每个数据节点创建进程来处理查询。用户定义的表及其索引分布在 Cloudberry Database 中的所有可用数据节点中,每个数据节点都包含数据的不同部分,不同部分数据处理的进程在相应的数据节点中运行。用户通过控制节点与数据节点进行交互,数据节点在称为数据节点主机的服务器上运行。
本人提供Oracle(OCP、OCM)、MySQL(OCP)、PostgreSQL(PGCA、PGCE、PGCM)等数据库的培训和考证业务,私聊QQ646634621或微信dbaup66,谢谢!